Toujours dans l’optique de documenter le plus proprement et intelligemment possible le projet Folkopedia, j’ai voulu m’occuper de la définition de l’API concernant Schema Definer.
Tout d’abord j’ai pensé un Google Sheet/Doc, mais, bien que fonctionnel, ce n’est pas le plus sexy ni adapté en terme de documentation.
Il existe des solutions comme ApiDoc, Swager, etc. et RAML sur lequel je me suis arrêté. L’idée n’est pas d’avoir un générateur d’API mais un moyen de documenter. Donc un fichier structurant me permettant d’avoir une sortie sous forme de documentation, ici un HTML dynamique.
Comme si c’était notre credo, la documentation stricte du site de base raml.org n’est pas tout à fait bonne, peut-être une confusion entre la v0.8 et la 1.0. Du coup, belotte et rebelotte, vous aurez à croiser quelques liens.
Dans mon cas je suis sous Visual Studio Code pour éditer mon fichier raml. Il y a l’extension RAML 3.0.1 de blzjns nécessitant raml2html à installer en console (besoin de node) via la commande :
npm i -g raml2html
Pour ma part le preview interne ne donne pas un résultat idéal, je vous conseil donc de compiler vous même votre HTML avec la commande :
raml2html api.raml > api.html
Du coup j’en profite pour vous montrer un exemple fonctionnel et pas fini.
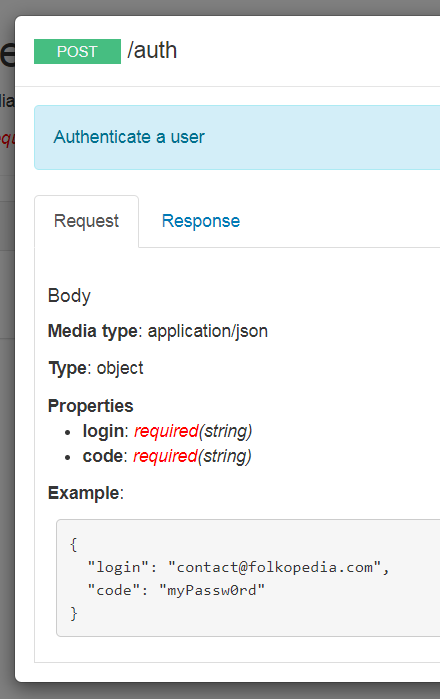
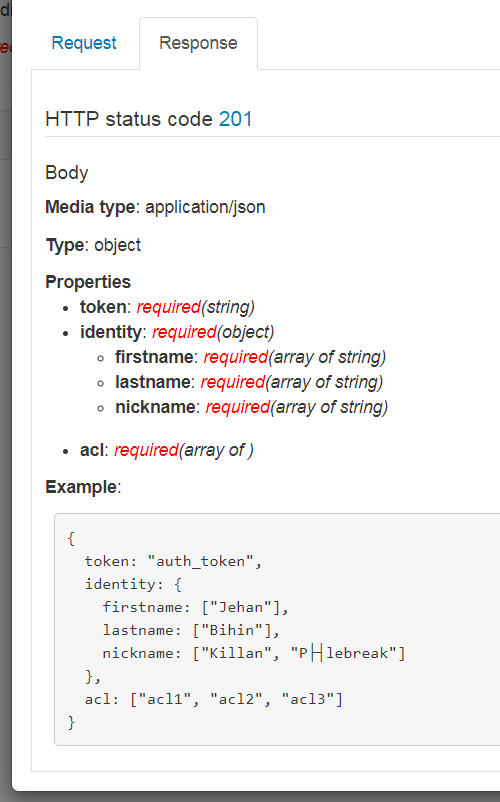
Ce qui une fois compilé nous donnera ce type de rendu plutôt sympa.
Oui c’est en UTF-8 mais ça n’a pas bien géré le ô :s
Tout doucement une solution complète se met en place et ce n’est pas faute de l’avoir simplifié à la base. Tant mieux ça fait de l’expérience ! Et de belles prises de têtes en tête à tête ^^. Y a du boulot…
Je pars du principe que vous avez votre serveur web déjà prêt, même si les lignes de commandes sont assez complète. Mon stack est Apache et MariaDB sur une Debian 9 (Stretch).
Ne pas oublier update/upgrade avant.
svn co https://svn.redmine.org/redmine/branches/4.0-stable redmine-4.0
cd redmine-4.0/
cp config/database.yml.example config/database.yml
vim config/database.yml
Modifier la conf de production selon vos paramètres. J’ai utilisé PHPMyAdmin, créé un user avec sa db attachée et un mot de passe fort (ne le perdez pas ^^).
apt install ruby-full
Pas sûr que ça ait réellement servi.
apt install imagemagick
gem install bundler
bundle install --without development test
La première ligne ça prend tout même ce qu’on a déjà. L’avant-dernière ligne c’est du fait qu’il a besoin du connecteur MySQL, donc le client (et en dev aussi). Puis on relance l’installation, et ça fonctionne.
On pourrait, imaginons, en gardant la partie SVN checkout et conf DB, synthétiser sous la forme :
Tu es Schema Definer, et sur cette base je bâtirai mon réseau.
Nous avons donc un Lumen frais, et la première étape est d’intégrer le schéma de la base de données, tel que défini et validé précédemment.
J’ai opté pour l’usage d’Eloquent (ORM), ce qui n’est pas aussi aisé car la documentation est fort légère et nous oblige souvent à consulter celle de Laravel. À noter qu’il y a des différences au niveau d’Artisan, l’aide générateur, celui de Lumen est beaucoup moins fourni, mais une fois qu’on le sait, ce n’est pas un obstacle.
Le fait de passer par un ORM alors que vous avez dessiné votre schéma à l’ancienne peut s’avérer perturbant quand vous n’avez pas l’habitude (de l’ORM). Tous les projets ne l’utilisent pas, et il est rare que ça soit votre rôle ^^. Bref j’ai galéré, mais c’était amusant et instructif.
Nous avons donc notre schéma sous forme d’objet, au grand complet et avec les relations entre nos modèles. Artisan s’occupe de faire la ‘migration’ et on peut constater via n’importe quel système (j’utilise MySQL Workbench) que nos tables sont là, avec index et relations. Parfait 🙂 Évidemment je simplifie un peu, la gestion des relations est le moins évident et j’ai été amené à corriger cela par la suite.
Ce qui nous amène à la question de la garantie ! Il est plus que primordial de pouvoir faire confiance à ce que l’on a conçus. Là encore une fois nous sommes aidé, Lumen vient avec PHPUnit, que j’aime bien, ça tombe à pic. Cependant, comme pour Eloquent, la documentation spécifique aux tests, et aux tests de bases de données, n’est ni évidente, ni consolidée.
J’ai pris l’idée initiale de démarrer mes tests par un remplissage de données tests, quelque chose de maîtrisé, cas d’école, idéal pour valider l’ensemble du schéma. Cependant, la manière ne l’était pas. Je vous conseille donc de faire un ‘Seeder’ et de l’appeler de manière nommée pour vos tests spécifiques
On supprime tout, on fait la migration et donc on met la base de données dans l’état à jour (de son schéma, aucune données à cet instant) puis on ‘seed’, on rempli des données, en précisant le ‘seeder’ que l’on veut et hop on lance l’exécution des tests, eux aussi nommés.
Ceci nous permet par exemple de déployer une version et de tester exactement ce que l’on veut, le schéma, un module, etc. Et ceci ouvre la porte aux automations et intégrations continues :).
Revenons aux tests, j’en ai écrit 45 🙂 oui monsieur/madame. 3 initiaux et 42 hier (oui c’est important !!! na d’abord). Ceux-ci couvrent l’ensemble des tables/modèles et de leur liaisons, y compris les attributs personnalisés et liens supplémentaires que j’ai écris en prévision.
Comme dit en début d’articles j’ai dû corriger, c’est grâce à ces tests que cela a été mis en évidence. C’est fait pour et en plus ça fonctionne. C’est beau :).
La base est saine, testée et donc nous je vais pouvoir débuter les fonctions de l’API.
À ce sujet, petite digression, je vais tenter une approche TDD, donc écrire les tests avant de coder, que je n’ai jamais eu l’occasion de vivre, ce qui peut-être une bonne occasion et expérience. De plus, après une longue hésitation, je vais tenter une méthode SCRUM également, même si je suis seul, je peux tenter quelques points, comme par exemple une liste de ‘stories’ (histoires) tel quel : en tant qu’utilisateur je souhaite me connecter pour éditer mon profil ou encore en tant qu’application je souhaite avoir toutes les entités liées pour les proposer à l’utilisateur.
Comme toujours affaire à suivre, mais les progrès sont là.
Suite de l’article précédent sur le même sujet, mais cette fois de manière plus technique. Nous voilà déjà 7 mois plus tard… Rien n’a été fait si ce n’est ce mois de Mai, du coup décortiquons.
Comme dit précédemment, c’est un gros projet, ambitieux et novateurs à différentes échelles, et donc accompagnés de complexités et difficultés pour le démarrer/réaliser. Oui OK je me cherche quelques excuses mais elles sont véritables.
« Mais tout vient à point à qui sait attendre » un sage aurait-il dit; et c’est effectivement le cas : l’illumination du premier jalon. Je vais donc vous parler de ce qui porte le nom, actuellement, de Schema Definer ou le définisseur de schéma.
« Mais qu’est-ce donc ? » demande la foule tel un 42 en réponse d’une longue attente. Tout simplement notre première étape, car vous n’imaginiez quand même pas que le site pouvait se gérer sans structure ?
Aussi permissif le site, en objectif, sera; autant il lui faut une mécanique de définitions pour vous proposer celle-ci. Quelle belle phrase.
Récapitulons après ce blabla. Jusque là nous avons défini un schéma de base de données, donc un moyen de stocker de l’informations organisées selon une définition. Cette dernière décrit un ensemble de tables représentant notre infinie possibilité à décrire tout système folklorique.
Ça c’était il y a +2 ans, selon les idées sur les ontologies. Ensuite j’ai cherché le stack ultime du web de demain… Ok sans succès, on va partir sur un Angular/Lumen pour débuter. Mais je ne désespère pas de trouver le design du web de demain quand on attaquera le front (partie visible et utilisable).
Déjà le fait d’avoir simplifié et décidé du stack, ça soulage, beaucoup même. Je vous recommande Homestead via Vagrant pour démarrer avec simplicité.
Revenons à nos moutons après cette digression. On a de quoi stocker de l’information brute qui n’aura du sens que si on lui en donne, c’est le rôle du Schema Definer. Le schéma sémantique sur le schéma structurelle (stockage).
Si je stock 36, rien ne me dit que c’est mon age, sauf si une définition l’indique au système.
Là je vous ai perdu, entre logique effrayante et explications à rallonge.
Comme dit nous avons un système de stockage différent de ce que l’on a habituellement (relationnel, non relationnel structuré, …) où la conception contient le sens des données. Mais nous, non. Notre mécanique retiendra des nombres et chaînes de textes reliées entre elles, de manière relationnelle.
OK, c’est quoi ce schéma ? Tout simplement la définition de ce que l’on veut encoder sur Folkopedia : une personne, un groupe, un document, …
Pour faire simple, en expliquant sommairement la mécanique triplet RDF, vous aurez un objet/entité (virtuel), qui a des propriétés avec des valeurs.
De manière appliquée : je suis l’instance d’une Personne, ayant pour surnom : Killan. Le schéma précise qu’il existe une entité Personne, avec pour propriété possible un surnom qui sera de valeur texte.
La valeur pourrait être la référence d’une autre entité. Genre une entité livre peut avoir une propriété auteur qui a comme valeur la référence d’une entité personne. Etc.
Avec une table de 3 colonnes vous avez votre système, simple mais horriblement pas performant. Et on ne va pas entrer dans ces histoires-là ici. Le schéma Folkopedia est différent tout en suivant le principe et un futur système de cache fera le delta de performances. On reviendra dessus bien plus tard.
Pour revenir sur le Schema Definer, vous pouvez prendre exemple sur le site de schema.org qui est le premier objectif. Vous pouvez prendre l’entité Book (livre) comme exemple.
Pour résumer, on peut dire que le Schema Definer est une administration de la structure de données du site Folkopedia.
C’est pour ça que j’ai parlé d’Angular, il nous faut une interface pour manipuler ce schéma. Peut-être qu’un jour on exposera ce site, comme explication de la démarche scientifique, on verra, rien n’est figé actuellement. La démarche m’importe beaucoup.
Bref, là on a un Lumen installé sur un Vagrant/Homestead, tout frais, et cet articles un point de départ publique. C’est parti !
Nous y sommes, nous sommes revenu à la case départ, au même niveau qu’au moment du constat sur les performances avec les lumières. Ça compile, ça fonctionne, soupir de soulagement, joie intérieur et stress futur quand on voit ce qu’il a fallu pour en arriver là, et donc qu’il faudra arranger. Mais profitons de l’instant présent, du succès immédiat, de ce haut-fait personnel, de cette joie temporaire mais précieuse.
Profitons en pour rire un peu avec quelques captures et commentaires utiles.
Au commencement : ça fonctionne, d’apparence, bon positionnement, chaque chose à sa place, le curseur bouge, bref idéal. À savoir que les objets complexe comme le coffre ou la porte sont arrivés plus tard car il a fallu traduire vers la 3D objet par objet, et au final se rendre compte que les abstractions ne nous oblige qu’à changer la classe de laquelle on hérite, ce qui est parfait mais pose un problème de logique de conception, en sachant que le TypeScript ne permet pas les Traits, mais veut faire du Mixin auquel je m’y refuse (pas beau, pas maintenable, …).
Comme nous n’avons pas de Traits, j’ai donc été obligé de garder l’héritage, ainsi Element (en tête), devient un SpriteElement, qui à son tour sera décliné en Sprite2DElement et Sprite3DElement et chacun d’eux aura sa version Iso (Iso2DElement et Iso3DElement). La difficulté première est justement ce dupliqua de code obligé par la technique limitée du langage.
Nous avons donc un rendu, complet, chaque objets dessinés et à sa place.
Oh ? Mais que ce passe-t-il ? Ben ça c’est quand on clique sur la porte pour la fermer et que … ben ça plante. Ce qui m’a fait découvrir l’erreur total sur le principe de création des textures (sprites transformé pour WebGL) pour le rendu. En gros, la boucle JE confondais la liste des sprites et les calques de ces sprites, ce qui, vous l’aurez compris, ne fonctionne pas.
La solution n’était pas pour autant aussi trivial que cette définition de l’erreur. L’objet Texture a été transformé en héritage de Sprite, le code de création a été inclus dans cette classe, et l’usage se fait comme Iso2DElement, ce qui est assez comique, mais juste. Faire, défaire, déplacer et recommencer…
Là c’est du grand n’importe quoi ! Non seulement le Héro Squellettore ne tourne plus MAIS en plus son animation fonctionne ! Il ne s’agit donc pas d’un soucis de cache (il n’y a pas de cache en plus). Mais en plus de cela quand on clique pour interagir avec le coffre celui-ci se rend à un arbre, plus ou moins un en bas gauche (variable en plus).
Premier cas : la rotation du héro. Celui-ci est résolu par le cas précédent, la gestion des calques des Sprites, le fait d’inclure la Texture à se niveau, d’y avoir accès et de pouvoir l’appeler au moment du rendu en précisant la rotation manquante jusqu’à lors.
Le second est plus ardu : le clic droit d’interaction fait quelque chose d’incohérent et variable, et c’est surtout cette dernière qui est bizarre. Un code ne change pas tout seul, donc on a quelque chose qui ne va pas et reste silencieux. Et c’est le cas, un try-catch attrapait une erreur dans la fonction de détection de contact avec l’objet (le raycasting), il tombait en erreur sur le cache qui n’existe pas en 3D, donc dur d’évaluer si on touche ou non l’objet si notre référentiel n’existe même pas…
Là, on attaque un chantier, devoir utiliser le cache 2D pour les éléments 3D (sous-entendu les Sprites 2D dans un contexte 3D). Là encore, du fait du langage, obligé de dupliquer un bout de code pour créer le cache à dimension et dessiner, en 2D comme avant, notre objet au complet. On peut se permettre de simplifier car ni la transparence ou la luminosité ne sont utiles pour savoir si on est dessus ou non, autant optimiser. Évidemment on ne fera cette opération que si on veut tester le contact avec notre objet, ce qui ne devrait pas poser de soucis de performances, et de toutes façons on a pas trop le choix sur la technique.
L’optimisation sur la transparence a directement été mise à la racine de la méthode isTouch (détection du contact avec l’objet) pour éviter tant que possible les tests inutiles.
De plus ailleurs, au moment du rendu, on testait la transparence ET la luminosité, mais en rien la luminosité n’affecte le fait d’être affiché ou nous, du coup, j’ai changé en ne gardant que la transparence.
Le contexte du cache et l’initialisation de ce dernier ont été factorisés pour éviter le plus intelligemment possible la répétition de codes et ainsi faciliter la maintenance tout en restant flexible sur la partie variable.
Enfin, ceci ne concerne que le POC, ce que vous voyez actuellement dans les différentes captures, le coffre, qui est une source de lumière pour le moment, était inclus de base. Mais quand je fais mes rendus, pour vous présenter les résultats, je réduis ma fenêtre et donc la taille du subsetMap, et pour une fois, j’ai vu qu’il fonctionnait, en faisant aller mon Héro tout en bas, le coffre est sorti de l’écran, et… pouf ! Freeze complet, je me suis fait engueuler par le navigateur qui me demandait comment utiliser quelque chose de non disponible… :p Oups désolé, on va corriger ça et ajouter une condition ^^. Évidemment on est en POC et tout ce qui concerne les lumières est en chantier, mais ça n’empêche pas de penser à ça. Maintenant c’est fait.
Je peux vous présenter enfin la comparaison avant/après.
À gauche la version précédente en 2D, qui continue de fonctionner en tous points, et à droite la version actuelle en 2D via 3D qui a exactement le même comportement, les performances en plus.
Vous remarquerez qu’en 2D (à gauche) je n’ai pas mis le coffre en source de lumière. C’est la seule différence entre les 2 images. Les arbres sont aléatoires, ça vous l’aviez deviné si vous suivez les articles, donc différence aussi en bas au centre.
Nous voilà donc tel que nous étions il y a plus d’un mois durant les recherches de performances sur les lumières. Nous voilà donc revenu dans une situation « stable » et ainsi pouvoir explorer les 14 millions de suites probables.
Ma première idée, car il manque peu de choses, serait l’impacte couleur de la lumière. Par exemple le coffre émettrait du bleu. Il faudra faire la fusion des couleurs, gérer les impactes individuels et on profiterait pour revoir et finir la propagation des lumières.
Ensuite, il y a bien sur l’éditeur, il faut l’adapter à la 3D et avancer sur l’insertion d’objets sur la carte.
Et puis, enfin, on verra bien l’inspiration du moment. Le but reste le même : le projet HeroQuest; tout en développant le moteur TARS.
Outre une petite boutade au Visage de chèvre (GOaT), il sera question ici d’un premier résultat, un retour au gris !
Mais pourquoi donc ? Du gris ? Mais où ça ? Ci-dessous :
Ceci ne vous dit peut-être plus grand chose mais il s’agit du ‘loader’, l’écran de chargement en attendant que la scène courante à venir soit prête. Et oui, il est sur fond gris :).
En fait, l’emphase sur le fond gris représente la finition d’un long processus qui vient de nous occuper ces dernières semaines, derniers mois.
Petit retour en arrière avec les performances au niveau de l’éclairage qui nous a déjà bien embêté et limité notre créativité. J’avais pas envie, mais au final c’est une vraie bonne solution : passer au WebGL.
Évidemment cela ne se fait pas tout seul, ni facilement. Si vous avez lu l’article précédent, vous savez déjà un peu, mais pour résumer : merci au site webglfundamentals.org qui m’a permis de démarrer. On attaque pas ça n’importe comment et le code actuel que je vais vous présenter reste un gros POC non-affiné.
Pour commencer il faut se rendre compte que le contexte WebGL ne travaille pas comme le contexte 2D, du coup, au niveau des classes de TARS et du POC il faut penser une division quelque part, en usage ou en héritage, mais quelque part. Là on se casse déjà les dents.
Le premier gros chantier a été de renommer pour identifier la 2D et séparer là où c’était nécessaire, avec, en bonus, le fait que ça continue de fonctionner…
Ensuite on sort l’huile de coude et on ajoute et duplique les composants pour gérer la partie 3D. Il a fallu donner du mou au Renderer pour lui envoyer des options spécifiques (premultipliedAlpha, alpha) et créer un service (pseudo-temporaire-je-POC-laissez-moi-tranquille) de gestion du contexte 3D avec ses shaders, car ici on y passe directement. Du coup, on ne peut pas démarrer sans que ça soit chargé et prêt, donc un événement à insérer dans le workflow.
De plus, pendant les tests, il a fallu désactiver les scènes ‘world’ et ‘loader’ qui sont IsoScene (isométrique) alors qu’on a pas encore affiché une seule image plate (scène ‘title’). Donc on va peut-être commencer par là.
Après, ça part dans tous les sens, le but est de produire une fonction drawImage tel que celle du contexte 2D, mais à ma sauce permettant son faux polymorphisme ainsi que l’injection d’additifs à destination des shaders tel que la gestion de la transparence, de la luminosité, la modification de couleur, etc. Et quand on a écrit la première version, et corrigée, on a le titre daaboo tel que nous l’avions avant ! Yeah !
Mais bon, pour les IsoElement ce n’est pas aussi simple. En 2D ils ont besoin du contexte 2D, il y a un cache et certaines limitations. En 3D, il n’y a pas de cache, on dessine en temps réel et on a des options via les shaders que la 2D n’a pas. Du coup, on y revient, la découpe 2D/3D et du code spécifique pour chaque.
Au final, tout se passe à l’appel de la fonction drawImage de mon service Sprite3D tout en tenant compte du positionnement XY que 2D fait en 2 temps et en un seul en 3D. Une fois l’appel vers drawImage fait, en gros on a fini et le reste se fait tout seul grâce à l’abstraction mise en place.
Ça dessine mais sans utiliser les attributs de la fonction toujours en développement
On a notre assemblage et correctement positionné !
S’en suit la fameuse finition du fond gris où encore une fois les techniques 2D/3D sont différentes, et donc le ‘clear’ de l’écran avant de faire le rendu. Petit jeu d’héritage et de conditions et hop, on passe la couleur ou une valeur par défaut, en restant générique, et on obtient le résultat tel que montré au début sur fond gris !
La suite se fait impatiente ! Réactiver la scène ‘world’, l’interaction et enfin : la lumière.
Bonus : j’ai eu une idée pour faire varier la lumière en tenant compte du delta du déplacement du personnage et ainsi rendre plus doux le changement de lumière sur chaque Tile. Ceci dit il faudra voir la lourdeur du processus, mais on peut déjà imaginer que nous n’avons besoin de refaire le pathfinding qu’au passage de Tile, et durant le delta l’usage suffit (à préserver donc), mais ça demande un reset de chaque Element quand même, enfin, en WebGL cela n’a plus du tout le même sens, ce qui nous arrange justement !










{kind=link}