Si on regarde Folk·o·pedia, même si Comitards date de 2006, on pourrait penser que le sujet ne date que d’il y a 7 ans, quand j’ai parlé de Comitards v3. Et là encore, vous me direz que c’est déjà pas mal. Mais que nenni, il y a une histoire plus ancienne qui prend forme aujourd’hui, dont je ne me suis rendu compte qu’il y a peu. Du coup, c’est parti pour un petit partage.
Folkipedia, juillet 2007 avec le FJDB (Fonds Jean-Denys Boussart), sans suite.
Reprise du projet en personnel, juin 2008.
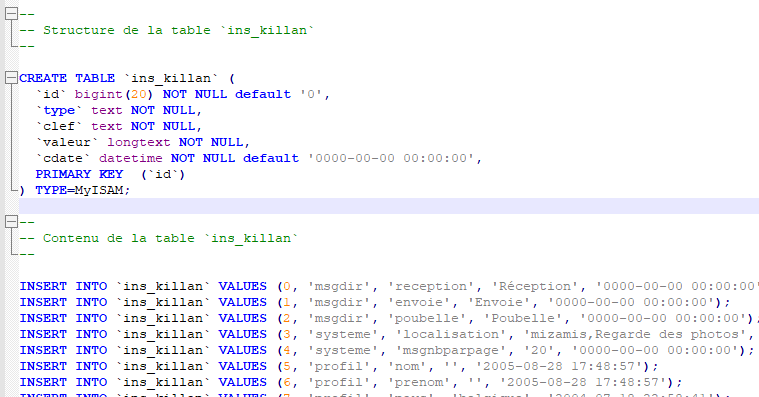
Nous sommes d’accord que Folk·o·pedia repose sur une ontologie, une base de connaissances, structurée en triplet (Sujet, Prédicat, Objet), ça ok, mais saviez vous que tout début 2000, un de mes sites, MiZaMis, utilisait déjà une base de données structurée différemment ? Suivant le principe de la base de registre de Windows, en un peu plus simple, chaque utilisateur avait sa propre table, organisée dans l’équivalent du prédicat – valeur (objet). Bien sur, à l’époque, cela a valu son lot de railleries, mais ce système a montré ses avantages et inconvénients et a pu durer toute la vie du site.
Structure de la table d’un utilisateur et exemple de contenu.
MiZaMis, division de MesDocuments, successeur de LaToile, ~2005-2008.
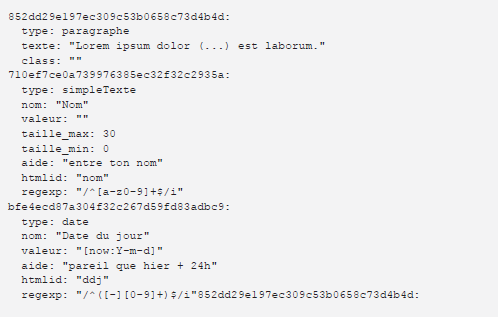
Plus tard, suite à mon second graduat en Techniques Infographiques (2008), j’ai proposé un mémoire sur « Recherche, étude et mise en œuvre d’un générateur de formulaire extensible, configurable et exploitable dans divers contextes« , qui, en résumé, avait pour but de générer des formulaires sur base d’une description, avec contrôles et différentes sorties générées possibles (web, PDF, rtf, Word, …), évidemment c’est la version web avec JQuery qui était le plus poussé, même si générer du PDF en code natif était un beau défi en soi.
Mais, n’est-ce pas également le but des modèles ontologique que renferme Folk·o·pedia ? Une description d’entité dont les prédicats sont eux-mêmes décrit et peuvent indiquer des contrôles ? En effet, le but d’un modèle est de pouvoir proposer un formulaire généré via la description de son modèle ! Évidemment on ne vas pas réutiliser la solution du mémoire ^^ elle est légèrement dépassée, mais l’idée, le concept, lui, reste valable.
Dump YML des données générées par l’éditeur.
Résultat généré sur base des données précédente en XSL et d’un transformateur XSLT.
Le même résultat avec une couche de CSS et de JS.
Dans une autre mesure, il y a eu aussi le projet FGPI (Folk Groups and People Involved vocabulary) en 2015, dont le but était de créer un ensemble de règles descriptives afin d’ajouter au site Comitards.eu une couche metadata suivant certains principes, mais, malheureusement, cela s’est avéré infructueux. Cela étant dit, une ontologie, donne exactement une suite à ce projet, décrire des objets et les liens entre eux, des gens et des groupes folkloriques, ce qu’ils ont fait, porté et vécu.
Et enfin, durant mon mémoire de 2022, dont le sujet, en français, était : « Comprendre les exigences d’utilisation des citoyens concernant les fonctionnalités de visualisation de données libres sur les portails du gouvernement« , on traite de la visualisation de données dont on ignore comment les représenter de manière lisible par le premier venu. Folk·o·pedia aura également ce soucis, l’ontologie ne donne pas ces informations en premier plan, il faut prévoir un tel système, le fournir et le traduire, et c’est génial car c’est encore tout un défi ! On peut partir sur un dictionnaire des prédicats par exemple, d’ailleurs celui-ci est déjà nécessaire en l’état du développement courant.
Vous avez là trois histoires qui se passent sur ~24 ans. Trois bout d’un problème qui se déroule en ce moment même. Je ne l’ai même pas vu venir, mais quelle surprise lors du constat ! D’où ce petit partage pour vous en faire part. 😉
Passer dans les backups et archives, pour vous trouver ces contenus, ravivent de beaux souvenirs. C’est toute une aventure, toute une partie de ma vie, de développeur web et de projets perso. Il y a tant à dire et à montrer pour saisir ce que cela peut représenter à mes yeux :).
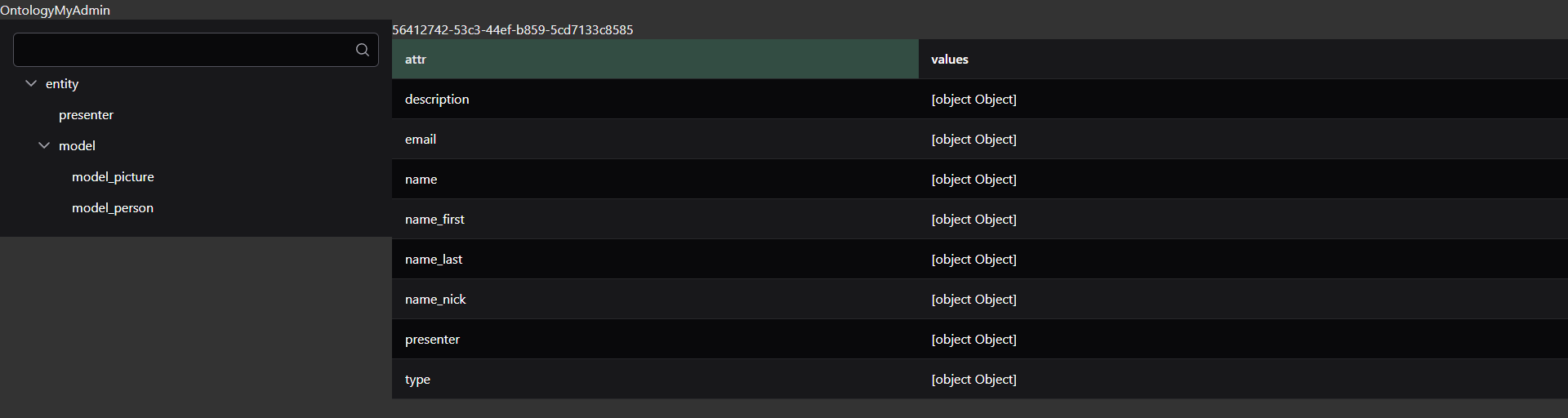
Et en avant première, une partie des coulisses actuelle, l’état sans censure du développement de Folk·o·pedia, son outil de contrôle : l’explorateur d’entités. À l’image d’un autre outils qui m’a aidé toutes ces années : PHPMyAdmin.
Comme annoncé en petit comité tout récemment, j’entreprend de recommencer le projet Folk·o·pedia. Ce sujet n’a de difficulté que de rassembler la connaissance, toute la connaissance folklorique… Et pour ce faire, je souhaite utiliser, me baser sur, ou m’inspirer du principe d’ontologie, de modèle ontologique et de triplet RDF, comme dit en 2019.
Cette année là, un modèle DB avait été conçus, correspondant et faisable, et un système a même été développé, tel un driver pour la suite du développement. Mais malheureusement ça n’aura pas été plus loin. Qu’à cela ne tienne, nous revoilà plus beau, plus malin, plus fort, plus motivé que jamais.
On récapépètte depuis le zébu. Suite à de nouvelles rencontres et d’événements, le projet évolue un chouilla plus avec l’ajout d’objets, même si la notion existait déjà, l’idée est plus aboutie (collection/fonds et métadonnées). De plus on reprend la base même des données, de leur structuration, de leur relation ou fonctionnement. On reprend tout.
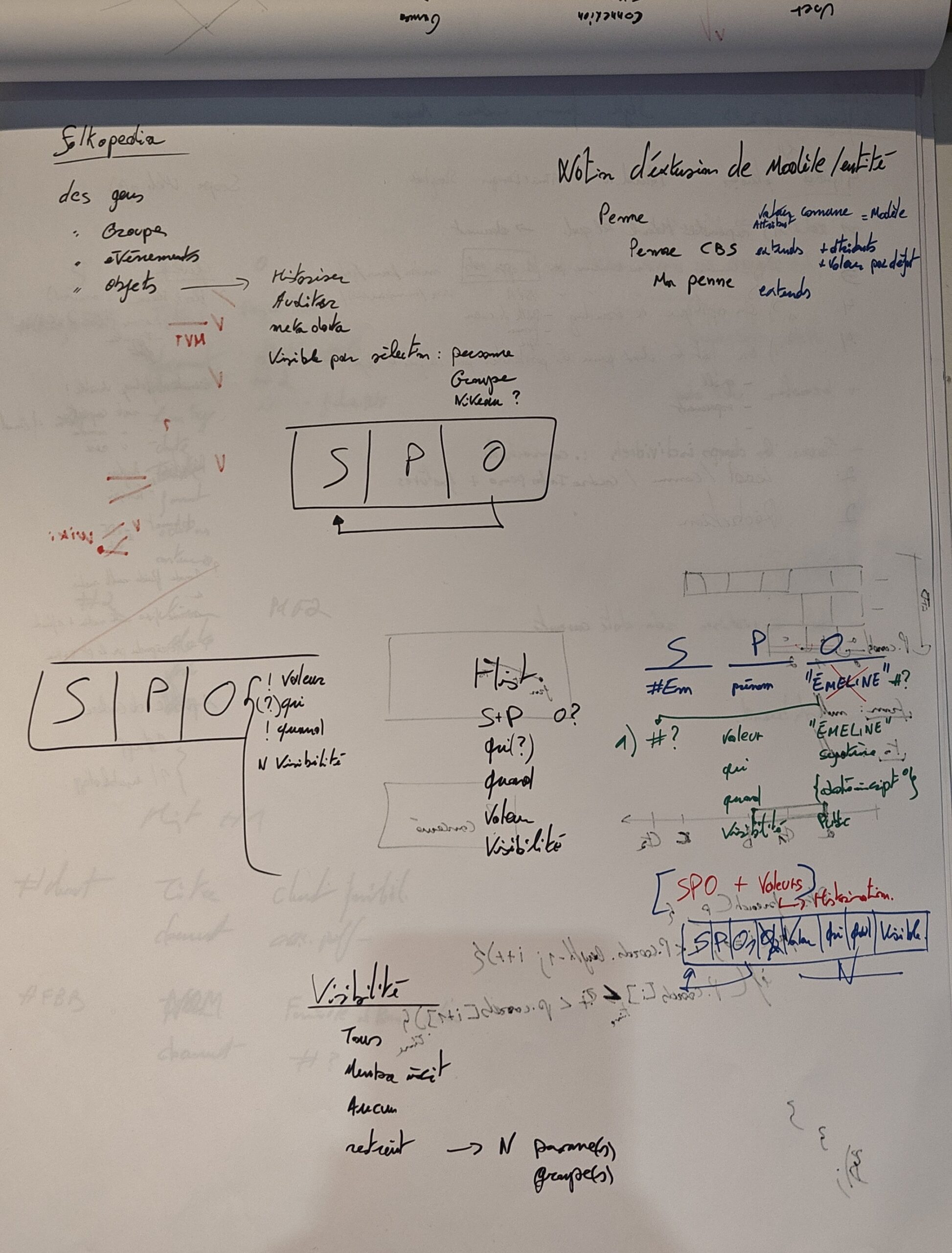
Brainstorming SPO, problématiques et performance.
SPO
Tout part de là en fait. Ce fameux triplet, que l’on peut comparer à une base de registre (cf Windows par exemple). Un quelque chose qui a un attribut qui a une valeur (ou plusieurs). Soit le Sujet – Prédicat – Objet. Et il faut savoir que O est soit une valeur finie (un prénom, une date, un nombre, …), soit un lien vers un S.
Donc on peut imaginer qu’une entité me représentant (S) qualifie mon surnom (P) avec la valeur « Killan » (O), mais il y a un second surnom (P) de valeur « Pôlebreak » (O). Donc un ensemble de valeurs pour un même prédicat.
Là où certain se chiffonnent déjà le caberlot, c’est comment savoir quel prédicat est le premier, le principal, etc. Et la réponse est simple : on ne le sait pas.
Historisation
Un autre aspect des données sur un tel site est la vie de la valeur elle-même. Si un document a été révisé il y aura des versions, pourtant il s’agit de la même entité, du même sujet. Si une personne change de prénom, il ne s’agit pas d’ajouter un nouveau prénom mais de remplacer sa valeur avec l’historisation de « l’avant ». Ainsi, si on demande à Folkopedia de nous donner l’état des lieux en 2006, l’on pourra constater que des groupes existent ou ne sont pas encore là, que certains avaient un autre nom, un autre lieu de rassemblement, l’état du comité de gestion (qui et à quel rôle), etc. L’historisation pourra ainsi permettre de voyager dans le temps.
D’un autre côté, l’historisation a également pour but de contrôler les modifications faites par les contributeurs, pour revenir en arrière en cas d’erreur par exemple (principe d’audit et de contrôle par les pairs).
On peut également définir qu’une information n’est pas pertinente à historiser, tel un statut temporaire, la participation à un événement, une demande de contact, …
Visibilité
Un aspect important également avec toutes ces données, est de savoir ce que l’on partage et à qui. Cela peut-être le partage de son email pour être joignable, l’affichage de son deuxième prénom, ou pour un groupe, de donner accès à un document, ce dernier pourrait n’être disponible que pour les membres. Ainsi quelque soit la donnée, celle-ci bénéficie d’une visibilité.
Cette visibilité peut être parmi une liste proposée (publique, privée, membre inscrit, mes amis, les amis de mes amis, …) ou définie manuellement : visible par tel ou tel personne, tel ou tel groupe.
Métadonnées
Suite aux points mentionnés ci avant, de comment gérer les valeurs multiples pour un même prédicat, ou d’historisation, et en ajoutant la notion d’audit et de visibilité, la question du comment est bien légitime.
Une première possibilité en suivant le modèle SPO, est que la valeur (O) est elle-même un (S) contenant la valeur elle-même, ses métadonnées, c’est-à-dire la visibilité et son audit (qui a modifié et quand). Le soucis sera au niveau de la performance, pour chaque valeur (O) il faudra chercher son S correspondant et les prédicats résultants.
Si nous avons 6176 inscrits en ce moment, que l’on imagine une centaine de paramètres à renseigner et que chacun ai été révisé 3 fois, en tenant compte du modèle de métadonnées, nous sommes à 7.4M de lignes encodées (max.), sans ajouter quoique ce soit de spécial. Soit, si je souhaite consulter le profile d’une personne j’aurais un maximum de 100*4 requêtes individuelles (pour chaque O cherche le S et ses valeurs de prédicat). Et ce à chaque consultation. Actuellement, sur Comitards, il s’agit d’un lot de 5-10 requêtes.
Une seconde possibilité est de détourner le modèle S¨PO pour aplatir le besoin fixe (audit, visibilité), et tant qu’on y est, vu qu’on parle de table de données, O est un soucis, il ne peut en une même colonne correspondre à la fois à une valeur et à une clé étrangère vers S, il nous faut donc 2 Onullable. Nous aurions donc quelque chose du style :
S, P, O1, O2/valeur, qui, quand, visibilité
O1 est un lien vers un S potentiel, O2 est la valeur (string) et le reste tel qu’attendu. Donc nous réduisons la complexité de 7.4M à 1.8M en simplifiant le principe d’historisation.
Reste que nous n’avons pas résolu la question de quel surnom est avant l’autre. Métadonnée en plus ? Une colonne ordre dans la solution #2 ?
S, P, SL?, valeur, qui, quand, visibilité, ordre
O1 renommé SL (S link, l’enfant de ce prédicat, ou laisser O, à voir) en optionnel (?).
Multiple façons d’historiser
Si on prend une valeur finie tel qu’un prénom, la solution précédente fonctionne très bien.
On peut également imaginer que la partie historisée se trouve dans une autre table pour les besoins de performances.
Mais quand est-il si on parle d’un document, ayant différents auteurs dans le temps, signataires, contributeurs, versions, etc. ? Imaginez un exemple avec un groupe folkorique quelconque (GFQ) ayant un document :
Notez que « restreint » devrait à son tour être une clef vers un S (type connu ou personnalisé). L’url du document à un ordre à null car non pertinent et une visibilité héritée (à voir, ça reste éditable). La date de publication est un string qui sera interprété par la connaissance du modèle, donc permet la flexibilité.
Maintenant que se passe-t-il si le document change ? On ne peut pas tout simplement changer chaque valeur individuellement, la notion de groupe est importante. Bien que s’il s’agit d’une typo dans le titre cela fonctionne. Faut-il encore qu’il y ai un besoin d’historiser le changement.
Ce qu’il va nous falloir, c’est que pour un même S:GFQ-doc#1, il nous faudra une version de plus. On pourrait encapsuler GFQ-doc#1 dans une coquille permettant de regrouper les versions du même document. Ou établir un lien entre les versions comme une chaine entre document, mais là encore côté performance ce n’est pas idéal.
Une autre solution encore est de considérer l’ajout d’un document en le qualifiant spécifiquement de version antérieur d’un autre. Il faudra faire le tri ceci dit.
Évidemment tout ceci se discute, c’est un point de vue et les contributeurs devront se poser la question et le système les aidera dans leur démarche. Il faudra bien sur confronter d’avantages de cas de figure et amender le principe. Et nous n’avons pas parlé des informations additionnelles que chaque élément peut porter (prédicats).
Pour ma part je pense que l’encapsulation est une idée intéressante au seul moment ou une nouvelle version arrive. Ainsi, de manière polymorphique, un document est son information directe ou indirecte via l’encapsulation. Ce sera au système de gérer.
Modèle et extensions
Nous en parlions plus haut, au niveau des types de données sur base d’un stockage en string. Les utilisateurs ne vont pas « coder » leurs données, c’est une interface qui assistera les utilisateurs en fonction de leur choix et les guidera dans le méandres des possibles.
Pour ce faire, NOUS devons avoir une vue claire de ces possibles, ce que chaque entité peut avoir comme prédicat, autoriser l’ajout de prédicat avec validation collégiale, faire vivre le modèle et ses usages.
Prenons un exemple avec un couvre-chef, il aura un nom. Si nous l’étendons et définissons la penne, celle-ci aura d’avantages de paramètres, tel que la longueur de la visière, la couleur du feutre, son origine, sa date. Mais là encore on peut parler d’un comité de baptême décernant la penne et ayant sa version dudit chapeau, avec son liseret, ses pins de base, le folklore attaché à la cérémonie, etc. Enfin, l’utilisateur du même comité de baptême, déclarera posséder un tel couvre-chef et sa penne aura sa propre vie, respectant ou non les valeurs du comité.
Ainsi par cet exemple on observe le principe d’extension du modèle. Le modèle permet de définir un objet, qui, quand il sera instancié, permettra à l’utilisateur d’avoir des informations à remplir. Évidemment il faut aussi imaginer la variance possible dans le temps, avant on faisait ça, mais aujourd’hui… etc. De même que le modèle peut être à respecter obligatoirement (couleur, longueur), alors que certains paramètres peuvent varier, comme une suggestion, on met le pins ici mais tu l’as mis là car ton parrain fait autrement etc. .
On aura donc besoin d’un système permettant la définition des modèles et ainsi définir le type de prédicat, leur pluralité, leur valeur par défaut, le côté obligatoire. tel un patron de vêtement, une recette de cuisine, vous gardez votre liberté.
Dans l’ensemble d’une entité (S), un prédicat pourra alors nous dire de quel modèle l’entité est issu. Ce qui permettra de construire le formulaire de saisie, d’apporter l’assistance à l’utilisateur, de contrôler la mécanique et fonctionnement, voire même de définir la validation par les pairs.
Autogestion
Vous avez donc compris la taille du possible, la quantité d’informations potentielles et nous n’avons parlé ici que de quelques cas. Seul je ne saurais, ni ne veux, gérer ça, c’est à la communauté et aux contributeurs motivés que cela revient. Donc il faut définir, à l’image de StackOverflow, une mécanisme adéquate. C’est à dire, un moyen de mesurer l’implication ET la justesse de participation d’un utilisateur pour lui donner tel ou tel droit.
Évidemment vos données vous regarde, mais vos apports seront confirmés ou infirmés, un jugement par vos pairs pour donner crédit ou informer d’une erreur. L’idée restant que l’information proposée sur le site doit être de la meilleure qualité qu’il soit (comme Wikipedia).
De plus, vos titres de guindaille seront utilisés pour savoir à qui demander une validation d’accès à un groupe, ainsi il faudra que X personnes valide et ainsi le titre est validé et la personne à alors accès aux données du groupe et peut s’enorgueillir d’en faire partie. Comme pour les tags sur les contributions, certains seront officiels mais les nouvelles propositions feront l’objet de vote.
Ainsi vous pouvez imaginer, qu’au travers d’une structure SPO, tout ceci, et plus encore, seront encodés. Il va de soit qu’une recherche sur la performance et un détournement de modèle quant à son implémentation seront nécessaire.
Suppression et historique
Un soucis se pose quand on parle de suppression dans un contexte historisé. Doit-on réellement supprimer la donnée ou juste rompre l’accès ? Mais si l’entité est liée et à son tour supprimée, comment gérer l’ensemble fantomatique ? Empêcher une suppression peut être une solution, si après un délai et/ou si lié à d’autre.
S, P, SL?, valeur, qui, quand, visibilité, ordre, supprimé, supprimé par qui
On pourrait ajouter alors cette information pour connaître sa disponibilité, mais le plus évident en terme de performance sera de déplacer le contenu dans une table dédiée. Alors, suite à un acte spécifique une liaisons sera établie pour aller les chercher, par exemple restaurer une donnée.
Mise en cache
De but en blanc, l’idée est simple, au lieu de faire des centaines de requêtes sur un sujet à chaque consultation, on stock le résultat en mémoire pour aller le chercher et rendre l’opération plus légère et rapide. Mais, nous avons une notion de visibilité, ce qui nous oblige à en tenir compte et à ne stocker que la partie publique, et peut-être à mettre en cache des segments par visibilité.
Publier le schéma
À l’image de schema.org, il nous faudra également un aplatissement du modèle, à des fins de documentation, de contrôle et d’échange.
Dans cette optique et en nous basant sur les données existante de Comitards, nous pourrons créer des modèles et une moulinette pour migrer l’information, ensuite confronter les cas d’usages et les extensions.
Conclusion
Comme vous le voyez, il ne s’agit pas d’un « yapluka », mais d’une procédure empirique qui se confronte à chaque étape à des questions de « comment » on va gérer telle ou telle situation. Cependant, la direction semble claire, les impératifs sont définit, la notion de performance en cible également.
La prochaine étape sera de modéliser cette base de données et d’y décrire le principe de modèle, ce qui pourra être testé par des cas d’usages.
En comparaison du modèle de DB de 2019, plus éclaté, il reste valide, et c’est peut-être vers quoi on ira une fois que l’on aura les données plus en mains avec cette recherche de performance. Ou c’est via la notion de cache que le salut se fera.
Cela fait presque 2 ans que c’est dans les cartons, et si on remonte à Comitards 2.3, bien plus encore. Ceci dit, c’est une attente justifiée vis à vis de l’important changement que cela cache. Évidemment, avec le hack du serveur et la perte d’articles, les derniers articles datant de la V2 et de Badawok, le blog manque d’actualité. On va corriger ça avec cet article.
L’idée de base est de pouvoir ajouter plus de types de contenu, ensuite de ne plus devoir modifier le site pour y arriver, et enfin, car je suis seul, que la communauté arrive à s’auto-gérer. En complément, tant qu’à faire, élargir/revoir l’idée de Comitards, profiter du retour d’expérience de l’idée et du site, et ainsi reforger le site entier.
Déjà le constat, le nom « comitard » est souvent mal compris, « Je ne suis pas comitard », et dans d’autres pays cela nécessite une explication. Du coup j’ai émis quelques idées et proposé une sélection à quelques proches concernés. Nous accueillons bien plus que des « comitards », il suffit de regarder les ordres en tous genres. Il s’agit en fait de concerner les acteurs et groupes des traditions, souvent festives. Le folklore dans son ensemble.
Folkopedia a été retenu, voyez y la contraction de folklore et d’encyclopédie, dit folk-o-pedia. Le ‘o’ me fait sourire, comme dans les imaginaires éthyl·o·trons, truc-o-matic, etc. qui contractionnent les mots entre-eux faisant naître un néologisme d’association.
La mécanique du site est également complètement mise à terre. Il ne s’agit pas de simplifier le schéma DB comme la dernière fois ou de faire le grand nettoyage en ajoutant ce qui manquait depuis la dernière fois, mais de repenser intégralement le système de base, et là j’ai été chercher loin.
Une de mes premières missions en tant que consultant au Luxembourg (vers 2011) m’a amené à découvrir les ontologies au travers d’une application dans le domaine de la recherche sur les tests assistés par ordinateurs (TAO/OAT). Très nébuleux pour moi, il m’aura fallu quelques recherches personnelles et un intérêt sur les métadonnées, avec un cours en prime, pour faire le lien avec Comitards. Évidemment pas au premier coup d’oeil.
Notez que j’avais tenté de normaliser le contenu de Comitards via RDF avec le projet FGPI : Folk Groups and People Involved vocabulary. Ceci, par manque de connaissance et de capacité de contrôle n’ira pas plus loin et restera probablement un brouillon intéressant sur un sujet ô combien difficile.
Ceci dit, je me base sur l’idée et non pas une application stricte, car les performances ne sont pas au rendez-vous et j’avais envie d’intégrer un cadre et des définitions pour le concept général. Du coup je repars sur une base de données relationnelles, un schéma spécifique et une optimisation par extraction des données. On aura un cache de lecture simplifié tandis que l’écriture se fera dans le système étalé. Du moins c’est comme ça que je vois la chose. Flexibilité totale et optimisation.
Pour ceux que ça intéresse, prenez toujours en compte l’usage. Combien vont écrire pendant que combien vont lire, que ça soit concurrent ou non. Sur un site comme Comitards, on a très peu d’écriture et beaucoup de lecture. Vous savez donc ce qu’il faut optimiser et pourquoi.
Avec ce nouveau schéma, plus besoin de modifier le site pour ajouter du contenu. Il suffit d’entrer les données du nouveau sujet, ses attributs et les liens possibles. Le tout sera fait via une zone d’admin (j’espère 🙂 ), mais ça reste l’idée.
Pour développer, un « quelque chose » (une photo, une personne, un groupe folklorique, …) est une entité, et celle-ci a des attributs (nom, date de création, histoire, …) et des liens vers d’autres entités (photos, documents, …). Le plus dur là dedans est la définition de chaque chose.
L’ensemble de cette réflexion est basée sur un cahier des charges regroupant tout ce que l’on souhaite intégrer, avoir une vue la plus claire possible du projet, des besoins, optionnels ou non. Ensuite, cela a été soumis à des volontaires de tous horizons, raffinant le premier jet jusqu’à obtenir quelque chose de correspondant à ces cibles. Merci à eux.
Dans cette continuité, merci mon Gros Lézard (Lord Suprachris), pour la belle prise de tête sur la conception du schéma de la base de données. Cela a été périlleux mais on a réussi à faire correspondre tout le cahier des charges en un seul schéma ! Et ça c’est pas rien !
Mais les prises de têtes ne sont pas finies, il y a encore un autre point important que je pensais définit depuis le début : le stack technologique. J’avais oublié un détail : je suis seul. J’avais imaginé un stack très développé, beaucoup de challenges et d’apprentissages, mais avec de telles envies, ce n’est pas demain que le site sortira.
C’est ma compagne, Boudine pour ne pas la citer, qui m’a remis les idées claires avec une réflexion sur le temps déjà passé, la difficulté que je me suis donné et l’inatteignable objectif. Du coup, à contre coeur, mais en sachant le bien fondé, j’ai revu le stack, du moins j’essaye. Il y a beaucoup de niveaux à décortiquer, mais je vais y arriver.
Enfin, car on arrive quand même au bout de l’état des lieux, il y a le design, lui aussi confiant dans les premières maquettes, mais aujourd’hui plus vraiment. Il faut attraper l’utilisateur dans une mécanique fort complexe et rendre ça sexy. Qu’il prenne plaisir à contribuer et à consulter. C’est chaud. Là aussi j’ai sollicité des avis, mais j’ai perdu mon auditoire tant ils se bloquent sur la complexité du projet. Je ne baisse pas les bras, je finirait bien par trouver cette nouvelle interface moderne et flexible capable de répondre aux attentes de Folklopedia.
C’est un peu comme dans Social Network (film de l’histoire de Facebook), j’en garde une phrase intéressante : « On ne sait pas encore ce que c’est ». On sait très bien ce qu’on a développé, bien sur, mais pas forcément ce que ça va ou peut devenir, son potentiel, ses usages et dérives en tous genres.
On en est là, entre une fin de post analyse et de début des travaux, avec un objectif de base débuté avant fin d’année. On avancera entité par entité, outil par outil, il y aura des refontes, des erreurs, des cris et des larmes, mais il y aura surtout un résultat à cette aventure complètement folle :
Numériser les traditions, enregistrer les vécus, préserver l’éphémère : L’encyclopédie folklorique.
Pourquoi diable un article sur Badawok 7.x ? Car en fait je l’utilise encore et continue de faire progresser sa branche, même si la 8 a été démarrée. D’un côté car il est en prod et qu’il faut suivre parfois les petits couacs potentiels, et puis, surtout, car je développe un nouveau site client, et donc, avec une version stable et pas en dev, comme je peux me le permettre avec Comitards.
Que dire ? Plein de trucs !
Depuis le début de la 7, une page peut prévoir des remplacements, textes pour 99% de l’utilisation mais également d’insertion de module, via les accolades ( {class:method|params|...} ). Une erreur a été corrigée au niveau de la détection des params, jamais utilisé jusqu’ici, et très fortement utilisé dans mon projet actuel. Quatre ans plus tard, une fonctionnalité voit son plein potentiel, et ça fait plaisir !
De même, une bonne surprise de conception, l’ordre des étapes de rendu permet de passer des arguments via PHP : {class:method|params|<?php echo $maVar ?>}.
Ainsi une problématique récurrente a pu trouver une nouvelle solution : la traduction de données.
Le système de langue étant dynamique, le nombre de langue varie et la maintenance de formulaires est pénible, coté front et coté code avec les checks etc. On découpe tout ça autrement.
Brutalement on imagine une table avec un seul id, mettez ce que vous voulez comme champs, excepté du texte. Coté formulaire vous ne vous occupez que de vos champs et vous insérez là où vous voulez l’appel au système de traduction ({trad:displayOne|params}) les params pouvant définir, dans un ordre définis, l’id du champs, son maxlength, etc. Je vous passe les détails.
Dynamiquement le formulaire sera complété de vos champs et ceux-ci seront pré-rempli si existant. Côté back, 2 méthodes, une de check des required et langue par défaut et une de sauvegarde multi-lingue.
Maintenance plus aisée, tant pour l’utilisateur que le développeur 🙂 !
Avec le même système d’insertion de module, et sur retour d’expérience du site terragusto.be, où la colonne de gauche devait être préparée par chaque action, ici notre menu/sous-menu principal est composé de 3 insertions, un par menu. Ainsi on ne met pas de code dans le layout non nécessaire et le rendu de manière centralisée avec les appels préparatoires qui vont bien et toujours les ACL qui vont avec.
Encore un autre usage et amélioration, la barre d’admin, d’habitude dans le layout sur condition ACL (Access Control List) et ici en centralisé avec config pour le global et la possibilité à chaque action de déclarer un menu potentiel, dont l’ACL activera ou pas l’affichage.
Enfin, un système de message d’erreur ou confirmation centralisé, inspiré de l’univers ZF. On envoie le message, on le configure pour son apparence et hop, le prochain affichage possible les affichera selon le template défini.
Cette version a encore du poil de la bête et n’a pas encore tout donné, c’est un plaisir personnel de voir son propre framework capable et fonctionnel :).
Pendant un temps, une hésitation fût, au sujet d’un passage vers GIT, tenté avec succès puis au sujet de rester là où on a commencé, sur SVN, que nous avons finalement gardé. Ceci à titre anecdotique. Une des raisons majeure est la simplicité d’un système connu et qui convient ainsi que la bonne intégration dans notre univers de développement.
Badawok 7.1 a été corrigé en passant sur dev.Comitards à titre de test. Les deux ont ainsi pu être restauré, testé et fonctionnel.
Il ne restait que 2-3 broutilles qui ont été vite réglées, tout va donc pour le mieux.
Comitards pourra désormais tirer partie des nouveautés et Badawok, profitant de l’expérience, pourra évoluer.
Nous en parlions fin janvier, un projet utilise la dernière version de Badawok, il s’agit de www.comitards.be 2.0. Il se porte comme un charme !
Cela a notamment aidé aux divers affinage du code et correction de bugs.
Il est donc fonctionnel, MAIS ne sera pas releasé en l’état tant que la seconde partie, l’édition en direct, ne sera pas finie. Cela laisserait trop de crasse, code non fini et ne serait pas correcte.
Le travail continue, un peu au ralenti mais en bonne voie !
Comitards 2 a été lancé le 17 mars vers 22h-23h après 27h de boulot en 2 jours pour finir, débugger et migrer de la 1 à la 2.
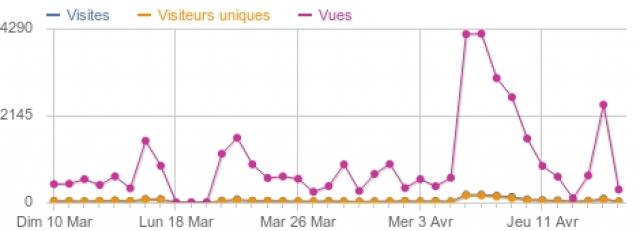
Le samedi alors que nous annoncions déjà depuis un moment la sortie du site en date du 18 (St Torè) le premier pique de visite ‘pointe’ le bout de son nez avec +1500 vues et 900 le lendemain, puis plus rien pendant 3 jours… FAUX le script de stats n’avait pas été réactivé dans la conf…
Le pique du jeudi (après le St Torè) nous a laissé un indice, soit +1200 vues puis +1500 à nouveau le lendemain.
En même temps la 2.0.4 est sortie corrigeant les quelques petits bugs urgents.
C’est le samedi 6, quand nous avons lancé la newsletter, après avoir ajouté quelques fonctionnalités de modérations et du contenu, que le gros pique a explosé les stats avec +4000 vues pendant 2 jours (pour un nombre de visiteurs unique grandissant).
Et va savoir pourquoi mais lundi 15 bam repique de +2400 vues, sans raison apparente, ah ben si, les mails qui s’ouvrent après coup et boom seconde vague ! Le reste du temps, moyenne agréable de quelques centaines de pages vue et dizaines de visiteurs uniques, pour un site occasionnel… 🙂
Mais comitards 2, il change quoi ?
En gros la base de données a été refondue, et on a coupé 1/3 des tables refondues en un système unifié, plus flexible.
Le design a lui aussi été complètement réécrit, ainsi que les interfaces et la manière d’interagir.
Le contenu a été complété encore et encore et de nouveaux types de contenus ont été introduit comme les autocollants, les guerres, …
Un long travail, jamais fini, mais qui en cet état représente une belle évolution de sa version précédente.
Cela n’a pas été facile mais pour ceux qui nous ont envoyé (à Sophie et moi) des mails de contribution et même des remerciements, ça me fait plaisir de l’avoir fait. Aux autres qui râlent sans prendre la mesure, même si on traite leur demande, on a juste envie des les envoyer au diable avec leçons de politesse, de comprendre qu’il ne paye pas et que quelqu’un derrière fait nuit blanche pour eux…
Le lancement ne c’est pas fait que sur internet.
Effectivement nous avons pris part à la St Torè (Liège) et distribué des centaines de flyers et autocollants de penne en guise de campagne promotionnelle. Merci à ceux qui nous ont aidé !
Là tout de suite Comitards 2.0.4 c’est 1928 inscrits, 267 groupes folkloriques pour 4 pays et 6 traductions.
Ça y est j’ai trouvé le temps ! Impossible avant avec une maison à finir, emménager etc… mais voilà ça y est j’ai trouvé du temps !
La phase 2 est terminée dans son idée originale. La DB est fonctionnelle selon la nouvelle idée. Certaines observations me font penser que d’autre tables vont sauter, comme la correction de penne selon option d’étude.
La phase 3 est en cours, j’ai placé un autocomplete pour supprimer les formulaire rébarbatif d’encodage d’études, titres et oripeaux.
Le tout en plus ou moins 30 heures de boulot en 3 jours. La suite est planifiée, y a encore pas mal de boulot et je ne vous parle même pas d’encodage supplémentaire.
Dans un premier temps on va finir le profil, aménager le générateur de couvre chef, je pense qu’une réfection en objet serait la bonne chose à faire avec héritage et cas particulier au lieu de conditions internes un peu sauvage.
Un gros travail sur la protection des données serait le point suivant avec la finition de la DB et d’un fallback de langue.
On terminera par un grand coup de peinture (CSS) pour le côté neuf moderne.
Sans oublier les nouvelles fonctionnalités, les encodages, les outils de modération de groupes folklorique, …
On est au w-e de deadline et Comitards v2.0 n’est pas prêt comme il devrait. Il y a eu des imprévus, beaucoup, et des soucis, qui ont été réglés. Cependant, la phase 1 est clôturée.
Il s’agissait de faire passer Comitards sous le nouveau framework badawok 7, toujours en développement. Ce dimanche aura été le rush des derniers tests et débogages et on y est, ce soir, Comitards ronronne.
Il se peut qu’on ai oublié un cas ou l’autre, on est jamais à l’abri, mais le site fonctionne comme il doit, comme il l’a fait jusqu’à présent.
La phase 2 consiste à transformer la base de données vers sa nouvelle formules et faire l’équivalent des fonctionnalités.
Ensuite la phase 3 intègrera les nouveautés et modifications attendues (fonctionnelles), et peut-être un coup de neuf sur le design. Bien sur une mise à jours des dépendances avec upgrade du code est également prévu.
Ça y est, c’est fait ! Le site comitards.be a été lancé ce mercredi 24 novembre lors de sa soirée de lancement qui se déroulait à L’Imprévu.
En arrivant chaque comité recevait un pack contenant un dossier de presse résumant la présentation et des flyers pour le comité. Chaque personne recevait également un flyers et un autocollant.
Les comitards sont arrivés, merci Adelein pour les cotillons 😉 et Aurélien et Jérémie pour leur feux de Bengale.
Une fois tout le monde assis, activation en direct du site et début de la présentation, suivis par une démo et les questions.
Enfin, on dégage un peu les chaises et le bar que tenait la Famille du Band Bleu proposait de finir la soirée par une guindaille de circonstance.
Le Petit Torè a fait un interview, article prévu pour février !
La soirée s’est très bien passée, un publique attentif et intéressés, une bonne ambiance, que du bonheur.
Lendemain, outre un mal de crâne réglementaire : des mails, et pas qu’un peu ! Des félicitations, remerciements, encouragement, des informations à ajouter, des erreurs à corriger, des propositions d’aide.
Mais aussi des chiffres. En un peu plus de 24h, il y a déjà +200 inscrits, +1000 visites et +24000 pages vues !!!
Un lancement rassurant, prometteur et très bien accueilli.