Comme annoncé en petit comité tout récemment, j’entreprend de recommencer le projet Folk·o·pedia. Ce sujet n’a de difficulté que de rassembler la connaissance, toute la connaissance folklorique… Et pour ce faire, je souhaite utiliser, me baser sur, ou m’inspirer du principe d’ontologie, de modèle ontologique et de triplet RDF, comme dit en 2019.
Cette année là, un modèle DB avait été conçus, correspondant et faisable, et un système a même été développé, tel un driver pour la suite du développement. Mais malheureusement ça n’aura pas été plus loin. Qu’à cela ne tienne, nous revoilà plus beau, plus malin, plus fort, plus motivé que jamais.
On récapépètte depuis le zébu. Suite à de nouvelles rencontres et d’événements, le projet évolue un chouilla plus avec l’ajout d’objets, même si la notion existait déjà, l’idée est plus aboutie (collection/fonds et métadonnées). De plus on reprend la base même des données, de leur structuration, de leur relation ou fonctionnement. On reprend tout.
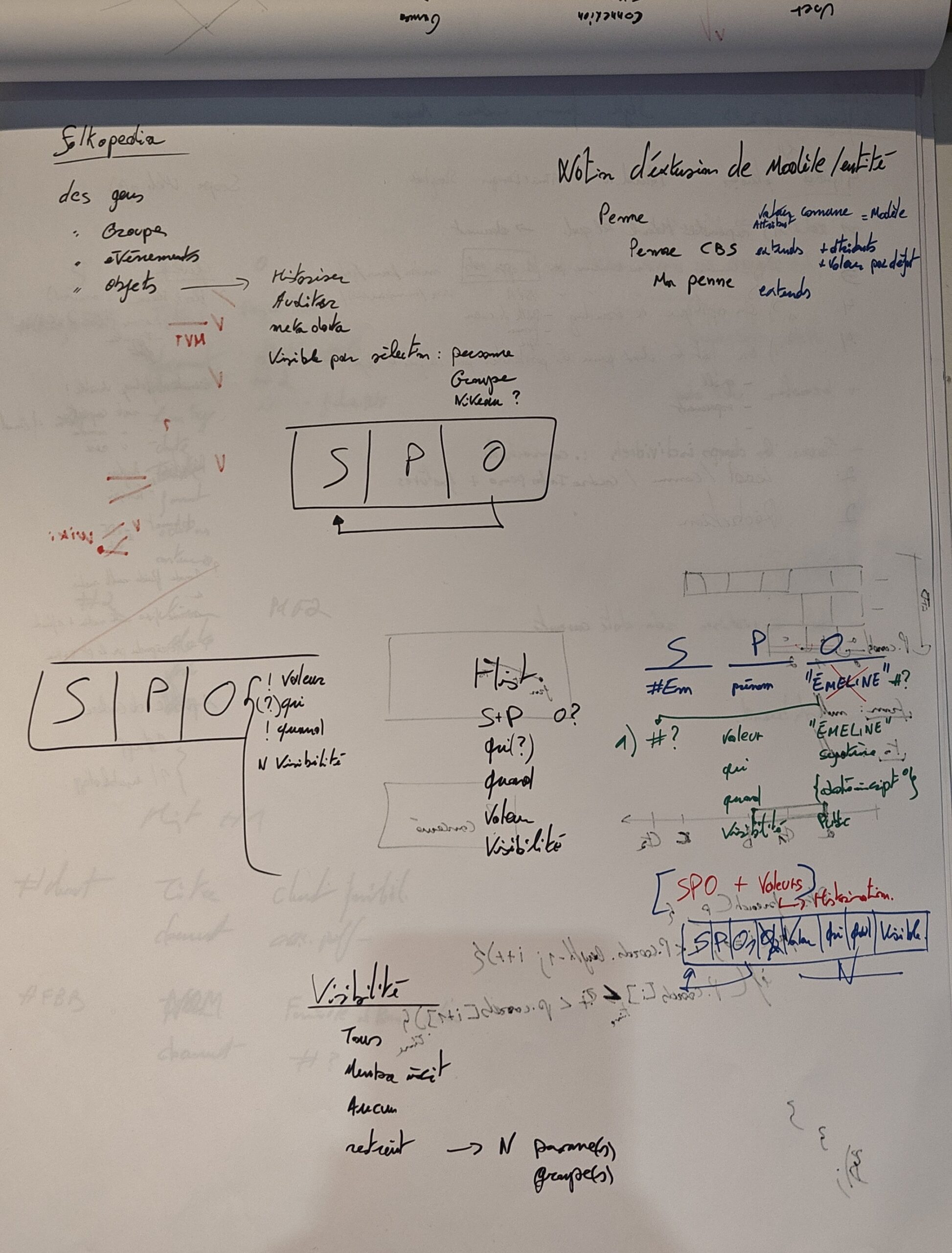
SPO
Tout part de là en fait. Ce fameux triplet, que l’on peut comparer à une base de registre (cf Windows par exemple). Un quelque chose qui a un attribut qui a une valeur (ou plusieurs). Soit le Sujet – Prédicat – Objet. Et il faut savoir que O est soit une valeur finie (un prénom, une date, un nombre, …), soit un lien vers un S.
Donc on peut imaginer qu’une entité me représentant (S) qualifie mon surnom (P) avec la valeur « Killan » (O), mais il y a un second surnom (P) de valeur « Pôlebreak » (O). Donc un ensemble de valeurs pour un même prédicat.
Là où certain se chiffonnent déjà le caberlot, c’est comment savoir quel prédicat est le premier, le principal, etc. Et la réponse est simple : on ne le sait pas.
Historisation
Un autre aspect des données sur un tel site est la vie de la valeur elle-même. Si un document a été révisé il y aura des versions, pourtant il s’agit de la même entité, du même sujet. Si une personne change de prénom, il ne s’agit pas d’ajouter un nouveau prénom mais de remplacer sa valeur avec l’historisation de « l’avant ». Ainsi, si on demande à Folkopedia de nous donner l’état des lieux en 2006, l’on pourra constater que des groupes existent ou ne sont pas encore là, que certains avaient un autre nom, un autre lieu de rassemblement, l’état du comité de gestion (qui et à quel rôle), etc. L’historisation pourra ainsi permettre de voyager dans le temps.
D’un autre côté, l’historisation a également pour but de contrôler les modifications faites par les contributeurs, pour revenir en arrière en cas d’erreur par exemple (principe d’audit et de contrôle par les pairs).
On peut également définir qu’une information n’est pas pertinente à historiser, tel un statut temporaire, la participation à un événement, une demande de contact, …
Visibilité
Un aspect important également avec toutes ces données, est de savoir ce que l’on partage et à qui. Cela peut-être le partage de son email pour être joignable, l’affichage de son deuxième prénom, ou pour un groupe, de donner accès à un document, ce dernier pourrait n’être disponible que pour les membres. Ainsi quelque soit la donnée, celle-ci bénéficie d’une visibilité.
Cette visibilité peut être parmi une liste proposée (publique, privée, membre inscrit, mes amis, les amis de mes amis, …) ou définie manuellement : visible par tel ou tel personne, tel ou tel groupe.
Métadonnées
Suite aux points mentionnés ci avant, de comment gérer les valeurs multiples pour un même prédicat, ou d’historisation, et en ajoutant la notion d’audit et de visibilité, la question du comment est bien légitime.
Une première possibilité en suivant le modèle SPO, est que la valeur (O) est elle-même un (S) contenant la valeur elle-même, ses métadonnées, c’est-à-dire la visibilité et son audit (qui a modifié et quand). Le soucis sera au niveau de la performance, pour chaque valeur (O) il faudra chercher son S correspondant et les prédicats résultants.
Si nous avons 6176 inscrits en ce moment, que l’on imagine une centaine de paramètres à renseigner et que chacun ai été révisé 3 fois, en tenant compte du modèle de métadonnées, nous sommes à 7.4M de lignes encodées (max.), sans ajouter quoique ce soit de spécial. Soit, si je souhaite consulter le profile d’une personne j’aurais un maximum de 100*4 requêtes individuelles (pour chaque O cherche le S et ses valeurs de prédicat). Et ce à chaque consultation. Actuellement, sur Comitards, il s’agit d’un lot de 5-10 requêtes.
Une seconde possibilité est de détourner le modèle S¨PO pour aplatir le besoin fixe (audit, visibilité), et tant qu’on y est, vu qu’on parle de table de données, O est un soucis, il ne peut en une même colonne correspondre à la fois à une valeur et à une clé étrangère vers S, il nous faut donc 2 O nullable. Nous aurions donc quelque chose du style :
S, P, O1, O2/valeur, qui, quand, visibilité
O1 est un lien vers un S potentiel, O2 est la valeur (string) et le reste tel qu’attendu. Donc nous réduisons la complexité de 7.4M à 1.8M en simplifiant le principe d’historisation.
Reste que nous n’avons pas résolu la question de quel surnom est avant l’autre. Métadonnée en plus ? Une colonne ordre dans la solution #2 ?
S, P, SL?, valeur, qui, quand, visibilité, ordre
O1 renommé SL (S link, l’enfant de ce prédicat, ou laisser O, à voir) en optionnel (?).
Multiple façons d’historiser
Si on prend une valeur finie tel qu’un prénom, la solution précédente fonctionne très bien.
S1, surnom, lien:h1, pseudoActuel, S1, 2008-01-01, publique, 1
h1, valeur, null, pseudoAvant, S1, 2006-03-04, privé, 1
S1, surnom, null, secondPseudo, S1, 2010-08-12, publique, 2
On peut également imaginer que la partie historisée se trouve dans une autre table pour les besoins de performances.
Mais quand est-il si on parle d’un document, ayant différents auteurs dans le temps, signataires, contributeurs, versions, etc. ? Imaginez un exemple avec un groupe folkorique quelconque (GFQ) ayant un document :
GFQ, document, GFQ-doc#1, null, GFQ, 2020-11-01, restreint, 1
GFQ-doc#1, url, null, "url du document sur serveur", GFQ, 2020-11-01, hérité, null
GFQ-doc#1, titre, null, "titre du document", GFQ, 2020-11-01, hérité, null
GFQ-doc#1, signataire, S1, null, GFQ, 2020-11-01, hérité, 1
GFQ-doc#1, signataire, S2, null, GFQ, 2020-11-01, hérité, 2
GFQ-doc#1, signataire, S3, null, GFQ, 2020-11-01, hérité, 3
GFQ-doc#1, auteur, S1, null, GFQ, 2020-11-01, hérité, 1
GFQ-doc#1, datePublication, null, "2020-10-05", GFQ, 2020-11-01, hérité, 1
Notez que « restreint » devrait à son tour être une clef vers un S (type connu ou personnalisé). L’url du document à un ordre à null car non pertinent et une visibilité héritée (à voir, ça reste éditable). La date de publication est un string qui sera interprété par la connaissance du modèle, donc permet la flexibilité.
Maintenant que se passe-t-il si le document change ? On ne peut pas tout simplement changer chaque valeur individuellement, la notion de groupe est importante. Bien que s’il s’agit d’une typo dans le titre cela fonctionne. Faut-il encore qu’il y ai un besoin d’historiser le changement.
Ce qu’il va nous falloir, c’est que pour un même S:GFQ-doc#1, il nous faudra une version de plus. On pourrait encapsuler GFQ-doc#1 dans une coquille permettant de regrouper les versions du même document. Ou établir un lien entre les versions comme une chaine entre document, mais là encore côté performance ce n’est pas idéal.
Une autre solution encore est de considérer l’ajout d’un document en le qualifiant spécifiquement de version antérieur d’un autre. Il faudra faire le tri ceci dit.
Évidemment tout ceci se discute, c’est un point de vue et les contributeurs devront se poser la question et le système les aidera dans leur démarche. Il faudra bien sur confronter d’avantages de cas de figure et amender le principe. Et nous n’avons pas parlé des informations additionnelles que chaque élément peut porter (prédicats).
Pour ma part je pense que l’encapsulation est une idée intéressante au seul moment ou une nouvelle version arrive. Ainsi, de manière polymorphique, un document est son information directe ou indirecte via l’encapsulation. Ce sera au système de gérer.
Modèle et extensions
Nous en parlions plus haut, au niveau des types de données sur base d’un stockage en string. Les utilisateurs ne vont pas « coder » leurs données, c’est une interface qui assistera les utilisateurs en fonction de leur choix et les guidera dans le méandres des possibles.
Pour ce faire, NOUS devons avoir une vue claire de ces possibles, ce que chaque entité peut avoir comme prédicat, autoriser l’ajout de prédicat avec validation collégiale, faire vivre le modèle et ses usages.
Prenons un exemple avec un couvre-chef, il aura un nom. Si nous l’étendons et définissons la penne, celle-ci aura d’avantages de paramètres, tel que la longueur de la visière, la couleur du feutre, son origine, sa date. Mais là encore on peut parler d’un comité de baptême décernant la penne et ayant sa version dudit chapeau, avec son liseret, ses pins de base, le folklore attaché à la cérémonie, etc. Enfin, l’utilisateur du même comité de baptême, déclarera posséder un tel couvre-chef et sa penne aura sa propre vie, respectant ou non les valeurs du comité.
Ainsi par cet exemple on observe le principe d’extension du modèle. Le modèle permet de définir un objet, qui, quand il sera instancié, permettra à l’utilisateur d’avoir des informations à remplir. Évidemment il faut aussi imaginer la variance possible dans le temps, avant on faisait ça, mais aujourd’hui… etc. De même que le modèle peut être à respecter obligatoirement (couleur, longueur), alors que certains paramètres peuvent varier, comme une suggestion, on met le pins ici mais tu l’as mis là car ton parrain fait autrement etc. .
On aura donc besoin d’un système permettant la définition des modèles et ainsi définir le type de prédicat, leur pluralité, leur valeur par défaut, le côté obligatoire. tel un patron de vêtement, une recette de cuisine, vous gardez votre liberté.
Dans l’ensemble d’une entité (S), un prédicat pourra alors nous dire de quel modèle l’entité est issu. Ce qui permettra de construire le formulaire de saisie, d’apporter l’assistance à l’utilisateur, de contrôler la mécanique et fonctionnement, voire même de définir la validation par les pairs.
Autogestion
Vous avez donc compris la taille du possible, la quantité d’informations potentielles et nous n’avons parlé ici que de quelques cas. Seul je ne saurais, ni ne veux, gérer ça, c’est à la communauté et aux contributeurs motivés que cela revient. Donc il faut définir, à l’image de StackOverflow, une mécanisme adéquate. C’est à dire, un moyen de mesurer l’implication ET la justesse de participation d’un utilisateur pour lui donner tel ou tel droit.
Évidemment vos données vous regarde, mais vos apports seront confirmés ou infirmés, un jugement par vos pairs pour donner crédit ou informer d’une erreur. L’idée restant que l’information proposée sur le site doit être de la meilleure qualité qu’il soit (comme Wikipedia).
De plus, vos titres de guindaille seront utilisés pour savoir à qui demander une validation d’accès à un groupe, ainsi il faudra que X personnes valide et ainsi le titre est validé et la personne à alors accès aux données du groupe et peut s’enorgueillir d’en faire partie. Comme pour les tags sur les contributions, certains seront officiels mais les nouvelles propositions feront l’objet de vote.
Ainsi vous pouvez imaginer, qu’au travers d’une structure SPO, tout ceci, et plus encore, seront encodés. Il va de soit qu’une recherche sur la performance et un détournement de modèle quant à son implémentation seront nécessaire.
Suppression et historique
Un soucis se pose quand on parle de suppression dans un contexte historisé. Doit-on réellement supprimer la donnée ou juste rompre l’accès ? Mais si l’entité est liée et à son tour supprimée, comment gérer l’ensemble fantomatique ? Empêcher une suppression peut être une solution, si après un délai et/ou si lié à d’autre.
S, P, SL?, valeur, qui, quand, visibilité, ordre, supprimé, supprimé par qui
On pourrait ajouter alors cette information pour connaître sa disponibilité, mais le plus évident en terme de performance sera de déplacer le contenu dans une table dédiée. Alors, suite à un acte spécifique une liaisons sera établie pour aller les chercher, par exemple restaurer une donnée.
Mise en cache
De but en blanc, l’idée est simple, au lieu de faire des centaines de requêtes sur un sujet à chaque consultation, on stock le résultat en mémoire pour aller le chercher et rendre l’opération plus légère et rapide. Mais, nous avons une notion de visibilité, ce qui nous oblige à en tenir compte et à ne stocker que la partie publique, et peut-être à mettre en cache des segments par visibilité.
Publier le schéma
À l’image de schema.org, il nous faudra également un aplatissement du modèle, à des fins de documentation, de contrôle et d’échange.
Dans cette optique et en nous basant sur les données existante de Comitards, nous pourrons créer des modèles et une moulinette pour migrer l’information, ensuite confronter les cas d’usages et les extensions.
Conclusion
Comme vous le voyez, il ne s’agit pas d’un « yapluka », mais d’une procédure empirique qui se confronte à chaque étape à des questions de « comment » on va gérer telle ou telle situation. Cependant, la direction semble claire, les impératifs sont définit, la notion de performance en cible également.
La prochaine étape sera de modéliser cette base de données et d’y décrire le principe de modèle, ce qui pourra être testé par des cas d’usages.
En comparaison du modèle de DB de 2019, plus éclaté, il reste valide, et c’est peut-être vers quoi on ira une fois que l’on aura les données plus en mains avec cette recherche de performance. Ou c’est via la notion de cache que le salut se fera.
Super (… complexe mais super quand même)
Vivement la suite !