Après plus de douze heures à creuser ma tranchée et à établir mon avant-poste, un bivouaque, un feu et ma radio, voici enfin venu le temps de faire le compte-rendu de ce week-end.
Nous y sommes, sur le Front du combat que l’on mène depuis bientôt presque un mois, au devant du combat, dans le feux de l’Action, loin du doux cocon de l’API. Enfin, pour ceux qui ont suivi, c’était loin d’être un simple doux cocon… ah ah !
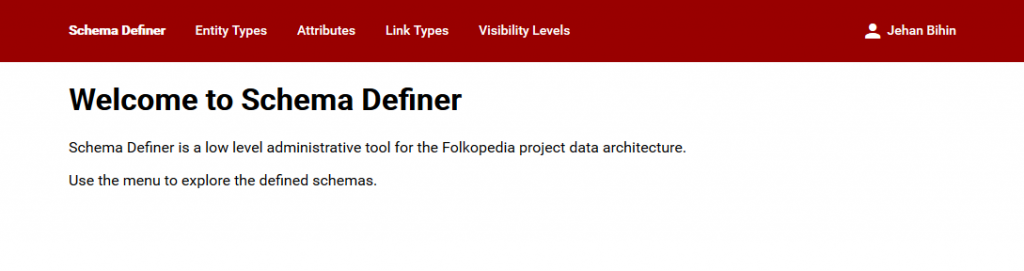
Comme prévu, à l’image de schema.org, voici l’allure de notre Schema Definer fraîchement créé. Simple et concis, de quoi parcourir les définitions et, à terme, de les éditer.
Pour faire un point technique, et justifier les 12h dites en début d’article, il a fallu commencer par mettre mon poste à jour et comme toujours non sans mal avec @angular/cli; Node ça été tout seul, et une fois le CLI (Command Line Interface) installé à la bonne version c’est Angular qui a suivi. Nous voilà donc avec un environnement propre Angular 8 et Material Design pour le fun et l’inconnue.
Pour ceux que ça intéresse, faites gaffe avec Material Design, cela ne remplace pas Bootstrap (grille, typo, style etc), mais ne concerne que les composants (bouton, tableau, formulaire, …). En bref, faites attention.
S’en est suivis une mise en place du projet et de l’authentification avec service et gardien (guard). Je vous passe les emmerdes et vous redirige vers quelques articles qui m’ont bien aidé/inspiré.
- https://jasonwatmore.com/post/2019/06/10/angular-8-user-registration-and-login-example-tutorial
- https://www.positronx.io/angular-7-httpclient-http-service/
- https://material.io/resources/icons/?icon=power_settings_new&style=baseline
- https://material.angular.io
La liste n’est pas exhaustive. C’est surtout le premier qui m’a bien aidé à comprendre la mise en place de la mécanique du gardien en Angular, ainsi que les interceptor et quelques opérateurs rxjs.
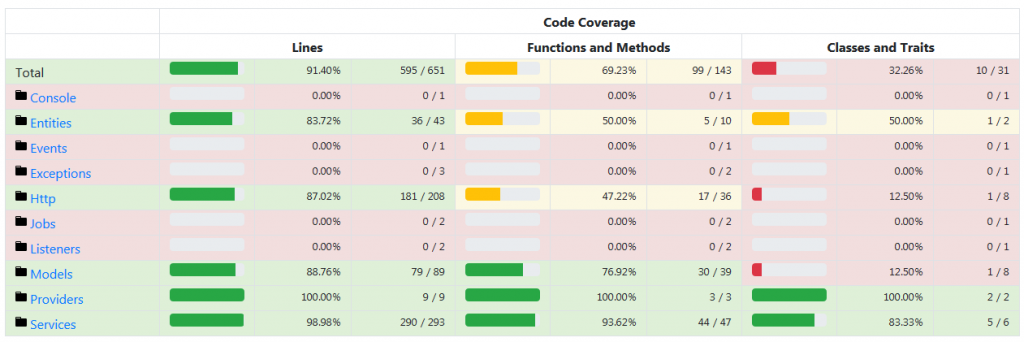
Vu la progression du week-end, voici un extrait représentatif du travail accompli depuis le début du mois (le détail serait beaucoup trop long), et qui, ce week-end, a fait un beau bon en avant.
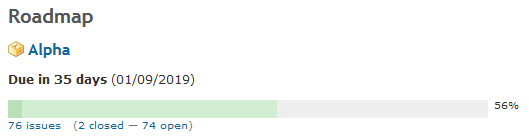
Maintenant que la machine est en place, le reste devrait suivre sans nouvelle mauvaise surprise. Enfin, j’espère…