Début 2019 on a Angular 8, et en cette fin 2023 on a reçus la 17, soit 9 versions ! Et pourquoi je vous dis ça ? Tout simplement car j’ai voulu mettre à jour le POC de TARS, et ça ne s’est pas du tout passé comme prévu malgré l’usage du site de migration qui est bien fait.
Le truc c’est que ce n’est pas exempt de soucis qui se pose au fil du temps. Par exemple, certaines commandes vont exécuter l’install (npm i), mais il vous faudra reprendre à la main en précisant le flag --legacy-peer-devs ou encore des résolutions d’arbre de dépendances qui ne se font plus correctement.
J’ai réussi non sans mal à passer à la version 11 mais pas plus loin, la quantité de conflits ou de soucis a explosé, pourtant le projet n’a rien de particulier d’un point de vue Angular.
Du coup j’ai opté pour une autre approche. Le projet n’utilise Angular que comme une coquille de lancement avec l’usage de l’injecteur et du client HTTP. J’ai donc créé un projet frais et j’ai replacé le code en dedans et là : BOOM ! Fallait pas oublier qu’on était passé en mode stricte, ou que le côté standalone a changé la manière de monter un module ou de gérer les composants, bref il ne s’en sortait plus.
On sort l’huile de coude, on repasse partout, on s’arrache les cheveux sur le typage fort qui me manquait à l’époque et on solutionne avec quelques generic. On ajuste la nouvelle mouture standalone avec les imports et providers locaux et ça tourne ! Enfin, oui, mais ça nécessitera quelques heures avant que le builder arrête de péter une durite. À savoir que si vous avez un couac il peut perdre la compréhension de tout les tags Angular et votre erreur c’est 1 détails quelques part… Bonne chance.
J’en profite pour vous filer un tuyaux : penser à définir vos composant en standalone, rajouter ce qu’il vous faut localement comme CommonModule ou HttpClientModule.
Un truc qui continue de m’agacer, c’est ce double état undefined et null, car si vous spécifiez un attribut de classe comme optionnel vous utiliserez un ? à sa fin, mais si vous l’assignez suite à un find d’un tableau par exemple, ce qui peut vous rendre votre type ou null, vous aurez un conflit possible de type, sauf si on parle de test(s) avant assignation ou autre écriture à rallonge; ça manque quand même de cohérence.
Enfin soit, c’était amusant d’y retoucher, avec l’objectif de reprendre son éditeur en main, toujours pour ce projet éternel qu’est Nahyan.
Angular 17 recèle d’un tas de nouveautés qui, je pense, pourraient, avoir leur rôle à jouer, voire en refactorisation, mais je m’avance un peu. Par exemple Signal, la sortie de Zone, la nouvelle syntaxe de templating, etc.
TipTap est un éditeur WYSIWYG que l’on doit mettre en place à la main (headless) basé sur ProseMirror. En gros vous avez un kit de départ et après vous activez des extensions. Dans mon cas, je l’ai utilisé dans un contexte Vue3 avec Prime pour en faire un composant d’édition en mode JSON dans le but de l’envoyer vers une moulinette pour obtenir un PDF en sortie et au passage variabiliser la structure. Partageons quelques XPs !
Ce qu’il faut savoir c’est que tout se base sur un JSON (JSONContent) qui est traduit en HTML au sein de l’éditeur via les extensions qui parsent et traduisent chaque élément de la structure en balises et attributs. En soit, sorti de sa boite, c’est très simple de mise en place et d’usage, on dit à un bouton d’exécuter une commande et suivant la sélection dans notre texte, l’effet sera appliqué. Là où cela se complique c’est de bien comprendre ces fameuses extensions que l’on voudra s’empresser de coder et modifier pour obtenir nos résultats attendus.
La documentation, bien que bien faite, manque de cas d’usage quand on descend dans le terrier du lapin blanc. Là on peut s’arracher les cheveux. D’un côté on a l’implémentation de ProseMirror par TipTap et de l’autre la couche de TipTap pour organiser leurs extensions/marks/nodes, et là rien n’est évident. Et pour ne rien arranger, HTML est déjà assez spécifique sur quasi chaque tag :
Un titre, c’est un tag H + un chiffre de 1 à 6. Donc un niveau de titre à transformer au rendu.
Une liste, c’est un bloc contenant des items, qui à leur tour contiendront du contenu (JSONContent déclare les contenu en tableau) et ce contenu est forcément un paragraphe qui contient un noeud texte.
Le gras, italique, barré ou souligné altèrent un sous ensemble de contenu (la sélection) dans un nouveau noeud texte avec une marque (mark) qui sera traduite au rendu (ajout de balise, attribut, …)
Le surlignage par exemple, comme dit ci-avant, prendra en plus un attribut (la couleur)
Et là on reste sur la base. Dans mon cas j’ai dû jouer sur de l’indentation de contenu, de la variabilisation de contenu et un saut de page.
Saut de page
Pour le saut de page j’ai opté pour transformer le hr (setHorizontalRule) en repère interprétable dans la moulinette PDF, et en CSS c’est également un tag visible manipulable. Ça c’est du détournement du fait que je n’avais pas l’usage du tag existant, facile.
Indentation
Pour l’indentation, c’est une autre affaire, et là on creuse les extensions. Je me suis basé sur l’extension de Evan Payne, en ajoutant un set défini pour fixer l’indentation directement à telle position.
On déclare en amont les options du module (IndentOptions) qui contiendra les variables que l’on peut définir via la configuration (quand on le déclare dans l’éditeur), tel que
Enfin, pour la variabilisation, là on doit parler de plusieurs choses :
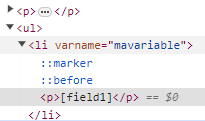
Remplacement de valeurs, par exemple identifées par [mavariable] ou {…} et autres possibilités
Dynamiser du contenu :
Section visible, ou pas, selon un paramètre (condition)
Répéter une section autant de fois que le paramètre contient d’éléments et remplacer le contenu (cf. premier point de la liste). (boucle)
Attribut
Voilà bien un beau problème, comment identifier un noeud de notre JSONContent et le mettre en rapport avec une variable pour le conditionner ? De plus, ce noeud doit être édité par l’interface éditeur et non en direct dans le JSON. Notre objectif va donc, suivant la position du curseur, d’éditer un attribut sur le bloc courant afin de laisser un marqueur identifiable pour effectuer le remplacement.
Pour faire très très simple, TipTap a une méthode
updateAttributes(tag, { varName: newVarName })
Et donc il faut connaitre le tag d’application, mais aussi que celui-ci connaisse l’attribut, sinon cela sera sans impact.
Dans le cas d’un item de liste, on peut créer une extension d’une extension existante, on l’agrémente d’un nouvel attribut
En l’état, nous pouvons détecter ce noeud et boucler une liste d’éléments par exemple, vive la récursivité, en mappant le contenu de cet élément de base comme template pour les variables et structure.
Bloc de section
Est-ce que l’on peut mettre un attribut sur un autre type de bloc pour obtenir un autre comportement : oui, mais… Dans notre cas, nous voulons qu’un ensemble d’élément soit masqué/visible selon une condition ou répéter si la variable conduit à un tableau. Nous allons devoir ajouter une encapsulation et intégrer notre variable comme vue précédemment. À l’image d’HTML, nous déclarerons une balise « section » pour représenter ce regroupement.
Cette fois-ci nous voulons créé un nouveau noeud et non étendre, du coup le code n’est pas le même
On appellera notre commande en lui passant le nom de notre propriété et sa valeur, ceci dit, nous aurions pu utiliser toggleWrap sur notre nouveau noeud puis updateAttribute.
Évidemment en comprenant l’effet toggle, nous aurions peut-être mieux fait de prévoir un wrapIn (encapsuler) et un lift (remonter/désencapsuler) et écrire de nouvelle commande en faisant des appels à ProseMirror. Ceci ne dépend que de ce que vous voulez proposer et couvrir comme besoin.
Modification du JSONContent
Maintenant que l’on a nos attributs de variable et nos 2 objets outils, nous allons pouvoir opérer. Soit on passe par la récursive qui transforme notre JSONContent en PDF et on interprète nos cas supplémentaires, soit, pour l’avoir en éditeur on parse et transforme le JSONContent directement, ce que nous ferons (mais les 2 fonctionnes pour l’avoir réalisé).
En gros on a notre structure source et on va créer, étage par étage notre nouvelle structure en modifiant le contenu au passage et on en profitera également pour effectuer les remplacements de valeurs.
str.replace(new RegExp("\\[" + k + "\\]", "g"), map[k] as string)
Design
L’avantage secondaire d’avoir des attributs ou balises identifiables sera la possibilité via CSS d’agrémenter votre visuel et indiquer là où il y a une variabilisation.
La difficulté sera de faire correspondre votre résultat visuel entre l’éditeur et votre sortie PDF ou web.
Conclusion
TipTap semble facile, l’est un peu puis devient bien complexe quand on veut creuser, j’ai l’impression de dire ça à chaque fois que je creuse ahah. Je vous recommande de lire leur code et d’aller creuser du côté de ProseMirror pour parfaire le niveau de vos devs et de votre compréhension.
FPDF pour moi reste une référence en terme de librairie bas niveau pour créer vos PDF et j’avais fait mon premier système (et d’autres) de facturation avec; et récemment j’ai découvert un successeur plutôt digne côté front : jsPDF.
Quand on parle de bas niveau c’est d’une part car vous avez la main et devez gérer quasi absolument tout vous-même (coordonnées x,y, occupation de l’espace, vos marges, vos retours à la ligne ou saut de page, …) et de l’autre car la librairie va écrire pour vous le code PDF natif (https://pdfa.org/).
jsPDF n’est pas le nouveau messie dépourvu d’erreur, elle en a son lot, parfois même agaçante vous demandant pas mal d’effort ou d’ingéniosité, mais dans le paysage actuel c’est une base plus que correcte. Attention toute fois de ne pas confondre convertisseur de contenu HTML vers PDF et jsPDF qui vous permet de le créer/composer. Les convertisseurs, au super rendu et 3 lignes de code, utilisent la librairie canvas pour faire une forme de capture d’écran et injecter l’image dans un PDF, joli mais sans accessibilité (sélection du texte, c’est une image) ni modifications (pour la même raison que c’est une image).
Bien que la documentation existe, elle reste sommaire et j’ai moulte fois dû, et au final préféré, une lecture directe du code disponible sur github. Il est certain que si vous entrez dans des réflexions de faisabilité, de type de paramètre ou de compréhension, vous descendiez à ce niveau régulièrement. Notamment un éternel sujet complexe : la taille d’un texte.
But de l’article
Cet article à pour but de dégrossir des points d’attention pour ceux qui veulent se lancer dans l’écriture de PDF. Il n’est pas aisé sans notion infographique minimum de concevoir un document qui aura du sens et respectera quelques notions « élémentaires ». J’entend par là la notion de marges, de taille de texte, de police d’écriture et de son style, ou encore d’interlignage, d’alignement, d’indentation et j’en passe.
Les points
Dans ce monde vous aurez accès à divers unité, mais je trouve qu’il est plus aisé de rester natif et d’utiliser les points, tel qu’un millimètre = 2.83465 points (se référer aux pouces du coup). Ou encore, une A4, aura pour largeur 595 pts et une hauteur de 842 pts. Et pour compléter ce sujet, un pixel aura un rapport de 0.75 pour 1 pts (pensez à l’unité de vos images par exemple).
Les couleurs
Elles peuvent être gérée par code hexadécimal (#333333) ou par RGB/RGBA (channel(s) en jsPDF), ainsi nous utiliserons une structure, qui prendra place en ch1, ch2, ch3 et ch4 tel que :
Afin de mieux gérer notre contexte, je vous suggère de créer une classe qui vous permettra de conserver votre position x, y, vos marges, les dimensions calculées d’espace disponible, puis la fonte choisie, sa taille, son interlignage, etc.
import { jsPDF } from "jspdf";
export interface Margins {
left: number
right: number
top: number
bottom: number
}
export const DIM_A4_POINTS = { width: 595, height: 842 }
export const DIM_MM_POINTS = 2.83465
export const DIM_PX_POINTS = 0.75 // 1.333
export class KPdf {
doc: jsPDF
margins!: Margins // Defined in constructor
x: number
y: number
pageWidth!: number // Updated by constructor call
pageHeight!: number // Updated by constructor call
fontSize: number = 10
lineHeight: number = 12
constructor() {
this.doc = new jsPDF("p", "pt", "a4")
this.setMargins(20 * DIM_MM_POINTS)
this.x = this.margins.left
this.y = this.margins.top
}
setMargins(margins: number): KPdf;
setMargins(left: number, right?: number, top?: number, bottom?: number): KPdf {
this.margins = right ? { left, right, top, bottom } as Margins
: { left: left, right: left, top: left, bottom: left } as Margins
this.updatePageDims()
return this
}
updatePageDims(): void {
// A4 forced format on portait orientation
this.pageWidth = DIM_A4_POINTS.width - this.margins.left - this.margins.right
this.pageHeight = DIM_A4_POINTS.height - this.margins.top - this.margins.bottom
}
...
Cadeau, je vous ai résumé ici quelques éléments de base, voyons ça ensemble.
Marges
Les marges, donc l’espace réservé depuis chaque bord de votre feuille, seront quasi indispensable dans vos calculs et positionnements, l’objet va nous aider à nous y retrouver. L’interface est claire assez, il vous manquera un getMargins() pour l’usage mais je vous laisse l’ajouter ;).
J’ai utilisé ici un double setterpermettant de setter les 4 bords d’un coup, égaux entre eux, comme dans le constructeur ou de pouvoir appeler sa version individuelle. Un énième alternative serait le passage d’un objet typé Margins, amusez vous, c’est selon vos besoins :).
Noter le type de retour (KPdf), pour ainsi pouvoir chaîner vos appels, quel confort quand même ;).
Constructeur
Le but est de créer notre base jsPDF correctement paramétré selon nos habitudes, besoins et choix technique, dans notre cas des pages en portait (« p »), en utilisant l’unité point (« pt ») et de dimension A4 (« a4 »).
Une fois établi, on met des marges par défaut, typiquement comme tous les traitement de textes qui vous proposent un modèle clef en main par défaut que personne ne retouche, sauf des gars comme nous ^^. C’est là qu’une première magie peut s’opérer, si on a des marges, connait alors notre origine (x,y) et l’espace disponible pour y mettre notre contenu.
J’ai également mis une taille de caractère (fontSize) à 10pt et son interlignage (lineHeight) à 12 en prenant l’échelle 1.2.
Et voilà vous êtes parti, bon amusement !
… si seulement ^^
Agrémenter KPdf
Vous avez une base, que vous ferez évoluer selon vos besoins au cas par cas de vos projets, perso je me suis mis des getter/setter pour x, y, xy, fontSize, lineHeight, mais aussi pour définir une en-tête et un pied de page. Là, je vous parlerai de delegate ou callback, un moyen de définir de manière extérieur un contenu à une méthode interne actuellement non définie.
export type HeaderPrototype = (pdf: jsPDF) => void
export class KPdf {
...
headerFct?: HeaderPrototype
footerFct?: HeaderPrototype
setHeaderFct(fct: HeaderPrototype): KPdf {
this.headerFct = fct
return this
}
setFooterFct(fct: HeaderPrototype): KPdf {
this.footerFct = fct
return this
}
addHeader(): KPdf {
if (this.headerFct) {
this.headerFct(this.doc)
}
return this
}
addFooter(): KPdf {
if (this.footerFct) {
this.footerFct(this.doc)
}
return this
}
newPage(): KPdf {
this.doc.addPage()
this.addHeader().addFooter()
this.setXY(
this.margins.left,
this.margins.top
)
return this
}
...
Exemple ici avec la méthode newPage qui ajoutera une page au document final et appellera de toutes façons l’ajout d’une en-tête et pied de page, évidemment si définit par l’utilisateur (détecté en interne de méthode). Bonus ici, reset des x et y au saut de page.
En démarrage par contre, car jsPDF crée une page par défaut, il faut les ajouter à la main, tel que :
const kpdf = new KPdf()
// Setters, margins
...
// Manage first page
kpdf.addHeader().addFooter()
Gestion du texte
J’ai eu 2 cas différent en terme de traitement de contenu, un premier avec une source Tiptap, dont je parlerai surement dans un autre article sous forme de retour d’expérience, et un autre avec une gestion de cellule de tableau maison, dont je vais un peu vous faire quelques retours.
On utilisera la fonction textpour écrire du texte dans notre PDF et petit conseil en passant, mettez l’option baseline à « top » mieux gérer votre x/y. Autre chose à savoir, si vous voulez aligner à droite, votre x est le x en fin de ligne/bloc et il faut également mettre l’option align à « right » du coup.
Retour à la ligne
Ce n’est pas aussi bête qu’il n’y parait, même si la fonction text à l’air complète elle manque clairement de documentation, cas d’usages clairs.
C’est quoi un retour à la ligne, c’est d’arriver au bout de notre espace disponible, de forcer un retour chariot au début de notre ligne (x), quel qu’il soit (pas forcément la marge gauche, surtout si indentation), de passer une hauteur de ligne (augmenter notre y) et de continuer d’écrire notre contenu (on parle ici de rendu du texte que l’on veut injecter dans le PDF).
La question est comment on sait ça ? Posez-vous juste la question. Vous avez une somme de caractères (un paragraphe par exemple), j’imagine que vous connaissez la taille du texte et que vous êtes prêt de ce côté kpdf.doc.setFontSize(12) par exemple. Sans faire du suspens inutile, je vous conseille splitTextToSize qui va vous rendre un tableau de string coupé à distance maximum (votre pageWidth par exemple ou la largeur d’une cellule). Si vous injectez le résultat directement dans text, pensez à préciser l’option lineHeightFactor (1.2 dans notre cas), personnellement, pour d’autres raisons, j’ai géré à la main l’écriture de chaque ligne, donc j’utilise ma variable lineHeight et je positionne mon x et y également à la main.
Gras/italique
Si vous avez du gras ou de l’italique dans votre texte d’origine vous risquez d’avoir des surprises, déjà la fonction text ne gère qu’une configuration à la fois, c’est à dire que si j’ai une phrase telle que : « mon contenu est composé », j’aurais virtuellement 3 configurations :
« mon » : texte normal
« contenu » : texte gras
« est composé »: texte normal
Attention, ici on parle au sein d’une seule ligne, c’est encore plus fun (compliqué) quand on gère ça en multilignes. Qu’importe votre façon de gérer cette structure de bloc, vous allez devoir boucler sur cette liste, calculer pour chaque la longueur du bloc de texte et ainsi gérer un x progressive par appel de la méthode text. Grossièrement on aurait (on suppose la gestion des espaces entre blocs) :
this.doc.text("mon ", x, y, { baseline: "top" })
// Change style
this.doc.text("contenu ", x + w1, y, { baseline: "top" })
// Change style again
this.doc.text("est composé", x + w1 + w2, y, { baseline: "top" })
On voit facilement l’intérêt de la boucle pour faire progresser x successivement. Cela suppose que votre gestion de bloc retiendra la largeur de celui-ci une fois calculé.
Multiligne
Si on pousse le bouchon où le dernier bloc est trop large par rapport à votre pageWidth/taille de bloc, alors on peut subdiviser en coupant au mot (textPart.split(‘ ‘)) et tester chaque mot un à un, puis forcer le retour à la ligne et reprendre. Vous aurez un algo maison combinant par exemple getStringUnitWidth ou encore splitTextToSize et votre gestion d’effets.
Dans mon cas Tiptap, ayant dû gérer pareil cas, j’ai fortement utilisé getStringUnitWidth, mais qui a sa limite concernant le fait qu’il ne gère pas le gras/italique, il faut appliquer un facteur empirique (~1.08) ou trouver le descriptif par caractère de la fonte utilisée pour les cas : gras, italique, gras+italique; et réécrire le calcul de largeur d’un texte donné. C’était le même soucis avec FPDF, tout dépend des métas de la fonte utilisée, mais là j’admet que ça dépasse mon niveau sur le sujet.
Saut de page
Comme on l’a vu pour le retour à la ligne, c’est pareil en y, si on voit que ce que l’on va écrire va déborder au delà de la marge inférieure alors il nous faut créer une nouvelle page tel que vu en exemple de code plus haut, avec en-tête et pied de page, repositionner x et y et reprendre notre rendu. Plus simple quand on a compris le retour à la ligne.
Il faudra cependant prêter attention à l’indentation. Par exemple, si vous êtes en train d’écrire les éléments d’une liste, vous aurez l’indentation pour dessiner la bulle par exemple, et si vous gérer plusieurs niveaux d’imbrication alors là encore plus (pensez récursivité). Hors des listes, l’indentation existe telle que dans un traitement de ligne quand vous utilisez la tabulation ou une règle de positionnement de début de paragraphe.
Tableaux
Un tableau c’est quoi ? Au delà d’une structure à 2 dimensions, ce sont des espaces délimités en largeur (mais pas que, parfois) dans lesquels doit prendre place un contenu. Sans parler des considérations esthétique, de formes et de couleurs, nos cellules sont des blocs, successifs pour lesquels notre logique de retour à la ligne revient.
L’astuce esthétique et logique (x,y) nous oblige à garder en mémoire quelle cellule aura pris le plus de hauteur parmi la ligne courante, sinon, par exemple, si vous faites un zèbre (couleur de fond de ligne) comment l’appliquer sans créer des trous dans certaines cellule ? Vous êtes obligé de faire une passe de calcul (découpe des textes, retours à la lignes, gestion des blocs, …), puis une seconde passe de rendu en profitant des données calculées (couleur de fond, positionnement x,y).
Répétition de l’en-tête
Quand on parle de tableau on oublie souvent de définir ce qu’il se passe quand on saute de page. On aurait tendance à continuer de faire le rendu des cellules sans se tracasser, un peu comme certains tableurs, mais pourquoi ne pas répéter votre en-tête de tableau ? Cela demande une gymnastique à l’image de notre en-tête/pied de page, même logique, un poil plus complexe.
export class KPdf {
cellPaddings!: Margins
tableHeaderInitFct?: HeaderPrototype
tableContentInitFct?: HeaderPrototype
constructor() {
this.setCellPaddings(0.5 * DIM_MM_POINTS)
}
// Table part
addTableHead(columns: TableColumns[]): KPdf {
if (this.tableHeaderInitFct) {
this.tableHeaderInitFct(this.doc)
}
// X, Y, fontSize and LineHeight already set by user
this.y += this.cellPaddings.top
columns.forEach((c) => {
const cellW = this.pageWidth * c.width
this.doc.text(
c.title,
this.x + (c.align === "right" ? cellW - this.cellPaddings.right : this.cellPaddings.left),
this.y,
{
baseline: "top",
align: c.align
}
)
this.x += cellW
})
this.y += this.lineHeight + this.cellPaddings.bottom
return this
}
addTableContent(columns: TableColumns[], data: any[], zebraColor: RGBColor = { r: 240, g: 240, b: 240 }): KPdf {
if (this.tableContentInitFct) {
this.tableContentInitFct(this.doc)
}
let zebra = true
data.forEach((d) => {
let maxCellHeight = 0
// Page break
if (this.y >= this.margins.top + this.pageHeight) {
this.newPage()
this.addTableHead(columns)
if (this.tableContentInitFct) {
this.tableContentInitFct(this.doc)
}
}
})
return this
}
...
Donc entre 2 lignes du contenu de votre tableau, on va créer une nouvelle page, remettre l’en-tête et le pied de page, puis on va rappeler l’en-tête de tableau, qui va rappeler le style définit dans une fonction spécifique (et externe), puis remettre notre configuration de corps de tableau et reprendre notre rendu.
Notez que pour le coup nous aurons un nouveau jeu de marges à tenir en compte : le padding des cellules.
Sources
J’ai créé un gist publique avec le code de la classe k-pdf au complet pour ceux que ça intéresse, merci de mentionner le github de l’auteur en cas d’usage ;). J’ai également ajouté un code illustrant l’usage de ce qui a été vu ici, nettoyé, cela va sans dire.
Conclusions
Comme dit, cet article visait à dégrossir le sujet tout en faisant un retour d’expériences. Il n’y a certes pas qu’une façon de faire et le code peut sûrement être amélioré, n’hésitez pas à m’en faire part.
Images
Sujet quelque peu embêtant, car la seule manière trouvée efficace est la base64, pointer vers un asset local (VueJs, Vite) vers addImage ne fonctionne pas.
Pensez à installer Vue.js devtools sur votre navigateur, ça vous sera utile pour voir que les données sont bien là, ou non.
Nous allons donc utiliser le DataTable de PrimeVue tel que nous l’avons fait dans le premier article et en faire un composant dynamique générique. Et malheureusement ce n’est pas un copier-coller de la version Angular, ça serait trop simple ;). Notez que je ne réexpliquerai pas tout vu que le détail se trouve dans les articles cités.
Contexte de base
On a donc un composant vue qui contient le DataTable, et une page qui appellera ce composant. Les données seront fournie automatiquement par Inertia, nous nous concentrerons sur le typage Typescript, la structure du composant et le raisonnement.
Le tableau avec rendu de cellule
Composant du tableau
Commençons par notre nouveau composant simple-table. Il s’agit donc de configurer un DataTable basique et de dynamiser les colonnes, pour cela on utilise une boucle v-for sur un composant Column en lui passant les paramètres qui nous intéressent. Ensuite, on peut se pencher sur le rendu de la valeur de la cellule via le template #body.
Pour rappel nous sommes en mode composition et en TypeScript. Il nous faut maintenant définir les propriétés de notre composant, tel que data pour les données, colsDef pour la définition des colonnes, defaultSort pour la colonne à trier par défaut et rowClass mentionné juste avant. Notez qu’on en profite pour typer fortement les données que l’on requiert.
L’idée reste d’envoyer un minimum de configuration et d’en déduire les valeurs par défaut, tel que la méthode de rendu de cellule par défaut ou le fait de pouvoir trier ou non une colonne. Pour ceci on passera par une variable computed , sans oublier de la typer, pour générer la liste des configurations de colonnes utilisées par DataTable.
En parlant de typage, voici l’interface utilisée pour la définition de colonnes :
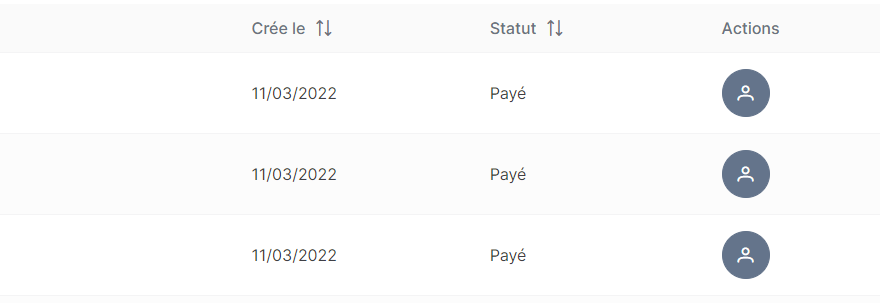
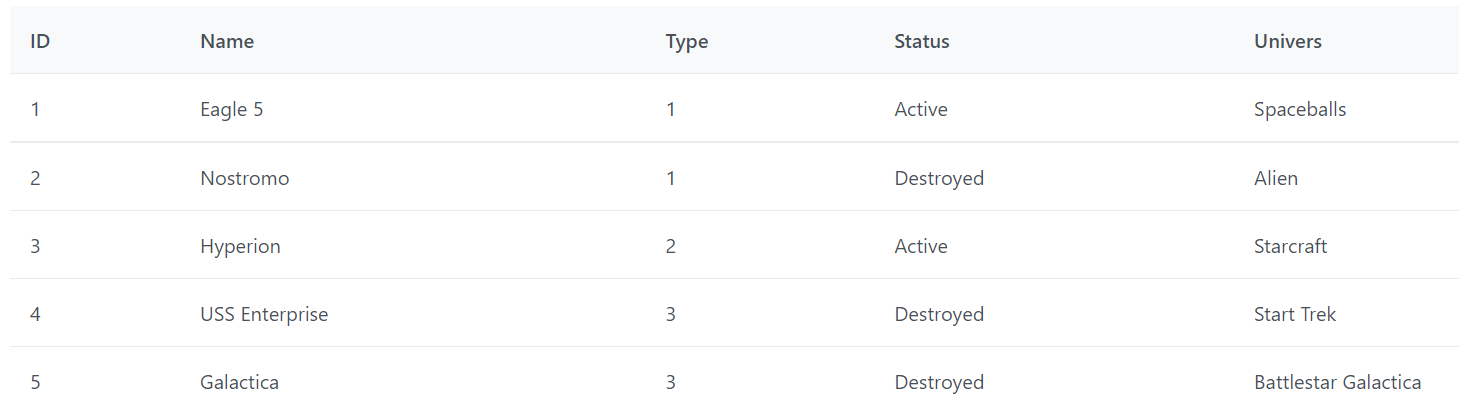
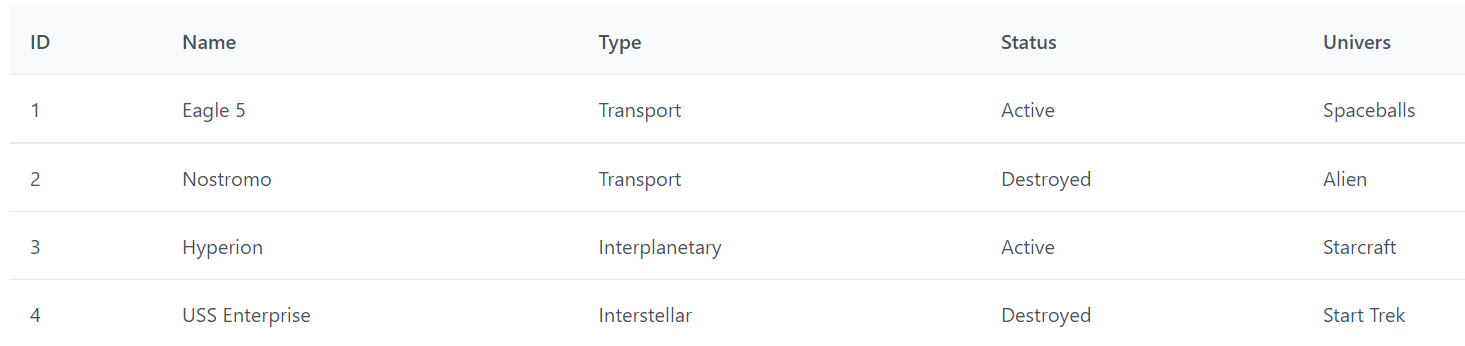
Côté code j’ai préparé de fausses données que j’ai simplifié pour l’exemple, ainsi que les méthodes utilitaires ou de rendu. Nous sommes dans un contexte de logiciel comptable et on affiche ici des factures, on aura 4 colonnes qui auront besoin d’afficher une valeur présentable, tel que la date ou le statut.
Notez que par rapport à la version Angular j’ai modifié l’interface CellComponent pour coller à la suite et à l’univers Vue. Il nous faut maintenant modifier notre composant simple-table.
On conditionnera l’usage au niveau template avec l’option components définie, sinon le rendu de cellule fera son office. Notez la simplicité, et donc la complexité/contrainte, de ce composant <component>. On doit lui envoyer un composant et ses propriétés (ainsi que son modèle si on regarde la définition totale). Là normalement vous raccrochez le wagon de l’interface, il nous reste donc l’application de tout ceci.
On ajoute une colonne d’actions à notre définition et on souhaite un bouton icône, là j’utilise simplement un Button de PrimeVue tel quel et je précise en props l’icône désirée et le style du bouton via sa classe, c’est pas plus sorcier au final. Il reste le markRaw qui est la réponse à une erreur qui se produit sans ^^, à priori la belle manière, je n’ai pas creusé ce coup-ci.
Le bouton s’affiche bel et bien en lieu et placeContenu de l’événement renvoyé quand on clique sur le bouton
Passer les valeurs de la ligne
Notre composant aimera surement savoir son contexte : la ligne courante du tableau et la colonne dans laquelle il se trouve, ce sont des bons repères pour agir ;). On commencera par étendre le v-bind avec le spread opérator, mais ensuite pour les events c’est plus compliqué, nous allons les intercepter.
On redéfinit les définitions d’appel des événements pour ajouter 2 paramètres, la ligne et son champs courant. En ayant préalablement vérifié sa structure. Et du coup l’usage change ainsi :
Suite à un soucis de machine virtuelle, mon Vagrant m’a planté mon stack et Virtual Box ne s’en sort plus, je suis tombé en difficulté avec mon logiciel comptable fait maison : Goo (v2!). Une occasion de refaire un truc qui n’a pas bougé depuis ~15 ans :/, et de se mettre à jour sur différentes technos ou d’en découvrir de nouvelles.
Cet article a donc pour but de servir de tuto pour monter une nouvelle solution, là où de bons articles existent et m’ont servi (voir les sources au fur et à mesure), mais où ils n’ont pas forcément fait les mêmes choix ou le même montage final.
Laravel et Sail
On démarre avec Laravel, version 9 en ce moment (la 10 arrivera début d’année), et on va utiliser Sail pour l’installer. Sail nous apporte le confort conteneurisé de notre environnement de dev prêt à l’emploi avec les composants dont on peut avoir besoin (ex mySQL). Dans le contexte de Goo, on a 3 tables (clients, invoices, items), que j’ai modélisé avec Gleek, donc je pense qu’un SQLite sera largement suffisant.
Dans un WSL 2 debian, avec un Docker desktop démarré, et dans un répertoire de votre choix, je tape donc :
Le paramètre with permet d’indiquer les services dont on aura besoin, pour qu’il les prépare tout seul dans des containers. C’est bien pratique même si on en a pas besoin, du coup à vide j’évite d’avoir ceux par défaut, sauf que, malgré tout, il met mysql par défaut. On le retirera avant le premier sail up dans le docker-compose.
Ça prend du temps et c’est normal, même si vous avez déjà récupéré les images etc.
Vous aurez peut-être une erreur du style :
Mais ça passe quand même ainsi, je pense que c’est dû au with vide, car sans je n’ai pas vu le même message.
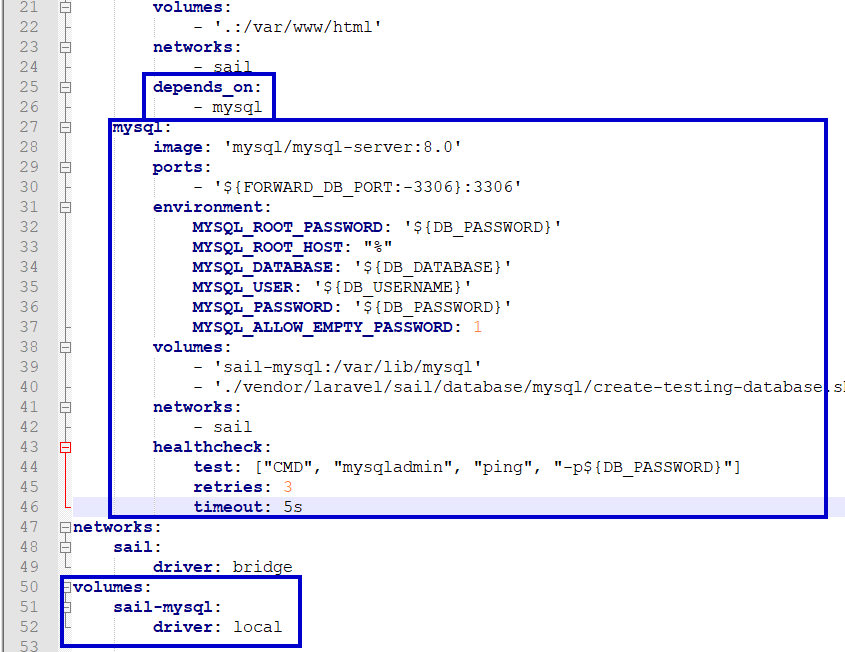
Comme dit juste avant, on va nettoyer notre docker-compose qui se trouve dans la racine de notre nouveau répertoire (ici goo3) et on va y retirer le bloc mysql, la ligne depends_on du bloc laravel.test et évidemment le volume de mysql en fin de fichier.
Quand on est prêt on va dans notre répertoire et on lance Sail :
cd goo3 && ./vendor/bin/sail up
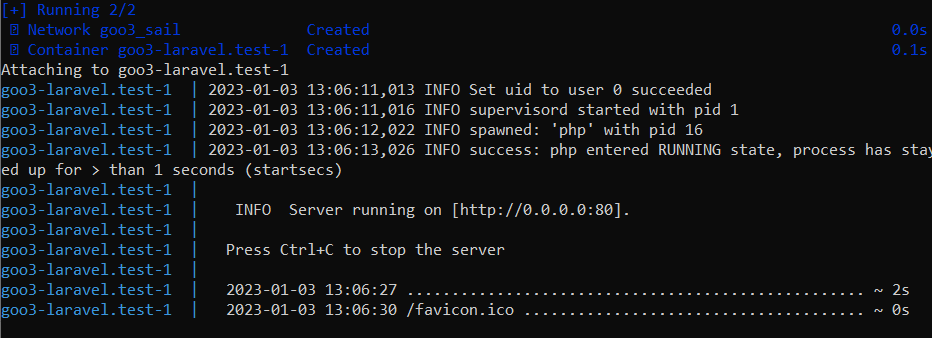
Notre console nous montrera qu’il lance un container et dans docker desktop on le verra également.
Il ne nous reste plus qu’à lancer un navigateur et aller sur l’adresse indiquée ou localhost pour voir notre Laravel installé par défaut qui se lance proprement.
Comme vous pouvez le lire en bas-droite de l’image (si vous avez de bons yeux), on est bien en Laravel 9 sur un PHP 8.
Inertia, Vue, Ziggy et Tailwind
Il ne sera pas question ici de Breeze (paquet d’authentification bien foutu), je n’en ai pas besoin, du coup on ne profitera pas des Starter Kits proposés. Ce que l’on veut c’est Inertia, c’est à dire, un moyen d’avoir un framework front-end (React, Vue) en relation avec notre back-end PHP, non pas comme un back-end PHP qui serait un service REST (ex: Lumen) et un front-end qui le consomme, mais bien un back-end avec le rendu des pages côté back (SSR) et le dynamisme d’un Vue côté client une fois la page chargée. Mais on navigue bien d’une page à l’autre en passant par un appel back. Je trouve que cet entre-deux est intéressant pour les petites applications qui veulent se doter d’un front plus moderne sans devoir forcément sortir l’artillerie lourde. Je vous laisse lire la doc d’Inertia pour comprendre toute la mécanique, c’est bien expliqué.
Comme vous pourrez le voir dans votre fichier package.json nous avons déjà Vite et PostCSS. Vite remplace Mix et nous demande de nous adapter côté config. PostCSS sera utile pour l’installation de TailWindCSS.
Installation
Lançons nous ! On va exécuter une série de commandes pour installer Vue et Inertia ainsi que les dépendances nécessaires pour les lier. Pour ce faire je lance un Git Bash dans le répertoire du projet et j’ai Node 16 installé, il faut que Sail tourne. Et pour les commandes Sail je passe par la WSL (et/ou on fait tout en WSL si vous avez un Node 16 installé dedans).
Reprenons ce tas de lignes, on installe Vue côté front et ensuite Inertia côté back, puis côté front avec l’option Progress qui permettra de montrer les chargements de contenu XHR (AJAX olè). On ajoute Ziggy pour avoir le helper des routes côté front sur base de ce que le back a comme définitions (cf routes/web.php).
Pour la partie middleware, artisan va nous générer un fichier que l’on va pouvoir inclure dans notre config app/Http/Kernel.php :
On peut noter l’absence de title dans le head mais la présence du @inertiaHead qui nous permettra de jouer là dessus en fonction de la page affichée. @routes c’est Ziggy.
On va créer un répertoire dans resources/js : Pages et on va y ajouter une page : invoices.vue :
On va également créer une route pour cette page dans routes/web.php :
<?php
use Illuminate\Support\Facades\Route;
use Inertia\Inertia;
Route::get('/invoices', function () {
return Inertia::render('invoices', ['title' => 'Factures']);
})->name('invoices');
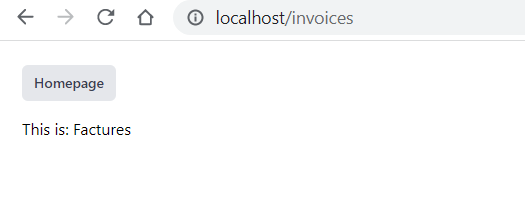
Donc on a Sail qui tourne, le run dev également, on peut se rendre sur http://localhost/invoices et voir le résultat :
Évidemment dans notre test on a hardcodé le titre et la réponse, on a pas découpé les composants, etc. Pas encore !
Layout
Plongeons dans cette question, et là un article, ainsi que la doc officielle vont nous aider. En gros on va créer un autre répertoire Layouts qui contiendra un fichier vue que l’on va appeler basic. Celui-ci contiendra quasiment tout ce que nous avions précédemment sauf Head et le contenu, ici un simple H1, qui sera remplacé par <slot/>.
À noter que les articles manquent de précision pour les novices en Vue, donc ils oublient de nous dire que la partie script est importante et manque dans leur exemple. Ce qui nous permet aussi de lui donner un nom explicite à l’usage. Notre page devient donc :
Relancez votre page et vous aurez le même résultat que précédemment, mais en mieux structuré. Le Head reste dans la page, on appelle le layout et on met notre contenu dedans, fin ! Simple !
Upgrade du Layout : Head title
Répéter le nom du site » – Goo 3″ dans toutes les pages n’est pas une bonne pratique du coup on peut imaginer passer le title à notre Layout qui centraliserait ce bloc de code.
On est un peu passé à côté, mais comme dit plus haut, pour une petite base de données de 3 tables nous n’avons pas besoin d’un gros système, pourquoi donc ne pas utiliser SQLite. La documentation de Laravel nous donne la solution simple. On va créer un fichier dans le répertoire database et déclarer son type dans notre config .env.
Pensez à virer les migrations qui ne vous intéressent pas avant d’exécuter la commande de migration d’artisan. Dans notre cas nous n’avons besoin que de nos 3 tables, du coup j’ai traduit mon schéma Gleek en migration Laravel.
Sanctum
Quand vous ferez votre migration, malgré le nettoyage, vous verrez apparaitre une migration en trop : c’est sanctum. Nous on ne l’utilisera pas, donc la solution, donnée dans la doc est d’ajouter une commande dans le register de l’appServiceProvider.
use Laravel\Sanctum\Sanctum;
class AppServiceProvider extends ServiceProvider
{
public function register()
{
Sanctum::ignoreMigrations();
}
On sort des sentiers battu bien connu de MySQL avec un bon PHPMyAdmin en utilisant SQLite, du coup j’ai opté pour l’extension Chrome SQLite Manager. Et parmi les 3 extensions disponibles au moment décrire cet article, c’est la meilleure que j’ai testé.
Une fois le fichier chargé on peut voir la liste des tables et de quoi faire des requêtes.
PrimeVue vs Tailwind
D’abord se poser la question, est-ce qu’ils peuvent cohabiter et apporter leurs pierres à l’édifice ? La réponse en un article : oui ! L’idée étant que PrimeVue peut jouer le jeu en proposant ses composants sans utiliser les classes de Tailwind, mais en proposant un thème adapté, ce qui nous laisse champs libre pour un double usage. Il ne reste plus qu’à tenter son installation dans notre solution déjà bien aménagée.
Mais après quelques chipotages sur les priorités et les conflits générés voici la solution. On inverse et on met la base de Tailwind avant sinon celle-ci elle va écraser des styles de PrimeVue et on adapte l’import pour éviter le soucis de compilation.
Si vous faites le test avec un Button de PrimeVue, il était blanc de base et bleu au survol du fait d’une règle de background transparent. Maintenant c’est corrigé et le bouton est bien visible dès le début grâce à l’ordre des règles.
Tester c’est douter
Pour voir si c’est en ordre, j’ai simplement pris un composant simple ‘inputText’ dans ma page invoices.
Pas de mystère là dedans, un fichier assez classique avec en plus le plugin et l’inclusion des ressources à traiter. Il nous reste plus qu’à utiliser le mode typescript dans notre fichier invoices.vue par exemple.
On peut également changer de mode dans Vue et passer du mode options au mode composition. Essentiellement cela change la manière de concevoir vos composants. Pour ce faire, nous n’avons qu’à modifier notre fichier invoices.vue.
Ici j’ai remis l’exemple de l’inputText pour illustrer le principe et montrer que ça fonctionne. Notez l’attribut setup, le code en moins et la manière de déclarer une variable avec ref() et la méthode onMounted.
Conclusion, et ensuite ?
Ce fameux ensuite, car oui on peut toujours aller plus loin, certes, mais pour un tuto c’est déjà pas mal 🙂 On a quand même accompli quelques sujets. On a donc un back Laravel installé avec Sail, une dynamique de pages en Vue, Inertia et Ziggy, du Layout et un design Tailwindcss – PrimeVue. Si ça c’est pas joli ! Et en plus on a une base de données et du typescript, quelle affaire :p !
La suite c’est le développement de Goo 3 tel qu’énoncé en début d’article, mais ça, ça sera peut-être un autre article s’il y a de quoi en dire, car au final les points saillants ont déjà été abordés. Affaire à suivre !
[Bonus] Un petit favicon ?
J’ai découvert un chouette site pour générer facilement un favicon multi support. Pratique pour les projets d’entreprise par exemple. RedKetchup ont quelques outils sympa, je vous laisse les découvrir.
Pas de révolution ici, c’est quelque chose somme toute d’assez classique, un back-end NodeJs en Express et une doc Swagger basé sur un OpenAPI. Le truc étant de faire le routage et la doc en un seul point, améliorant la maintenabilité et automatisant le routage.
Pour ce faire il suffit de démarrer un nouveau projet et d’installer quelques librairies de base :
npm init
npm i express --save
npm i swagger-parser --save
npm i cors --save
npm i swagger-routes-express --save
Le framework express comme base,
La lib swagger-parser pour lire et interpréter le fichier openapi.yaml (définition de l’API),
La lib cors pour définir l’autorisation,
La lib swagger-routes-express pour créer un connecteur reliant les contrôleurs au routeur basé sur la définition de l’API,
La lib swagger-ui-express pour mettre à disposition un swagger de la définition de l’API, sur une route /api-docs.
Maintenant qu’on a la base il nous faut le squelette d’application, du coup au lieu de taper tout le code ici je t’invite cher lecteur à te rendre sur ce GitHub, et nous allons détailler les parties intéressantes.
OpenAPI
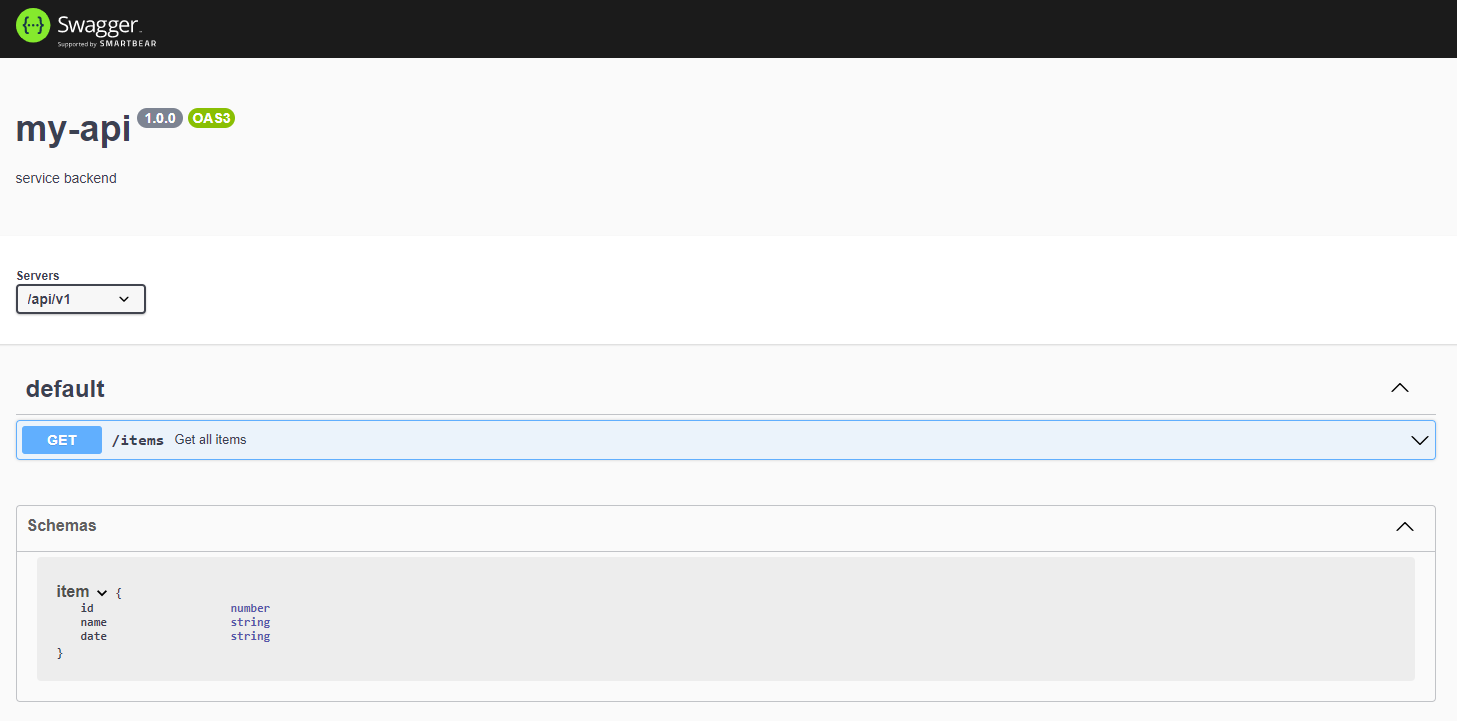
D’abord, qu’est-ce que l’on veut accomplir ? Dans cet exemple on va simplement faire un service REST pour obtenir une liste d’items, un GET. Nous allons donc décrire un fichier openapi.yaml décrivant cela.
openapi: 3.0.0
info:
description: service backend
version: 1.0.0
title: my-api
paths:
/items:
get:
summary: Get all items
description: Get all items
operationId: getItems
responses:
"200":
description: success
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/item'
servers:
- url: /api/v1
components:
schemas:
item:
type: object
properties:
id:
type: number
name:
type: string
date:
type: string
En gros : on définit une route /items qui renverra un tableau d’item et la structure item. Jusque là c’est du formalisme standard que vous retrouverez un peu partout.
Le serveur
Ensuite il faut construire notre serveur (je n’utiliserai pas le générateur), pour cela nous aurons principalement 2 fichiers de base et un fichier contrôleur. Le schéma étant assez simple, on reçoit une requête, le routeur fait un match et associe la méthode du contrôleur.
On commence par écrire un fichier makeApp.js (dans /src), qui correspond à la définition de notre serveur, notre application. Dedans on y trouve beaucoup de choses, on y reviendra plus en détail après, mais en gros on décrit ce que nous avons dit plus haut, à savoir : définir un serveur express auquel on va connecter le routeur, lui-même basé sur le fichier openapi.yaml décrit plus haut. Le connecteur du routeur se lie aux contrôleurs, nous y reviendrons.
Ensuite on a le fichier point de départ : index.js, que l’on placera dans un répertoire /src, du coup n’oubliez pas de modifier package.json avec la propriété main :
"main": "./src/index",
Ainsi que la commande start, celle ci se lancerait avec un npm run start mais vous pourriez avoir une surprise, via un Git Bash sur Windows, d’avoir une erreur sur le ./
"scripts": {
"start": "./src/index.js",
Dans ce fichier index.js on aura un appel au précédent fichier de config.
const makeApp = require('./makeApp')
const port = 3000;
makeApp()
.then(app => app.listen(port))
.then(() => {
console.log(`App running on port ${port}...`)
})
.catch(err => {
console.error('caught error', err)
})
Le contrôleur
Nous avons vu que le serveur se lie aux contrôleurs, il est maintenant temps de nous y intéresser. Nous allons créer un répertoire controllers dans /src, et un fichier item.js permettant de regrouper par domaine les actions concernant les items. À côté on créer un fichier index.js permettant de lister le contenu du répertoire au niveau de l’appelant, une façon de faire également utilisée en typescript/Angular.
On peut voir la fonction getItems dont le nom match l’attribut operationId du fichier openapi.yaml. Évidemment c’est voulu 🙂 Et c’est important de garder ça à l’œil quand vous préparez votre YAML. Actuellement la méthode renvoie un tableau vide.
Compléter le serveur
Avant de vouloir tester il nous manque un morceau, en fait plusieurs petits détails. Pour faire des appels à notre API, depuis notre poste, on aura un soucis de CORS, mais aussi, potentiellement de cache (en-tête etag) et d’url encoding. À cela on veut préciser que l’on traitera du JSON dans les échanges.
Pour tester on peut lancer le serveur avec : node src/index.js
On peut ouvrir un Bash et lancer un curl de test, tel que :
$ curl -s localhost:3000/api/v1/items
[]
Du coup bonne nouvelle on a quelque chose qui fonctionne et répond correctement, à savoir une réponse d’un tableau vide ([]). Pour le fun on peut structurer une donnée et la renvoyer, en respectant le modèle proposé dans le YAML.
Ensuite on va ajouter les lignes suivantes dans notre makeApp.js, l’une dans les déclarations, l’autre après les options afin de déclarer une route de documentation et lancer Swagger.
const express = require('express')
const swaggerUi = require("swagger-ui-express");
...
// This is the endpoint that will display the swagger docs
app.use("/api-docs", swaggerUi.serve, swaggerUi.setup(apiDescription));
Couper/relancer le serveur et rendez-vous sur l’url localhost:3000/api-docs.
Et ensuite ?
À partir de là libre à vous de créer des services, connecter une base de données, gérer du fichier, etc.
Je sors d’une mission dans laquelle j’ai été amené à travailler avec PrimeNg, qui propose dans un même framework tout ce dont on a besoin. Évidemment c’est joli sur papier mais dans la réalité ce n’est pas le cas, PrimeNg souffre d’un manque de flexibilité, mais ils ont tous ce soucis, donc bon, on fait avec.
Mise en place
Ici je vais vous parler du cas des tableaux, plus précisément de la partie rendu et composant de cellule, ce que AG Grid propose mais pas PrimeNg. Donc à nous d’ajouter une couche. On va créer un projet de POC avec ce dont on aura besoin (vous avez node lts, npm et un angular/cli) :
ng new primeng-simple-table
cd primeng-simple-table
npm i primeng-lts primeicons --save
npm i primeflex --save
npm i @angular/cdk@12 --save
Dans notre app.module.ts on va ajouter l’import du TableModule
On va vider app.component.html, puis créer un composant qu’on va baptiser <simple-table> et dedans on va y mettre le code de base du tableau PrimeNg, dans sa version dynamique.
<p-table [columns]="cols" [value]="data" responsiveLayout="scroll">
<ng-template pTemplate="header" let-columns>
<tr>
<th *ngFor="let col of columns">
{{ col.header }}
</th>
</tr>
</ng-template>
<ng-template pTemplate="body" let-rowData let-columns="columns">
<tr>
<td *ngFor="let col of columns">
{{ rowData[col.field] }}
</td>
</tr>
</ng-template>
</p-table>
Notez les modifications de nom de variables et notre fichier .ts .
On compile, on regarde le résultat… vous n’avez pas grand chose !
Des colonnes dynamiques
On faisant un composant dynamique on perd la faculté de définir les colonnes manuellement, c’est le but, on veut un système générique qui le fasse pour nous suivant ce qu’on lui donne, on va lui donner le moyen de créer les colonnes désirées, et on va en profiter pour se créer un jeu de données pour les tests.
On se crée donc une interface de définition de colonne et on passera un tableau de ColumnDef à notre composant pour définir ce que nous voulons. Dans ce premier jet nous avons l’attribut de donnée à utiliser pour la cellule (field) et le titre de colonne (header).
Jeu de données
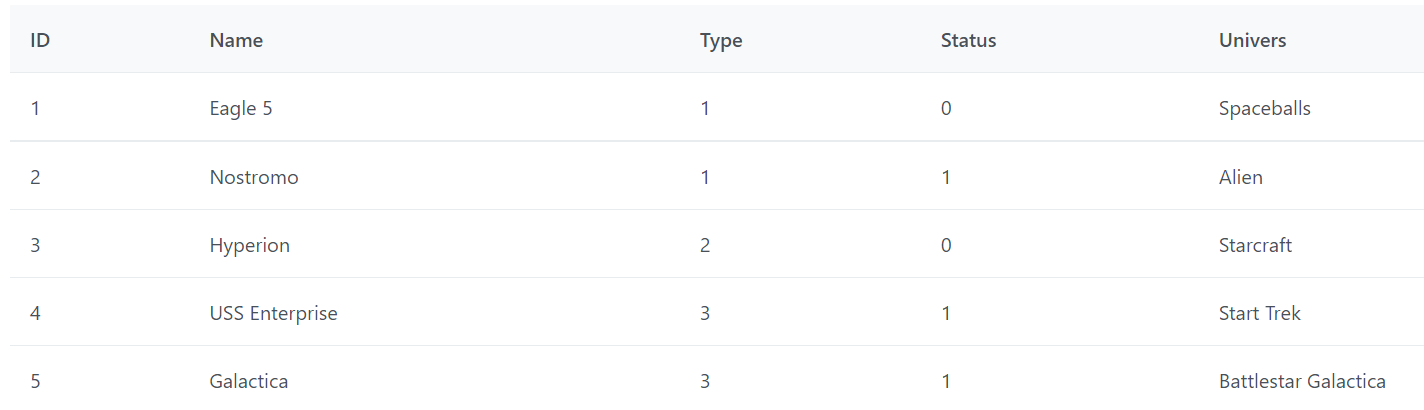
Avant de mettre en pratique et jouer avec un exemple nous allons nous créer un jeu de données, prenons des vaisseaux spatiaux, au grand hasard. Voici la structure utilisée, déposé dans un fichier annexe qu’on importera :
Sur base de notre jeu de données et de l’interface ColumnDef nous allons définir nos colonnes pour notre tableau. J’en profite pour typer les variables cols en fonction. Dans app.component.ts nous modifierons tel que :
Magnifique, jusque là on a pas fait grand chose, PrimeNg nous donne la solution et nous avons juste typé plus proprement l’attribut column qu’ils proposent.
Rendu de cellule
Maintenant que nous avons une démo qui fonctionne avec des colonnes dynamiques, voyons ce qu’est le rendu de cellule qui nous manque. Prenez un premier cas avec la valeur status de notre jeu de données, nous voulons afficher un texte compréhensible, et non la valeur de l’enum, en fonction de l’état du vaisseau.
De base rien ne nous le permet, regardez la partie {{ rowData[col.field] }}, ceci ne fait qu’imprimer la valeur de l’attribut courant. Il faut se mettre entre la valeur et son rendu. Une solution : une méthode intermédiaire, optionnelle, et variable s’il vous plaît. Pour ce faire nous allons ajouter un attribut à notre interface ColumnDef.
Désormais on peut lui donner une fonction qui recevra en paramètre l’entièreté des données de la ligne courante ainsi que le champs courant à rendre. Modifions notre définition pour cette colonne :
Jusque là ça ne change rien, il nous faut l’appliquer. Pour ce faire il y a 2 chose : que faire de ceux qui n’ont pas de méthode définie, et comment appliquer cette méthode. Pour la première partie nous allons définir une méthode par défaut sous forme de service et l’appliquer à la place de l’utilisateur à l’initialisation du composant. Pour la seconde nous utiliserons un container et la propriété [innerHTML].
Le service
Ce service contiendrait les solutions fournies de base, rien ne sert de réinventer la roue à chaque projet :).
import { Injectable } from "@angular/core"
@Injectable({
providedIn: 'root'
})
export class CellRenderer {
static none(rowData: any, field: string): string {
const value: any = rowData ? rowData[field] : false
if (value || value === 0) {
return value
}
return ''
}
}
Modification de l’@Input cols
On transforme notre variable en privée avec setter/getter pour avoir la main dessus en cas de modifications et pouvoir ainsi mettre les valeurs par défaut. On aide ainsi l’utilisateur de notre service à ne pas se casser la tête avec toutes nos options :).
Il ne nous reste qu’à modifier notre rendu de valeur au sein de la cellule.
<td *ngFor="let col of columns">
<div [outerHTML]="col.renderer(rowData, col.field)"></div>
</td>
Et nous voilà avec un rendu de cellule dynamique. Ceci n’est qu’un exemple, ce qui m’est arrivé le plus souvent étant une transformation de valeur booléenne ou de date partant d’un format variable (2022-03-15 ou un timestamp) pour aller vers une représentation francophone (15/03/2022). Dans le cas de la date, la fonction du CellRenderer appel un service spécifique central, qui pourra être appellé par un pipe ou autre service.
Composant de cellule
Au lieu d’une modification de texte, nous souhaitons parfois avoir un comportement, une interaction, avec la donnée ou la ligne, tel qu’un bouton, une liste ou autre type de composant. Ceux-ci ont des paramètres et des événements et il faut arriver à les glisser dynamiquement dans une cellule.
Nous allons jouer avec la colonne type en modifiant data pour l’exemple et voir comment un rendu de cellule aurait pu nous aider (ce n’est pas la seule solution).
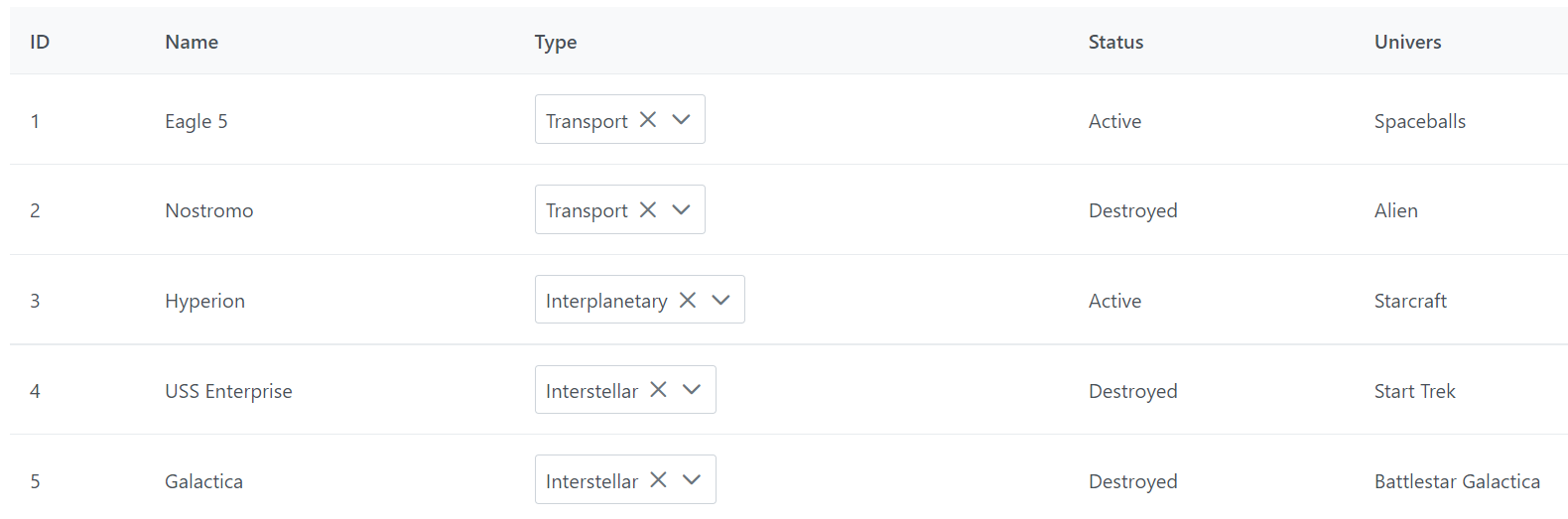
Mais ici on va directement attaquer un gros morceau en transformant cette cellule en liste déroulante pour modifier le type du vaisseau, soyons fou. Pour ce faire il va nous falloir plusieurs morceaux :
Définir ce qu’est un composant par des interfaces,
Modifier l’interface ColumnDef pour ajouter une définition pour composant,
Créer le composant liste
Décrire une mécanique permettant d’insérer un composant au sein de la cellule,
Modifier le rendu de la cellule pour détecter s’il s’agit d’un composant ou d’un renderer.
Modifier la définition des colonnes pour intégrer les changements
Création des interfaces
De quoi avons-nous besoin ? De dire quel composant il s’agit, de pouvoir lui passer des options et de lui donner le moyen de nous revenir par des événements.
export interface CellComponent {
component: any
options?: any
events?: any
}
Jusque là c’est assez générique, on lui dit qu’on pourra faire quelque chose, fort optionnel, et on spécifiera avec notre cas d’usage : une liste.
On aura besoin de lui donner la liste des options de la liste déroulante, et quel attribut utiliser comme valeur et comme texte à afficher. En retour nous serons alerté en cas de changement en nous retournant l’événement original du composant, ainsi que les données de la ligne et la colonne courante, ça peut toujours servir de donner les infos que l’on a.
Modification de l’interface ColumnDef
Comme nous avons nos types nous pouvons maintenant modifier notre interface de départ pour ajouter l’option composant.
Au pluriel car une colonne pourrait contenir plus d’un bouton par exemple, laissons de la flexibilité.
Créer le composant liste
Dans un répertoire /components/cell-components j’ai créé le composant list. Nous nous baserons sur le composant Dropdown de PrimeNg, avec leur exemple custom content, ce n’est pas obligé, mais si vous allez dans le détail ça sera plus facile d’avoir déjà la main sur le rendu via les templates. Du coup en avant dans l’HTML. N’oublier pas d’ajouter DropdownModule et ses dépendances.
Sur base de l’exemple qui parle de country, j’ai mis les nommer les variables que l’on va définir et nettoyer l’exemple, les détails comptent. La suite se passe dans le fichier .ts pour définir tout ce beau monde.
@Component({
selector: 'cc-list',
templateUrl: './list.component.html'
})
export class ListComponent implements OnInit {
// Must be in a parent class
options?: CellComponentOptionsList // Specific to list, any for generic
events?: CellComponentEventsList
rowData!: any
field!: string
// Specific to list
items: any[] = []
itemValue!: string
itemLabel!: string
value?: string
ngOnInit(): void {
}
}
Alors d’abord, si on avait plusieurs composant de cellule on aurait forcément une classe parente avec la partie commune, pour ce POC j’ai regroupé et annoté. Ensuite, vu qu’on viendra d’une cellule il sera normal et attendu que l’on passe ce que la cellule a à nous donner, à savoir rowData et field, ainsi que la définition spécifique à notre composant (options et events), venant de la config dans ColumnDef. Enfin, comme définit dans nos interfaces, les particularités spécifiques à la liste (items, itemValue et itemLabel). Notez encore la propriété value qui contiendra le choix courant et qui sera utilisé dans l’événement change.
Tel quel, le composant ne fera qu’exister avec une liste vide et les paramètres non-défini. Nous les ajouterons après pour que vous compreniez d’abord bien le chainage des attributs et les affectations. Restons simple, ça se complexifiera vite assez.
La mécanique d’insertion du composant dans la cellule
C’est là tout le truc, en un point du code HTML on doit dire à Angular : « je veux mon composant là et que tu le raccordes à mes options, événements, … ». Pour ce faire on va passer par une directive qui jouera le rôle d’hôte.
Pour faire simple, cette directive récupère ce qu’on lui passe sous forme d’attributs : cellComponentsHost, rowData et field. Attention au casting ListComponent, là c’est la classe parent que l’on indique normalement. Ensuite elle crée le composant et le place dans le container sur lequel est placé la directive. N’oubliez pas de la déclarer.
<td *ngFor="let col of columns">
<ng-container *ngIf="!col.components"><div [outerHTML]="col.renderer(rowData, col.field)"></div></ng-container>
<ng-container *ngIf="col.components" [cellComponentsHost]="col.components" [rowData]="rowData" [field]="col.field"></ng-container>
</td>
Pas de chipotage, on encapsule notre rendu de cellule précédent dans un container conditionnel, dans l’autre on y retrouve notre directive et les attributs qu’on lui passe.
On lui indique donc le composant voulu et nos options, jusque là vous devriez pouvoir faire les liens :), et on sort en console pour vérifier que l’évent a donné quelque chose.
Compléter le composant liste
Nous avons une interface de définition et nous avons définit notre cas d’utilisation sur la colonne type. Ensuite, nous avons créé le composant sans l’implémenter, ainsi que la directive hôte. Enfin, nous avons mis en place l’usage de la directive. On pourrait tracer le cheminement ainsi :
Le tableau boucle sur les colonnes pour créer une ligne.
Il arrive sur une cellule et se pose la question : est-ce un composant ou non ?
Si non : il tente le rendu de cellule (none par défaut)
Si oui :
La directive est fournie des informations et se lance pour créer chaque composants demandés en son seing
Le composant nouvellement créé est prêt
Il est prêt ? Qu’est-ce que cela veut dire ? On a parlé de compléter le composant pourtant :/ … et en effet on pourrait s’arrêter là et utiliser options directement, excepter le onChange manquant, mais nous désirons peut-être appliquer des contrôles ou des détections préliminaires, et dans cette idée je vais vous montrer une possibilité.
Il est beau, il est joli, mais est-ce tout ? Seule l’imagination étant notre limite, la réponse évident est : non ! Tout dépend de votre besoin, de vos envies de flexibilités, de ce que vous souhaitez proposer. Pour ma part voici des pistes abordées et développées :
Reporter les options fournies par p-table
Ce n’est pas une évidence pour tout le monde, mais en dehors des choix fait pour votre composant (imposer le scroll, le système de colonnes, …) vous bloquez l’accès aux autres options proposées par p-table, du coup ceux qui veulent utiliser votre composant vont être bloqués/frustrés. Une bonne pratique est de faire des ponts pour reporter ces options autant que possible, merci le code source de la lib pour vous aider.
Ligne de filtres
PrimeNg permet d’ajouter des filtres mais en dynamique il vous faudra user d’une autre directive hôte et d’une interface, sans oublie l’@Input pour passer votre demande au composant.
Sélection
PrimeNg permet également de mettre en place un système de sélection de ligne(s), mais vu notre côté dynamique c’est à nous de réintégrer cette solution, de manière optionnelle. Ceci sous-entend d’ajouter des colonnes de sélection et de donner à p-table la configuration (none, single, multiple)
Classes CSS
On l’oublie souvent, mais le design ! Du coup vous voulez préciser pour telle colonne un style (classe CSS), il faudra faire évoluer la définition de colonnes et modifier l’HTML de notre composant pour l’intégrer dans la partie template, tant sur l’en-tête que sur la cellule. On peut également imaginer que l’en-tête et la cellule peuvent avoir des styles différents (couleur, alignement, …).
Le composant liste
Notre composant liste peut également être poussé plus loin, en activant le filtre et/ou en améliorant le rendu pour afficher un contenu plus complexe comme un préfix à la valeur, ce qui m’est souvent arrivé : [PRE – valeur affichée] .
Suite à un passage à Middelkerke et l’envie de me remettre à la création de modèle Lego, je me suis lancé le défi d’un building. Évidemment, avec les contraintes de briques existantes et disponibles chez Lego, pareil pour les couleurs, un vrai calvaire, et en faisant l’essai des Modular.
L’idée est donc de reproduire l’aile droite de la résidence Martiny, son espace commercial que l’on considérera comme un vendeur de granitas, glaces et glaçons, et les étages, parties des appartements.
Côté Lego on part sur une plaque 16×16 avec des couleurs au plus proche. On remarque tout de suite que la fenêtre de gauche n’est pas possible vu les pièces disponibles et que la fenêtre latérale sera plus large que prévu. Le balcon sera adapté en conséquence.
Building granita
La modélisation a été faite avec Studio 2 et avec beaucoup de recherches, notamment sur Bricklink pour les références des pièces existantes chez Lego actuellement, ainsi que sur d’autres sites de références sur les couleurs Lego.
Granita vue du dessus
La première rangée est composée d’un frigo à glaçons (popsicle), d’un distributeur de granita 4 bacs et d’un meuble à verres + plante déco et un affichage de prix au dessus. Ensuite on a le comptoir avec la caisse et le meuble à glaces 4 bacs. On peut également voir le carrelage en damier noir et blanc côté « cuisine » avec des points d’accroche, et côté entrée un carrelage stylisé gris et blanc en triangles et lignes. On ne les voit pas bien mais au mur, carré bleu, c’est un équivalent des prix et promos du jour. Il y a également une grande plante en vase pour décorer.
Façade avant avec et sans éléments extérieurs
Un panneau publicitaire double-face inspiré du modèle 60203, une machine à tchiniss/un distributeur de bêtises et une poubelle inspirée/reprise de la station essence Octan de 2001.
Premier étage de notre building, une réplique modifiée de celui que nous avions loué, les proportions sont respectées. Un meuble TV avec 2 portes (figées), un petit écran plat, fauteuil, canapé, table basse et lampe halogène sur pied. Le sol représente un carrelage clair en longueur. L’anecdote malencontreuse est que les « roof tile 1×1 » gris foncé n’existent pas en gris clair prévu initialement, j’ai donc tenté cette modification.
Pour des exemples de fauteuil etc, une recherche google « lego sofa » vous donnera un tas de bons conseils et d’exemples.
Le second étage avec une idée design moderne, avec écran géant plat et enceintes, éclairage mural et un ensemble canapé – table basse orange pétant, arrondi; sans oublier la plante ! Le sol est typé planché sombre.
L’angle pour montrer n’étant pas évident, voici un rendu Studio 2, ainsi vous pouvez admirer le beau carrelage et le tapis sous ce magnifique divan avec méridienne. La pièce est sobre, une étagère murale avec livres et sculpture/roche, des éclairages muraux spots directionnels et un télescope !
Et voilà ! Un building complet, dont le manuel fait 90 pages pour 194 étapes, et où le modèle compte plus de 1000 pièces !
Une suite ?
Effectivement, nous avons imaginé ajouter 2 étages pour lui donner de la verticalité. On cherche encore le style des 2 étages.
Serait-ce l’atelier d’un peintre ?
Un ensemble ?
Oui ! Ce building fait partie d’un projet plus grand qui se veut modulaire, c’est à dire utilisable dans son ensemble ou en partie.
Serait-ce un extrait de notre côte Belge ?
Je n’en dirais pas plus ici tant que ce n’est pas fini, ni plus réalisable.
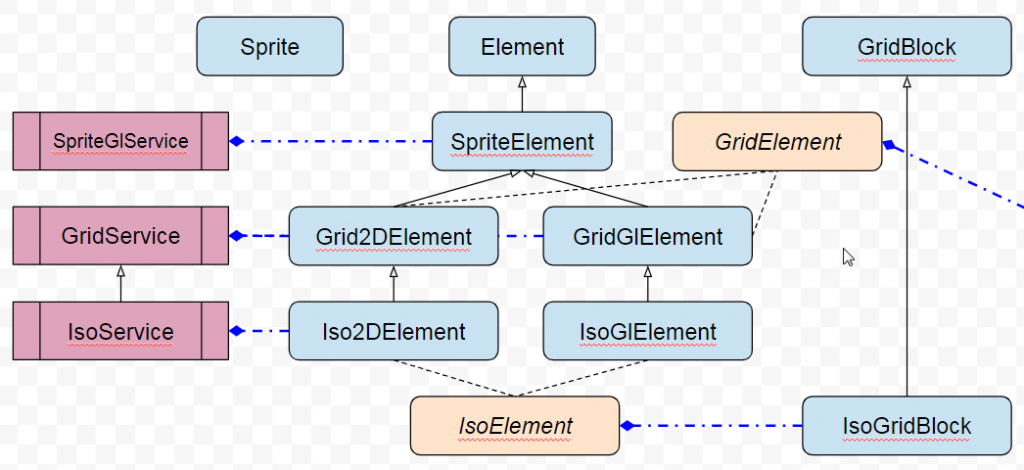
Suite à l’article précédent j’ai voulu faire un tour de nettoyage et je me suis rendu compte qu’un ancien démon revenait à la charge. Nous avons divisé le code par domaine et contexte de rendu, propre et héritant d’un parent commun, et dans un service je mets le code commun à ce qui concerne Grid, ou Iso etc., de manière à isoler les calculs de l’usage selon le contexte.
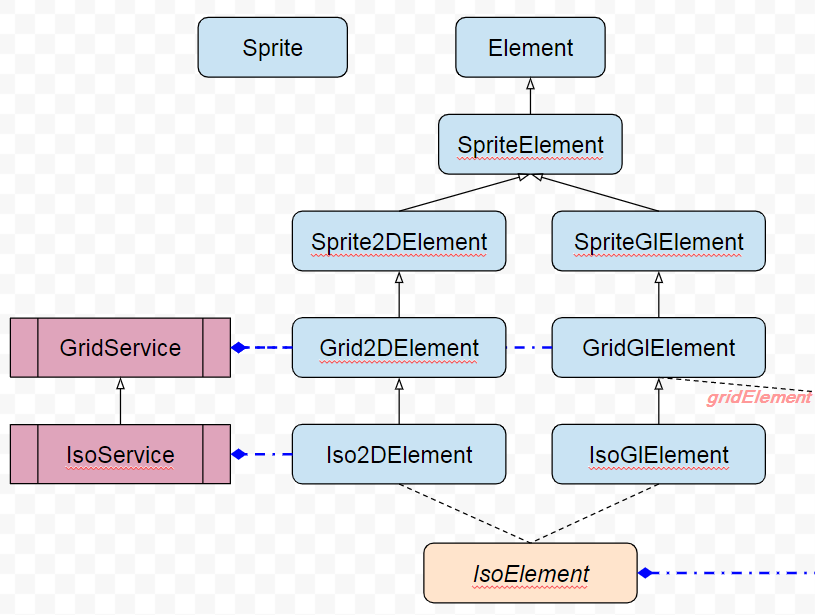
Schéma avant fusion
Plus simple avec un schéma, voici la découpe avant fusion. Ce qui nous intéresse c’est la séparation 2D et Gl, puis la découpe par usage/type à savoir Sprite, Grid ou Iso, puis les regroupements de type IsoElement/GridElement, ainsi que des services relatifs aux couches.
On a une sorte de matrice à 3 dimensions en ce qui concerne cette idée. Sauf que programmer ça, en TypeScript, ben c’est pas très évident. En PHP j’aurai pu utiliser des Traits, il existe des mixins en javascript mais non merci, je vous laisse vous faire votre avis mais ce n’est pas à la hauteur. L’héritage multiple n’existe pas (cf mixin), du coup il faut savoir se renouveler et faire preuve d’audace, d’expérimentation et de refontes inévitables. C’est ce que j’ai dû faire, non sans mal.
J’étais parti pour déplacer les fonctions de rendu dans les services par couche (Grid/Iso) et de fusionner Grid2DElement avec GridGlElement, vu que leur différence réside dans le contexte de rendu (2D/Gl). Mais je me suis aperçu que bien que je gagnais en clarté à tout regrouper, on augmentait d’autre part la difficulté de ce même code et des approches. Bref, bien, mais pas bien.
Du coup revirement de situation et revenons sur nos pas de plusieurs mois quand on a justement décidé de diviser par contexte de rendu, quand les lumières sont arrivées (la version solutionnée). Revenons donc à cette idée non divisée et sans emmerder les services déjà très bons tels quels.
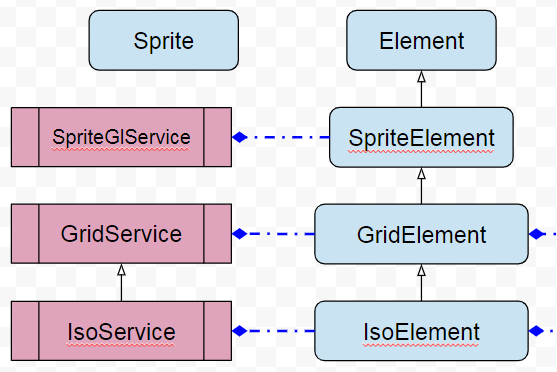
C’est la fusion !
Fusionner Grid2D et GridGl, Iso2D et IsoGl, ok, mais on oublie Sprite2D et SpriteGl qui héritent de SpriteElement, il faut commencer par le commencement. C’est donc une refonte jusqu’à Element pour répartir les morceaux des différentes classes Sprite*. Ainsi disparaissent Sprite2DElement et SpriteGlElement au profit d’une nouvelle classe SpriteElement toute équipée.
Quand on parle de fusion on parle bien entendu de gérer le contexte de rendu au sein même de la classe. Ceci peut paraître étrange et contre certains bons principes, mais ces morceaux de code partagent parfois jusqu’à 90% du code, ce qui va contre le principe DRY (Don’t Repeat Yourself) et comme j’ai envie de bisous (KISS : Keep It Stupid Simple), j’ai tout regroupé et cela ne m’a demandé que quelque if peu coûteux, ce qui est très important car on appelle ces bouts de code des centaines, des milliers de fois par seconde (selon complexité de votre projet).
Fusion de Sprite*Element
J’en profite pour illustrer le service de rendu Gl et montrer à partir d’où on le connecte. J’en affiche un peu plus mais ainsi on voit les 2 types de regroupement GridElement et IsoElement. Ne prêtez pas attention à GridBlock, vous le connaissez déjà.
Nous sommes bien parti, continuons. On crée une nouvelle classe GridElement et on met ce que contient Grid2D et GridGl, hop tout dedans et on essaye de faire coller les morceaux. Là où ça se corse c’est de bien segmenter les parties communes et spécifiques, puis quand on arrive à IsoElement c’est encore pire car nous sommes basé sur l’héritage donc on ne réécrit que ce qui a besoin de l’être et là on observe des couacs, des oublis pour la 2D vu qu’on s’est concentré sur Gl depuis les lumières. Par exemple la table en 2D ne fonctionne pas, juste en Gl.
Fusion terminée
Sur papier ça parait plus beau, naturel, élégant, [mettre ici tous les beaux mots que vous désirez]… Mais dans la pratique ça demande pas mal d’efforts, de compréhension, évidemment c’est pour un mieux !
C’est quand même un impact de 33 fichiers dans le projet et son POC de démo, 8 dans TARS même, ainsi que 8 suppressions et 2 ajouts. Ça c’est pour les fichiers, mais en terme de lignes de code, même si je n’ai pas de compteur à cet instant, on a effectué une réduction notable, donc plus facile à maintenir, de par le regroupement aussi.
Preuve que ça fonctionne toujours, même si la table n’est pas gérée encore correctement en 2D.
Garder 2D et Gl ?
Pourquoi garder les 2 ? Car il est très difficile de débuger en Gl, vous ne pouvez pas dessiner aisément un repère ou une trace sans sortir les chars d’assaut et beaucoup d’heures de dev alors qu’en 2D vous êtes libre de manipuler le rendu en direct et ce rapidement.
C’est pour cela que le POC (démo) n’utilise plus les lumières en 2D, le but pour moi ici étant un debug rapide sans ajouter des soucis de performances, qui plus est, connus.
De plus, maintenant que la fusion est faite, on pourrait revoir tout le workflow d’utilisation pour ne plus devoir faire (à l’usage) une scène 2D ou une scène Gl. ainsi en changeant juste le mode, toutes les classes personnelles seraient utilisables, ce qui serait un chouette gain de temps et d’effort. De plus les 2 fonctions ajoutées is2DContext/isGlContext permettent d’agir spécifiquement si besoin était.
Et le fameux ensuite ?
Ah ben oui, ensuite quoi ? Corriger le pourquoi de la table en 2D et tenter de régler un conflit Grid/Iso sur un calcul de positionnement.
Il faut absolument faire un POC purement Grid et non Iso, genre un Mario (S)NES ou Duke Nukem 1-2, un truc tout carré pour voir que les calculs sont bons, juste une grille décorée, pas plus.
Ensuite, mes fameuses particules lumineuses et le miroir :p !
Mais bon, comme d’hab on verra ce qui me stitch comme on dit. Je vais déjà de ce pas fusionner les branches du repo et repartir sur une base saine :).
Edit
Pour ne pas refaire un article juste pour ça, j’ai également fusionné les classes du POC (treasure, door, player), leur code était identique. 3 classes de moins sur les 6 initiales (3x2D et 3xGl). Une bonne chose de faites qui va nous simplifier la vie ultérieurement. Les scènes restent dissociées car différentes, la Gl, plus complète, gère la lumière par exemple, les fusionner ne donnerait rien d’intéressant une fois en release. Au moins le debug (2D) peut se faire sans gêner le résultat final (Gl). Nous voilà dans un état propre, quelques corrections de bugs ou de manques seraient à faire pour solidifier avant d’avancer plus.
Tel Stanley Ipkiss, TARS joue maintenant avec un masque lors des rendus d’objets occupant plusieurs cases dans notre contexte isométrique. Mais pourquoi ?
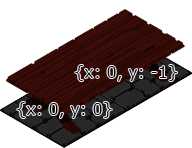
La table passe sur le Héro car elle est rendue après.
C’est là qu’il faut vous expliquer comment ça fonctionne, ce qui n’est pas une mince affaire. La table occupe 2 cases, mais comme tout Element, il a une coordonnée qui ici nous dit {x: 8, y: 2} (rappel on commence à zéro) et notre Héro, lui, arrive sur la case {x: 9, y: 1}, ce qui de part notre mécanique de rendu Isométrique dessine le Héro avant la table et donc la table écrase le dessin du Héro. Vous suivez jusque là ?
Ceci illustre bien l’ordre de rendu (dessin), de haut gauche, vers la droite jusqu’en fin de ligne, on passe à la ligne suivante et on repart de gauche à droite.
1 problème ?
On a donc un problème, le Héro devrait être dessiné devant la table, ce qui correspond à notre logique visuelle. Même si on inverse le sens de dessin, en colonne au lieu de ligne, on aura le même soucis avec l’autre table.
Après de longues recherches et essais, une seule solution : la manifestation ! découper l’image en 2 pour occuper chacune une case. Car le problème n’est pas que cette erreur de dessin mais aussi le pathfinder qui passe au travers de la case qui n’est pas affectée (en mémoire), elle ne l’est que par vos yeux; et enfin la lumière qui voit la table tantôt d’un bout (loin), tantôt de l’autre bout (proche) et donc l’éclaire différemment.
3 problèmes ?
Le pathfinder se base sur la présence d’un Element sur la grille que l’on fabrique sur base du subsetMap, et la lumière, chacun ayant son algorithme. Le rendu se base directement sur la subsetMap. On serait tenté de dire qu’il faut solutionner les 3 individuellement et c’est ainsi que j’avais commencé.
J’ai donc ajouté une notion d’additionnalCoords (coordonnées additionnelles) dans la définition de l’élément table et ce pour les 4 orientations NESW, décrivant, dans le cas de notre table orientée vers le Nord et dont la base se trouve en bas gauche de l’image, une case additionnelle en x: 0, y: -1.
Le choix de la coordonnées {0,0} vient du sens de rendu et du sens de détection du raycasting quand on clic droit sur un Element (coffre, porte). La dernière case dominera les précédentes comme démontré par le problème. Le raycasting parcours l’inverse du rendu pour trouver l’élément le plus devant. Notre {0,0} sera donc cette dernière case a être rendue et correspondra à la coordonnée de l’Element, les additionalCoords représente l’ensemble des autres cases en mode relatif (ex: {x: -1, y: 0} pour la table orientée vers l’Est).
Raycasting ? 4 problèmes donc ?!
Maintenant que vous comprenez la structure, le pourquoi du comment et la mécanique céleste, nous allons tenter de corriger les problèmes un à un.
Le plus facile est le pathfinder, qui se base sur des cases occupées pour dire que l’on ne peut s’y rendre. Actuellement le Héro se déplace sur la seconde case de la table « dessous » car la table se dessine après. Il faut donc arriver à lui dire « hey tiens voilà des coordonnées additionnelles à retirer !« .
Aussitôt dit, aussitôt fait, quand on prépare le pathfinder sur base de la subsetMap, on demande à tous les Elements s’ils ont des coordonnées additionnelles et ensuite on les retire du résultat final.
Fin ! 8D
Ah ah ah Oui mais non ! Ça fonctionne, certes, le Héro ne traverse plus les tables, ce n’est plus un drôle de fantôme. Mais ! La lumière n’est pas bonne, le raycasting reste un problème et évidemment notre problème de rendu reste identique, la table passe devant le Héro.
J’ai tenté une théorie visant à dire au GridBlock de prendre en compte des pointeurs, une forme de référence entre cases, mais en vain. Un GridBlock est un multi-ensemble d’Elements, point.
Je vous épargne toute la frustration et brisage de méninges, il m’aura fallu une bonne semaine pour trouver la seule piste envisageable.
Un système de masque
Dit comme ça, ça semble être la solution ultime, et c’est pas loin, mais incomplet. On garde les additionnalCoords et on s’en sert à l’ajout de l’Element sur la Map lors du chargement pour l’ajouter à chacune des cases, le même élément (la même instance, pas une copie). Notre table est donc physiquement présente en mémoire sur 2 cases.
Cela résout le problème de pathfinder et on peut retirer ce que nous avons fait précédemment. Le raycasting est aidé par cette approche mais il faudra l’aider (cf le rendu), nous verrons ça en fin d’article. Il nous reste la lumière et le rendu.
Table ajoutée 2 fois sur la coordonnée de l’Element au lieu des cases spécifiques.
Chacune des 2 cases de la table rend la même image, donc elle « fusionnent » visuellement.
L’idée du masque est de dessiner une partie de l’image sur chaque case correspondante, évitant de demander au graphiste de préparer un grand nombre d’images individuelles et de devoir se battre avec son éditeur de map, ce qui n’est pas gérable.
Chaque case correspond à un rendu à faire, la zone bleue donne B et la zone orange donne A.
Modification du système de rendu
Dans le cas où notre Element a des additionnalCoords il faut appliquer le masque, sinon le rendu classique qui va bien. Pour y arriver, il nous manque quelque chose, comment savoir quelle partie dessiner ? Actuellement nous dessinons selon la coordonnée de l’Element, du coup dans ce cas on dessine une table entière selon ses coordonnées ce qui donne l’effet de fusion illustré ci-avant.
Pour changer ça, il faut dire à notre système de rendu que ce n’est pas la coordonnée de l’Element qu’il faut utiliser, grosso modo. On va commencer par ajouter la notion de coordonnées au gridBlock, qui n’en avait pas besoin jusque là. Et qu’ils passent cette coordonnée à la fonction draw() pour que l’information arrive au système de rendu.
Et après on fait comment ? On se questionne, a-t-on des additionnalCoords ? Si oui, à laquelle correspond le x,y donné par le rendu ? De la on calcul un masque prenant en compte le déplacement dans l’image pour n’afficher que ce qui nous intéresse dans notre cas. Illustrons ça avec la conquête des erreurs de rendu.
Il y a bien un rendu par case, en ayant forcé la largeur de la source à une largeur de case, mais en ayant oublié la déformation de destination.
Correction de la destination, tout le monde à une case de largeur.
Premier résultat concluant.
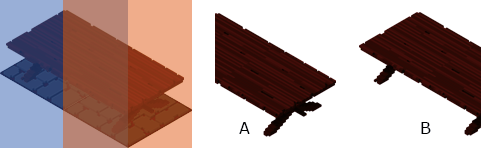
Le Héro ne passe plus derrière la table ! Mais ?! Qu’est-ce-que c’est que cette drôle de table coupée ? On a un soucis, ok mais lequel ? On dirait que la « fenêtre » du masque n’est pas au bon endroit, mais pourquoi que dans la table orientée à l’Est (à gauche) ?
Pour déterminer ce qu’il se passe, j’ai essayé de dessiner le premier morceau, et on voit que le même problème apparait.
Tentons de voir à quoi ressemble chaque morceau sans considérer la case originale. Nous n’avons pas le même résultat, en vert on a une fenêtre aux bonnes dimensions et bien positionnée, en rouge non.
Pour tenter de comprendre, j’ai modifié la table Est en inversant son origine (en haut gauche au lieu de bas droite) et en modifiant son rendu. J’ai également ajouté un fond à l’image pour comprendre les dimensions gérées.
Inversons le rendu et affichons un fond à la transparence.
En rendu inversé pour la table Est ça fonctionne ! Mais pourquoi ? Qu’est-ce qui change ? Et là une théorie survient, le fait que la base soit au delà d’une distance de case dans l’image quand on calcule le masque, provoque ce décalage. Je vais vous passer les calculs et les correctifs spécifiques au masque, mais en résumé, on doit déplacer la coordonnée source dans l’image selon la théorie isométrique (par demi case en X/Y) mais aussi corriger le résultat par cette même théorie, car il faut rationaliser ce décalage au delà d’une distance d’une case. De plus ce dernier correctif doit être appliqué à l’inverse au positionnement de destination. J’ai tenté un dessin, mais même pour moi il n’a pas été simple de le schématiser pour le coder.
Résultat corrigé du rendu.
On a donc notre Héro devant la table, des tables bien positionnées (celle de l’Est a été déplacée pour les tests) et on a en même temps solutionné la lumière qui éclaire équitablement les 2 morceaux. Ceci est un effet de bord qui tombe à point et qui se base sur le fait que c’est la même instance du même Element qui est référencé dans les 2 cases et donc quand la lumière s’applique, c’est le plus proche qui est choisi et appliqué, par effet de propagation. Enfin, c’est ma déduction car je ne me suis pas amusé à le démontrer.
Bon ok j’ai regardé un petit peu en écrivant ces lignes, il se pourrait que la table aie une addition de quantité d’éclairage par case, il faudra donc vérifier ça et décider du comportement. Vu les formes découpées, je ne suis pas sûr qu’un éclairage non uni soit une bonne idée.
Et le raycasting ?
On y vient, comme dit plus haut, c’est ici que ça se passe. On est vite tenté de dire qu’on a fini car nos problèmes visuels s’en sont allés, mais que nenni, il nous en reste un beaucoup moins visible : le raycasting. Pour ceux qui n’ont pas suivi, le raycasting (lancé de rayon), permet de déterminer dans notre cas ce sur quoi on clic (quand on clic droit sur le coffre, la porte, ou même un arbre).
Donc ici, pour chaque case, il se croit être à l’origine et m’est avis que ça va pas nous aider. Il va falloir, car ce n’est point encore fait, lui expliquer à lui aussi le système de masque. Par extension, on pourra peut-être globaliser et « simplifier ».
Prochaines étapes
En me relisant, je remarque que je parle souvent de l’éditeur mais pas cette fois; ni du jeu que nous allons démarrer comme projet vivant de l’usage de notre moteur TARS, et oui toujours dans le monde de Nahyan, nous y reviendrons prochainement; Mais plutôt vous parler de système de particules et de miroirs qui me sont venu à l’esprit et tant qu’à faire, une démo technique avec une petite explosion dont chaque particule est luminescente et se reflète dans des miroirs…