Suite à l’article précédent j’ai voulu faire un tour de nettoyage et je me suis rendu compte qu’un ancien démon revenait à la charge. Nous avons divisé le code par domaine et contexte de rendu, propre et héritant d’un parent commun, et dans un service je mets le code commun à ce qui concerne Grid, ou Iso etc., de manière à isoler les calculs de l’usage selon le contexte.
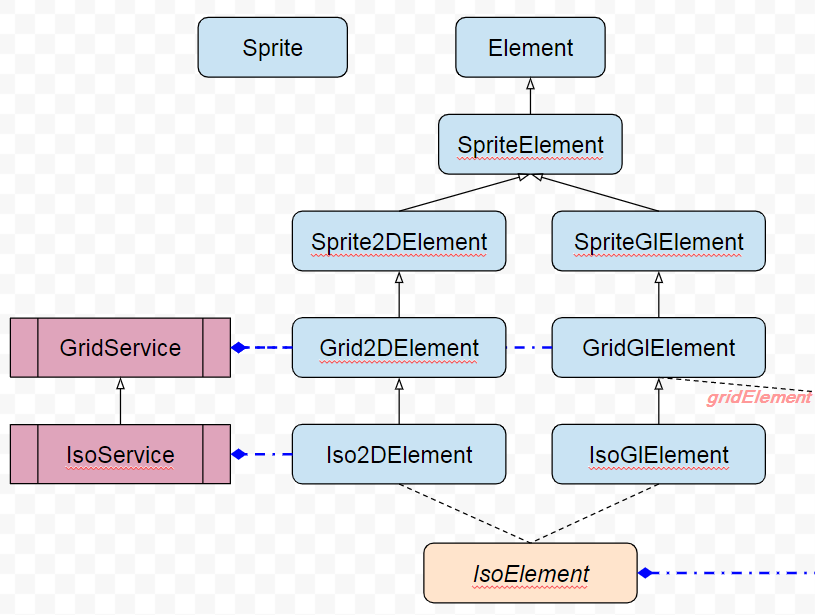
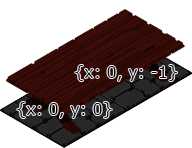
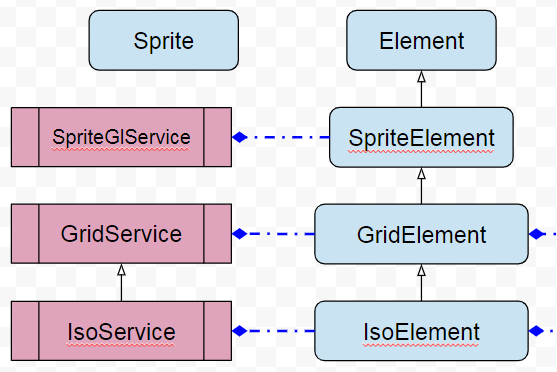
Plus simple avec un schéma, voici la découpe avant fusion. Ce qui nous intéresse c’est la séparation 2D et Gl, puis la découpe par usage/type à savoir Sprite, Grid ou Iso, puis les regroupements de type IsoElement/GridElement, ainsi que des services relatifs aux couches.
On a une sorte de matrice à 3 dimensions en ce qui concerne cette idée. Sauf que programmer ça, en TypeScript, ben c’est pas très évident. En PHP j’aurai pu utiliser des Traits, il existe des mixins en javascript mais non merci, je vous laisse vous faire votre avis mais ce n’est pas à la hauteur. L’héritage multiple n’existe pas (cf mixin), du coup il faut savoir se renouveler et faire preuve d’audace, d’expérimentation et de refontes inévitables. C’est ce que j’ai dû faire, non sans mal.
J’étais parti pour déplacer les fonctions de rendu dans les services par couche (Grid/Iso) et de fusionner Grid2DElement avec GridGlElement, vu que leur différence réside dans le contexte de rendu (2D/Gl). Mais je me suis aperçu que bien que je gagnais en clarté à tout regrouper, on augmentait d’autre part la difficulté de ce même code et des approches. Bref, bien, mais pas bien.
Du coup revirement de situation et revenons sur nos pas de plusieurs mois quand on a justement décidé de diviser par contexte de rendu, quand les lumières sont arrivées (la version solutionnée). Revenons donc à cette idée non divisée et sans emmerder les services déjà très bons tels quels.
C’est la fusion !
Fusionner Grid2D et GridGl, Iso2D et IsoGl, ok, mais on oublie Sprite2D et SpriteGl qui héritent de SpriteElement, il faut commencer par le commencement. C’est donc une refonte jusqu’à Element pour répartir les morceaux des différentes classes Sprite*. Ainsi disparaissent Sprite2DElement et SpriteGlElement au profit d’une nouvelle classe SpriteElement toute équipée.
Quand on parle de fusion on parle bien entendu de gérer le contexte de rendu au sein même de la classe. Ceci peut paraître étrange et contre certains bons principes, mais ces morceaux de code partagent parfois jusqu’à 90% du code, ce qui va contre le principe DRY (Don’t Repeat Yourself) et comme j’ai envie de bisous (KISS : Keep It Stupid Simple), j’ai tout regroupé et cela ne m’a demandé que quelque if peu coûteux, ce qui est très important car on appelle ces bouts de code des centaines, des milliers de fois par seconde (selon complexité de votre projet).
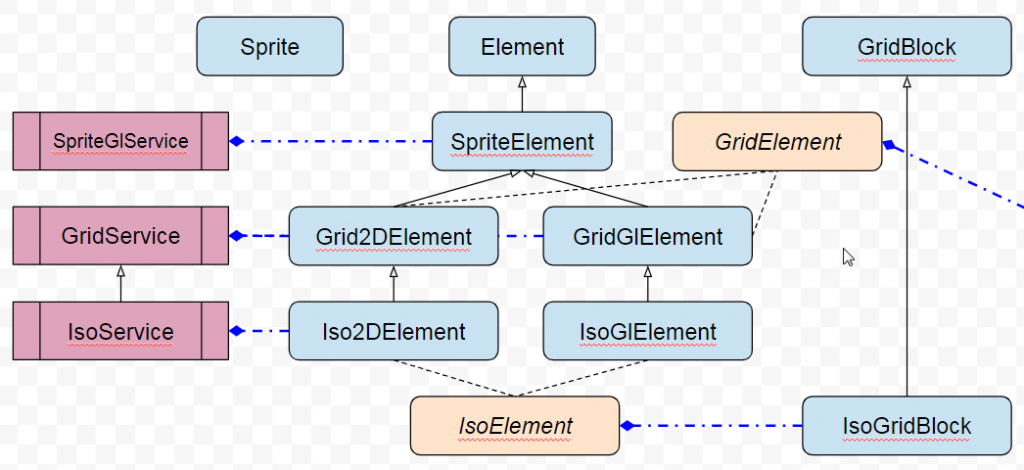
J’en profite pour illustrer le service de rendu Gl et montrer à partir d’où on le connecte. J’en affiche un peu plus mais ainsi on voit les 2 types de regroupement GridElement et IsoElement. Ne prêtez pas attention à GridBlock, vous le connaissez déjà.
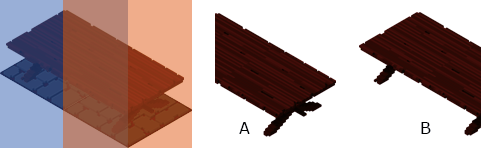
Nous sommes bien parti, continuons. On crée une nouvelle classe GridElement et on met ce que contient Grid2D et GridGl, hop tout dedans et on essaye de faire coller les morceaux. Là où ça se corse c’est de bien segmenter les parties communes et spécifiques, puis quand on arrive à IsoElement c’est encore pire car nous sommes basé sur l’héritage donc on ne réécrit que ce qui a besoin de l’être et là on observe des couacs, des oublis pour la 2D vu qu’on s’est concentré sur Gl depuis les lumières. Par exemple la table en 2D ne fonctionne pas, juste en Gl.
Sur papier ça parait plus beau, naturel, élégant, [mettre ici tous les beaux mots que vous désirez]… Mais dans la pratique ça demande pas mal d’efforts, de compréhension, évidemment c’est pour un mieux !
C’est quand même un impact de 33 fichiers dans le projet et son POC de démo, 8 dans TARS même, ainsi que 8 suppressions et 2 ajouts. Ça c’est pour les fichiers, mais en terme de lignes de code, même si je n’ai pas de compteur à cet instant, on a effectué une réduction notable, donc plus facile à maintenir, de par le regroupement aussi.

Garder 2D et Gl ?
Pourquoi garder les 2 ? Car il est très difficile de débuger en Gl, vous ne pouvez pas dessiner aisément un repère ou une trace sans sortir les chars d’assaut et beaucoup d’heures de dev alors qu’en 2D vous êtes libre de manipuler le rendu en direct et ce rapidement.
C’est pour cela que le POC (démo) n’utilise plus les lumières en 2D, le but pour moi ici étant un debug rapide sans ajouter des soucis de performances, qui plus est, connus.
De plus, maintenant que la fusion est faite, on pourrait revoir tout le workflow d’utilisation pour ne plus devoir faire (à l’usage) une scène 2D ou une scène Gl. ainsi en changeant juste le mode, toutes les classes personnelles seraient utilisables, ce qui serait un chouette gain de temps et d’effort. De plus les 2 fonctions ajoutées is2DContext/isGlContext permettent d’agir spécifiquement si besoin était.
Et le fameux ensuite ?
Ah ben oui, ensuite quoi ? Corriger le pourquoi de la table en 2D et tenter de régler un conflit Grid/Iso sur un calcul de positionnement.
Il faut absolument faire un POC purement Grid et non Iso, genre un Mario (S)NES ou Duke Nukem 1-2, un truc tout carré pour voir que les calculs sont bons, juste une grille décorée, pas plus.
Ensuite, mes fameuses particules lumineuses et le miroir :p !
Mais bon, comme d’hab on verra ce qui me stitch comme on dit. Je vais déjà de ce pas fusionner les branches du repo et repartir sur une base saine :).
Edit
Pour ne pas refaire un article juste pour ça, j’ai également fusionné les classes du POC (treasure, door, player), leur code était identique. 3 classes de moins sur les 6 initiales (3x2D et 3xGl). Une bonne chose de faites qui va nous simplifier la vie ultérieurement. Les scènes restent dissociées car différentes, la Gl, plus complète, gère la lumière par exemple, les fusionner ne donnerait rien d’intéressant une fois en release. Au moins le debug (2D) peut se faire sans gêner le résultat final (Gl). Nous voilà dans un état propre, quelques corrections de bugs ou de manques seraient à faire pour solidifier avant d’avancer plus.