Pas de révolution ici, c’est quelque chose somme toute d’assez classique, un back-end NodeJs en Express et une doc Swagger basé sur un OpenAPI. Le truc étant de faire le routage et la doc en un seul point, améliorant la maintenabilité et automatisant le routage.
Pour ce faire il suffit de démarrer un nouveau projet et d’installer quelques librairies de base :
npm init npm i express --save npm i swagger-parser --save npm i cors --save npm i swagger-routes-express --save
- Le framework express comme base,
- La lib swagger-parser pour lire et interpréter le fichier openapi.yaml (définition de l’API),
- La lib cors pour définir l’autorisation,
- La lib swagger-routes-express pour créer un connecteur reliant les contrôleurs au routeur basé sur la définition de l’API,
- La lib swagger-ui-express pour mettre à disposition un swagger de la définition de l’API, sur une route
/api-docs.
Maintenant qu’on a la base il nous faut le squelette d’application, du coup au lieu de taper tout le code ici je t’invite cher lecteur à te rendre sur ce GitHub, et nous allons détailler les parties intéressantes.
OpenAPI
D’abord, qu’est-ce que l’on veut accomplir ? Dans cet exemple on va simplement faire un service REST pour obtenir une liste d’items, un GET. Nous allons donc décrire un fichier openapi.yaml décrivant cela.
openapi: 3.0.0
info:
description: service backend
version: 1.0.0
title: my-api
paths:
/items:
get:
summary: Get all items
description: Get all items
operationId: getItems
responses:
"200":
description: success
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/item'
servers:
- url: /api/v1
components:
schemas:
item:
type: object
properties:
id:
type: number
name:
type: string
date:
type: string
En gros : on définit une route /items qui renverra un tableau d’item et la structure item. Jusque là c’est du formalisme standard que vous retrouverez un peu partout.
Le serveur
Ensuite il faut construire notre serveur (je n’utiliserai pas le générateur), pour cela nous aurons principalement 2 fichiers de base et un fichier contrôleur. Le schéma étant assez simple, on reçoit une requête, le routeur fait un match et associe la méthode du contrôleur.
On commence par écrire un fichier makeApp.js (dans /src), qui correspond à la définition de notre serveur, notre application. Dedans on y trouve beaucoup de choses, on y reviendra plus en détail après, mais en gros on décrit ce que nous avons dit plus haut, à savoir : définir un serveur express auquel on va connecter le routeur, lui-même basé sur le fichier openapi.yaml décrit plus haut. Le connecteur du routeur se lie aux contrôleurs, nous y reviendrons.
const express = require('express')
const SwaggerParser = require('swagger-parser')
const swaggerRoutes = require('swagger-routes-express')
const ctrls = require('./controllers')
const cors = require("cors")
const makeApp = async () => {
const parser = new SwaggerParser()
const apiDescription = await parser.validate('./api/openapi.yaml')
const connect = swaggerRoutes.connector(ctrls, apiDescription)
const app = express()
...
// Connect the routes
connect(app)
// Add any error handlers last
return app
}
module.exports = makeApp
Ensuite on a le fichier point de départ : index.js, que l’on placera dans un répertoire /src, du coup n’oubliez pas de modifier package.json avec la propriété main :
"main": "./src/index",
Ainsi que la commande start, celle ci se lancerait avec un npm run start mais vous pourriez avoir une surprise, via un Git Bash sur Windows, d’avoir une erreur sur le ./
"scripts": {
"start": "./src/index.js",
Dans ce fichier index.js on aura un appel au précédent fichier de config.
const makeApp = require('./makeApp')
const port = 3000;
makeApp()
.then(app => app.listen(port))
.then(() => {
console.log(`App running on port ${port}...`)
})
.catch(err => {
console.error('caught error', err)
})
Le contrôleur
Nous avons vu que le serveur se lie aux contrôleurs, il est maintenant temps de nous y intéresser. Nous allons créer un répertoire controllers dans /src, et un fichier item.js permettant de regrouper par domaine les actions concernant les items. À côté on créer un fichier index.js permettant de lister le contenu du répertoire au niveau de l’appelant, une façon de faire également utilisée en typescript/Angular.
Le fichier item.js
exports.getItems = async (req, res, next) => {
res.json([]);
};
Le fichier index.js
const { getItems } = require('./item')
module.exports = {
getItems
}
On peut voir la fonction getItems dont le nom match l’attribut operationId du fichier openapi.yaml. Évidemment c’est voulu 🙂 Et c’est important de garder ça à l’œil quand vous préparez votre YAML. Actuellement la méthode renvoie un tableau vide.
Compléter le serveur
Avant de vouloir tester il nous manque un morceau, en fait plusieurs petits détails. Pour faire des appels à notre API, depuis notre poste, on aura un soucis de CORS, mais aussi, potentiellement de cache (en-tête etag) et d’url encoding. À cela on veut préciser que l’on traitera du JSON dans les échanges.
// Options
app.set("etag", false); //turn off
app.use(
express.urlencoded({
extended: true,
})
);
app.use(express.json());
app.use(cors({
origin: '*'
}))
Tester
Pour tester on peut lancer le serveur avec : node src/index.js
On peut ouvrir un Bash et lancer un curl de test, tel que :
$ curl -s localhost:3000/api/v1/items []
Du coup bonne nouvelle on a quelque chose qui fonctionne et répond correctement, à savoir une réponse d’un tableau vide ([]). Pour le fun on peut structurer une donnée et la renvoyer, en respectant le modèle proposé dans le YAML.
exports.getItems = async (req, res, next) => {
res.json([
{
id: 1,
name: "Item 1",
date: "2022-07-13"
},
{
id: 2,
name: "Item 2",
date: "2022-07-01"
}
]);
};
$ curl -s localhost:3000/api/v1/items
[{"id":1,"name":"Item 1","date":"2022-07-13"},{"id":2,"name":"Item 2","date":"2022-07-01"}]
Ajouter la documentation Swagger
D’abord il va nous falloir une lib en plus :
npm i swagger-ui-express --save
Ensuite on va ajouter les lignes suivantes dans notre makeApp.js, l’une dans les déclarations, l’autre après les options afin de déclarer une route de documentation et lancer Swagger.
const express = require('express')
const swaggerUi = require("swagger-ui-express");
...
// This is the endpoint that will display the swagger docs
app.use("/api-docs", swaggerUi.serve, swaggerUi.setup(apiDescription));
Couper/relancer le serveur et rendez-vous sur l’url localhost:3000/api-docs.
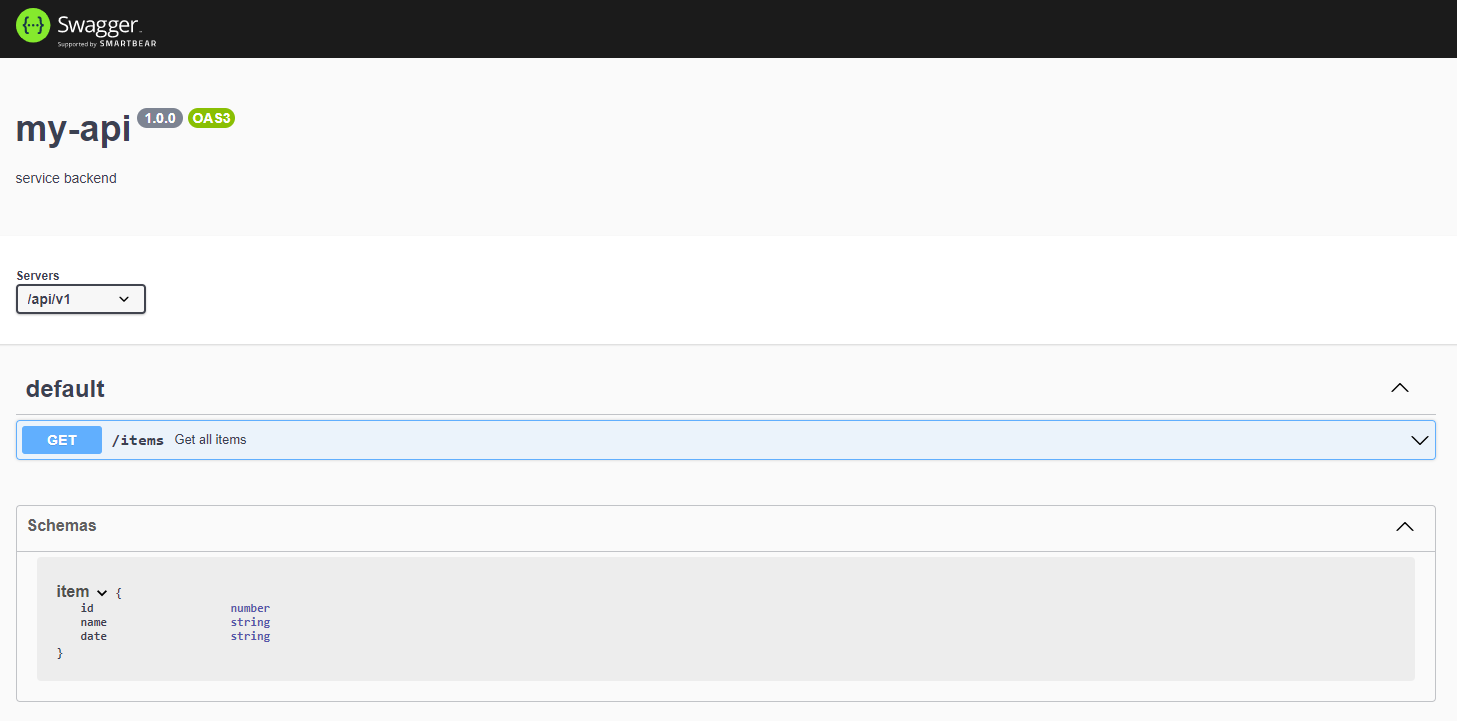
Et ensuite ?
À partir de là libre à vous de créer des services, connecter une base de données, gérer du fichier, etc.
Liste des ressources utilisées
- https://javascript.plainenglish.io/integrate-open-api-swagger-with-node-and-express-b5b77bdc081b
- https://www.freecodecamp.org/news/how-to-build-explicit-apis-with-openapi/
- https://codeburst.io/dont-use-nodemon-there-are-better-ways-fc016b50b45e
- https://itnext.io/wiring-up-an-api-server-with-express-and-swagger-9bffe0a0d6bd
- https://www.thecodebuzz.com/swagger-openapi-documentation-node-js-and-express-api/