Ou Ziggy route dans une cellule Datatable PrimeVue en mode composant de cellule.
Je ne vais pas répéter ici ce qui a été vu précédemment, ce que l’on cherche à faire est un composant utile et générique pour pouvoir rediriger l’utilisateur vers une route nommée avec les paramètres adéquats (variables donc) avec un libellé pouvant être basé sur les données de la lignes (rowData).
La route
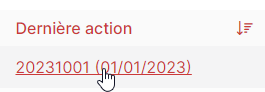
Ziggy va alimenter notre objet route. Ce dernier contiendra la définition de notre router Laravel (pour rappel quand même). On a une route nommée : maroute-edit = /maroute/{id} .
Le composant de lien de cellule
On a besoin de lui passer l’url et le texte à afficher, mais on aimerait profiter du rowData pour construire ce texte et cette url (du fait des paramètres à passer), il nous faut donc un moyen d’intervention du côté de l’appelant.
Pour le texte on peut imaginer que le paramètre ne soit pas le libellé directement mais une fonction callback recevant rowData en params, nous permettant de retourner le string que l’on aura produit potentiellement avec.
Pour l’url c’est plus compliqué, on sait juste que l’on veut travailler avec des routes nommées, donc une propriété qui recevra le nom de la route, mais quid des paramètres ? Dans mon cas j’ai eu un besoin de l’attribut de route ‘id’, mais dans mon rowData c’est l’attribut xyz_id qui matchait et non l’id de ma row, du coup il nous faudrait un mapper qui serait un tableau de clefs avec la valeur à prendre dans le rowData.
En gros l’astuce sera dans props où l’on passera le nom de la route, le mapping de paramètres et la fonction callback pour rédiger le contenu. Ainsi on aura dans mon cas ce rendu avec lien fonctionnel.
Si comme moi vous avez décider de mélanger des trucs et que la documentation vous manque dans ce cas particulier : bienvenue !
Ici la problématique est que le système de menu de Prime utilise un router-link, mais que nous, avec Inertia et Ziggy, on doit passer par Link. Du coup comment dire à PrimeVue de changer ?
C’est sur un forum perdu quelque part que j’ai trouvé la solution, ou du moins le bon point de départ. Il s’agit de définir un composant router-link personalisé qui utilise Link. En modifiant mon fichier app.js de mon projet Goo (voir l’article de mise en place) cela donne :
À ce stade nous n’avons pas encore utilisé route de Ziggy. D’ailleur si vous encapsulé le to dans un route(to), cela ne fonctionnera pas (le Menubar refuse même de s’afficher sans erreur :/). Du coup on déplace la transformation dans la définition du menu.
<script setup lang="ts">
import { ref, onMounted } from 'vue'
import Menubar from 'primevue/menubar'
const menuItems = ref([
{
label: 'Factures',
icon: 'pi pi-fw pi-file',
to: route('invoices')
}
])
</script>
Et du coup nous voilà avec un menu PrimeVue qui fonctionne selon notre besoin Inertia et route Laravel.
Suite à un soucis de machine virtuelle, mon Vagrant m’a planté mon stack et Virtual Box ne s’en sort plus, je suis tombé en difficulté avec mon logiciel comptable fait maison : Goo (v2!). Une occasion de refaire un truc qui n’a pas bougé depuis ~15 ans :/, et de se mettre à jour sur différentes technos ou d’en découvrir de nouvelles.
Cet article a donc pour but de servir de tuto pour monter une nouvelle solution, là où de bons articles existent et m’ont servi (voir les sources au fur et à mesure), mais où ils n’ont pas forcément fait les mêmes choix ou le même montage final.
Laravel et Sail
On démarre avec Laravel, version 9 en ce moment (la 10 arrivera début d’année), et on va utiliser Sail pour l’installer. Sail nous apporte le confort conteneurisé de notre environnement de dev prêt à l’emploi avec les composants dont on peut avoir besoin (ex mySQL). Dans le contexte de Goo, on a 3 tables (clients, invoices, items), que j’ai modélisé avec Gleek, donc je pense qu’un SQLite sera largement suffisant.
Dans un WSL 2 debian, avec un Docker desktop démarré, et dans un répertoire de votre choix, je tape donc :
Le paramètre with permet d’indiquer les services dont on aura besoin, pour qu’il les prépare tout seul dans des containers. C’est bien pratique même si on en a pas besoin, du coup à vide j’évite d’avoir ceux par défaut, sauf que, malgré tout, il met mysql par défaut. On le retirera avant le premier sail up dans le docker-compose.
Ça prend du temps et c’est normal, même si vous avez déjà récupéré les images etc.
Vous aurez peut-être une erreur du style :
Mais ça passe quand même ainsi, je pense que c’est dû au with vide, car sans je n’ai pas vu le même message.
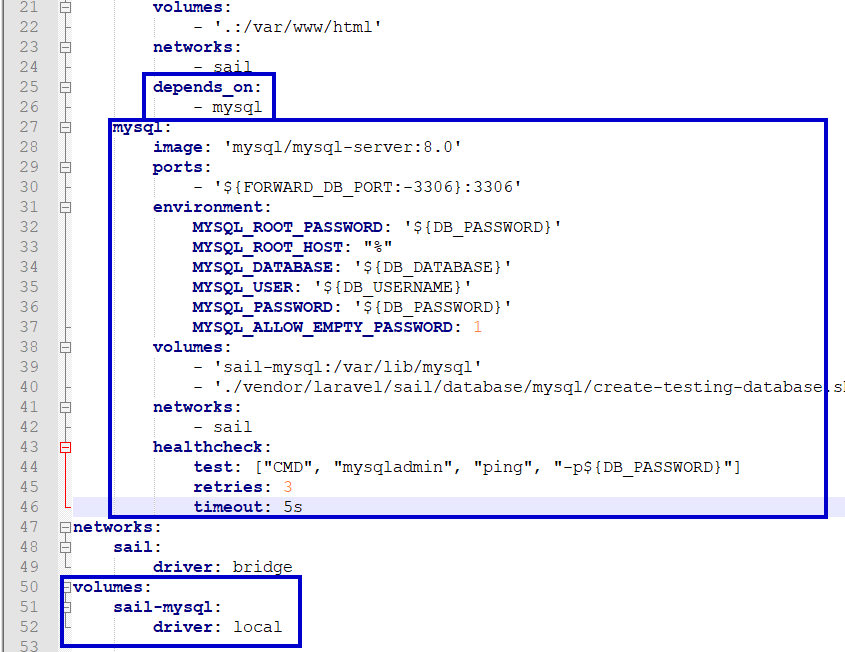
Comme dit juste avant, on va nettoyer notre docker-compose qui se trouve dans la racine de notre nouveau répertoire (ici goo3) et on va y retirer le bloc mysql, la ligne depends_on du bloc laravel.test et évidemment le volume de mysql en fin de fichier.
Quand on est prêt on va dans notre répertoire et on lance Sail :
cd goo3 && ./vendor/bin/sail up
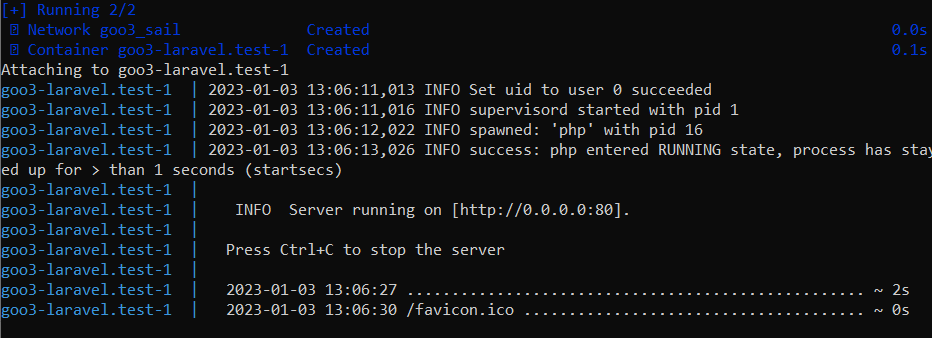
Notre console nous montrera qu’il lance un container et dans docker desktop on le verra également.
Il ne nous reste plus qu’à lancer un navigateur et aller sur l’adresse indiquée ou localhost pour voir notre Laravel installé par défaut qui se lance proprement.
Comme vous pouvez le lire en bas-droite de l’image (si vous avez de bons yeux), on est bien en Laravel 9 sur un PHP 8.
Inertia, Vue, Ziggy et Tailwind
Il ne sera pas question ici de Breeze (paquet d’authentification bien foutu), je n’en ai pas besoin, du coup on ne profitera pas des Starter Kits proposés. Ce que l’on veut c’est Inertia, c’est à dire, un moyen d’avoir un framework front-end (React, Vue) en relation avec notre back-end PHP, non pas comme un back-end PHP qui serait un service REST (ex: Lumen) et un front-end qui le consomme, mais bien un back-end avec le rendu des pages côté back (SSR) et le dynamisme d’un Vue côté client une fois la page chargée. Mais on navigue bien d’une page à l’autre en passant par un appel back. Je trouve que cet entre-deux est intéressant pour les petites applications qui veulent se doter d’un front plus moderne sans devoir forcément sortir l’artillerie lourde. Je vous laisse lire la doc d’Inertia pour comprendre toute la mécanique, c’est bien expliqué.
Comme vous pourrez le voir dans votre fichier package.json nous avons déjà Vite et PostCSS. Vite remplace Mix et nous demande de nous adapter côté config. PostCSS sera utile pour l’installation de TailWindCSS.
Installation
Lançons nous ! On va exécuter une série de commandes pour installer Vue et Inertia ainsi que les dépendances nécessaires pour les lier. Pour ce faire je lance un Git Bash dans le répertoire du projet et j’ai Node 16 installé, il faut que Sail tourne. Et pour les commandes Sail je passe par la WSL (et/ou on fait tout en WSL si vous avez un Node 16 installé dedans).
Reprenons ce tas de lignes, on installe Vue côté front et ensuite Inertia côté back, puis côté front avec l’option Progress qui permettra de montrer les chargements de contenu XHR (AJAX olè). On ajoute Ziggy pour avoir le helper des routes côté front sur base de ce que le back a comme définitions (cf routes/web.php).
Pour la partie middleware, artisan va nous générer un fichier que l’on va pouvoir inclure dans notre config app/Http/Kernel.php :
On peut noter l’absence de title dans le head mais la présence du @inertiaHead qui nous permettra de jouer là dessus en fonction de la page affichée. @routes c’est Ziggy.
On va créer un répertoire dans resources/js : Pages et on va y ajouter une page : invoices.vue :
On va également créer une route pour cette page dans routes/web.php :
<?php
use Illuminate\Support\Facades\Route;
use Inertia\Inertia;
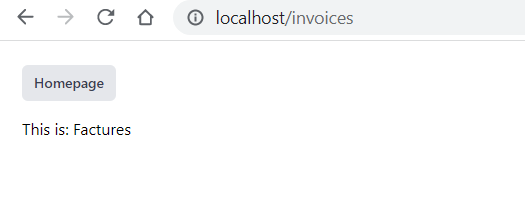
Route::get('/invoices', function () {
return Inertia::render('invoices', ['title' => 'Factures']);
})->name('invoices');
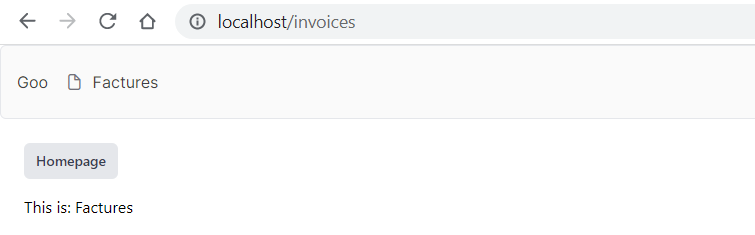
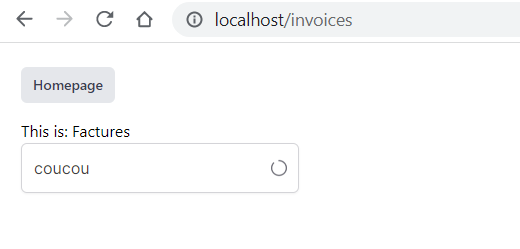
Donc on a Sail qui tourne, le run dev également, on peut se rendre sur http://localhost/invoices et voir le résultat :
Évidemment dans notre test on a hardcodé le titre et la réponse, on a pas découpé les composants, etc. Pas encore !
Layout
Plongeons dans cette question, et là un article, ainsi que la doc officielle vont nous aider. En gros on va créer un autre répertoire Layouts qui contiendra un fichier vue que l’on va appeler basic. Celui-ci contiendra quasiment tout ce que nous avions précédemment sauf Head et le contenu, ici un simple H1, qui sera remplacé par <slot/>.
À noter que les articles manquent de précision pour les novices en Vue, donc ils oublient de nous dire que la partie script est importante et manque dans leur exemple. Ce qui nous permet aussi de lui donner un nom explicite à l’usage. Notre page devient donc :
Relancez votre page et vous aurez le même résultat que précédemment, mais en mieux structuré. Le Head reste dans la page, on appelle le layout et on met notre contenu dedans, fin ! Simple !
Upgrade du Layout : Head title
Répéter le nom du site » – Goo 3″ dans toutes les pages n’est pas une bonne pratique du coup on peut imaginer passer le title à notre Layout qui centraliserait ce bloc de code.
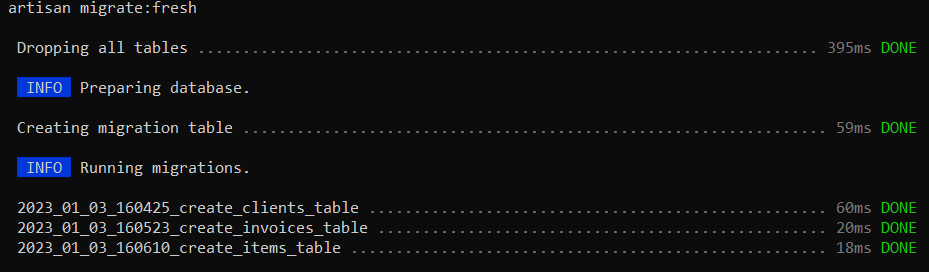
On est un peu passé à côté, mais comme dit plus haut, pour une petite base de données de 3 tables nous n’avons pas besoin d’un gros système, pourquoi donc ne pas utiliser SQLite. La documentation de Laravel nous donne la solution simple. On va créer un fichier dans le répertoire database et déclarer son type dans notre config .env.
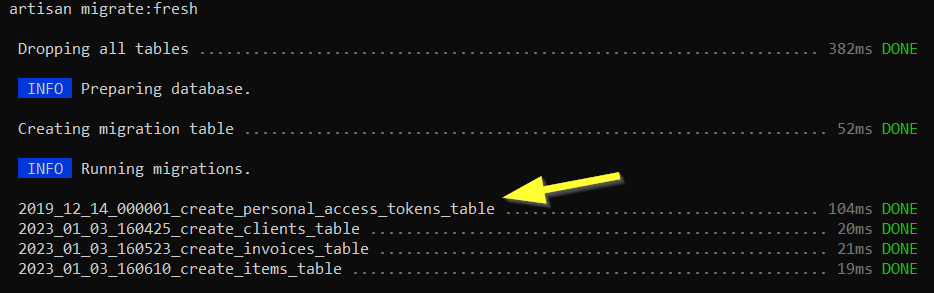
Pensez à virer les migrations qui ne vous intéressent pas avant d’exécuter la commande de migration d’artisan. Dans notre cas nous n’avons besoin que de nos 3 tables, du coup j’ai traduit mon schéma Gleek en migration Laravel.
Sanctum
Quand vous ferez votre migration, malgré le nettoyage, vous verrez apparaitre une migration en trop : c’est sanctum. Nous on ne l’utilisera pas, donc la solution, donnée dans la doc est d’ajouter une commande dans le register de l’appServiceProvider.
use Laravel\Sanctum\Sanctum;
class AppServiceProvider extends ServiceProvider
{
public function register()
{
Sanctum::ignoreMigrations();
}
On sort des sentiers battu bien connu de MySQL avec un bon PHPMyAdmin en utilisant SQLite, du coup j’ai opté pour l’extension Chrome SQLite Manager. Et parmi les 3 extensions disponibles au moment décrire cet article, c’est la meilleure que j’ai testé.
Une fois le fichier chargé on peut voir la liste des tables et de quoi faire des requêtes.
PrimeVue vs Tailwind
D’abord se poser la question, est-ce qu’ils peuvent cohabiter et apporter leurs pierres à l’édifice ? La réponse en un article : oui ! L’idée étant que PrimeVue peut jouer le jeu en proposant ses composants sans utiliser les classes de Tailwind, mais en proposant un thème adapté, ce qui nous laisse champs libre pour un double usage. Il ne reste plus qu’à tenter son installation dans notre solution déjà bien aménagée.
Mais après quelques chipotages sur les priorités et les conflits générés voici la solution. On inverse et on met la base de Tailwind avant sinon celle-ci elle va écraser des styles de PrimeVue et on adapte l’import pour éviter le soucis de compilation.
Si vous faites le test avec un Button de PrimeVue, il était blanc de base et bleu au survol du fait d’une règle de background transparent. Maintenant c’est corrigé et le bouton est bien visible dès le début grâce à l’ordre des règles.
Tester c’est douter
Pour voir si c’est en ordre, j’ai simplement pris un composant simple ‘inputText’ dans ma page invoices.
Pas de mystère là dedans, un fichier assez classique avec en plus le plugin et l’inclusion des ressources à traiter. Il nous reste plus qu’à utiliser le mode typescript dans notre fichier invoices.vue par exemple.
On peut également changer de mode dans Vue et passer du mode options au mode composition. Essentiellement cela change la manière de concevoir vos composants. Pour ce faire, nous n’avons qu’à modifier notre fichier invoices.vue.
Ici j’ai remis l’exemple de l’inputText pour illustrer le principe et montrer que ça fonctionne. Notez l’attribut setup, le code en moins et la manière de déclarer une variable avec ref() et la méthode onMounted.
Conclusion, et ensuite ?
Ce fameux ensuite, car oui on peut toujours aller plus loin, certes, mais pour un tuto c’est déjà pas mal 🙂 On a quand même accompli quelques sujets. On a donc un back Laravel installé avec Sail, une dynamique de pages en Vue, Inertia et Ziggy, du Layout et un design Tailwindcss – PrimeVue. Si ça c’est pas joli ! Et en plus on a une base de données et du typescript, quelle affaire :p !
La suite c’est le développement de Goo 3 tel qu’énoncé en début d’article, mais ça, ça sera peut-être un autre article s’il y a de quoi en dire, car au final les points saillants ont déjà été abordés. Affaire à suivre !
[Bonus] Un petit favicon ?
J’ai découvert un chouette site pour générer facilement un favicon multi support. Pratique pour les projets d’entreprise par exemple. RedKetchup ont quelques outils sympa, je vous laisse les découvrir.
J’ai tout donné aujourd’hui et l’API du Schema Definer est finie ! enfin pour la version prévue sur le plan, on est d’accord. Du coup le titre…
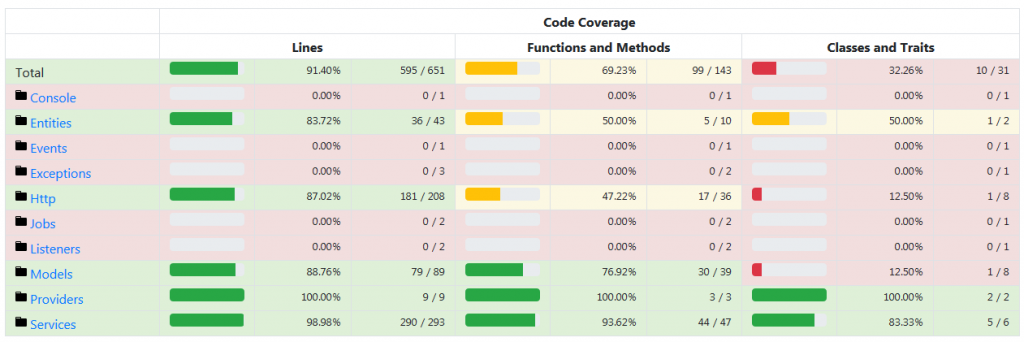
J’ai ajouté le Code Coverage (couverture du code par les tests, ça montre ce qu’on a « testé » ou non) et on a +91% !
Les lignes rouges c’est où il n’y a rien, donc le pourcentage n’est pas exact, mais c’est pas grave, on est bon et ça fait plaisir, il n’a pas été aisé d’en arriver là (voir les 3 dernière lignes, c’est là que ça se passe en fait).
90 tests, sans compter les 10 de la base de données, comptant 187 comparaisons (assertions). Il y a de la redondance et des comparaisons de trop, c’est certains, mais quand on sait que rien que pour tester les Attributs et ses valeurs listées j’ai ~500 lignes de code de test…
J’ai aussi passé pas mal de temps sur la définition de l’API avec son fichier RAML dont je parlais dans un article précédent. Du coup je pense que la documentation est à jour et valable. Pour ceux que ça intéresse, ça prend pas mal temps, on négligera mais n’y penser même pas, ça vaut le coup. Pensez également à votre PHPDoc.
Le temps d’écrire cet article, de faire une pause et chipoter, on est passé à 96 tests et 193 comparaisons avec un résultat de ~94% de couverture ! Des commentaires en plus, du refactoring pour réaménager des méthodes qui pouvaient être mieux écrites, cibler les interdépendances des tests (@depends), etc.
Ça y est, notre API est prête, l’instant de vérité approche. Nous allons pouvoir commencer le « front » (site visible/pour les humains autorisés) et mettre à l’épreuve les appels, dans le sens « est-ce qu’on a pensé à tout ? », « est-ce suffisant ? » et/ou « est-ce utile/nécessaire ? ».
Petit point sur l’avancement des travaux concernant le Schema Definer. Non je n’ai pas abandonné et oui ça progresse ! Non mais, je vous vois là dans le fond.
Actuellement je n’ai bossé que sur l’API et ses tests, et point encore sur le front Angular. Plus précisément sur la partie Auth et Logout, ce qui implique le middleware (~ détection de votre connexion courante), le tout en stateless (~ pas de session).
Enfin, quand je dis « que », ce n’est pas rien, c’est important et cela m’a pris pas mal de temps. D’une part, pour « bien » faire, et d’une autre car la doc de Lumen est une catastrophe au final, ainsi que sa communauté, quand on sort des rails… ontologie vous vous rappelez ?
Ce n’est surement pas encore parfait mais ça fonctionne suivant les règles établies par le cahier des charges. De plus c’est testé, avec PHPUnit, et ça non plus ça n’a pas été aisé, notamment sur les appels JSON pour tester de bout en bout, il a fallu pas mal creuser entre les docs.
Du coup petit topo, on a déjà 3 classes de tests, représentant un total de 24 tests pour 75 contrôles réparti en 2 « suites de tests ». Ça prends forme et ça m’a bien aidé, même « quand ça va pas », vos erreurs sont attrapées par le systèmes et ne vous aide pas toujours, un peu comme Eloquent et sa foutue classe Connection pour ceux qui connaissent…
On va donc pouvoir attaquer les différents services à fournir et travailler sur le système de droits. C’est parti !
Edit
Après avoir fièrement écris cet article, j’ai voulu continuer comme dit, et d’un pas décidé je regarde ma spec de l’API pour attaquer dans l’ordre. Et ô stupeur, concernant le sujet Auth, j’ai oublié une idée, mais non sans conséquences : la déconnexion de toutes les connexions de l’utilisateur.
Pour vous ce n’est peut-être rien, mais aujourd’hui vous vous connecté potentiellement au même site via votre GSM, votre PC ou votre tablette en même temps et ceci ça se gère !
Actuellement la connexion était unique, si vous vous connectez sur votre GSM, par sécurité on déconnecte la « sessions » de votre PC, etc. Sauf que non, vous voulez peut-être démultiplier les onglets et moyen de connexions pour une raison X ou Y et c’est à nous de vous le permettre, en le gérant.
Du coup, notre connexion unique, elle doit devenir multiple, et comment on fait en ontologie/dans notre schéma ? Et ben on doit le modifier et donc réécrire le code, pas toute la logique mais une bonne partie, et donc les tests spécifique à la mécanique.
C’était fini ? Et ben plus maintenant, on recommence…
Pour les curieux, la connexion doit devenir une Entité, car elle comporte plus d’un attribut (token, ip, …), il faut donc défaire ce qui concerne le token etc par rapport à l’entité de l’utilisateur, créer une nouvelle entité, lier les attributs, créer le lien vers l’user et refaire les requêtes. C’est là le côté moins performant qui s’affiche, mais c’est là aussi que l’on voit la flexibilité de l’usage sans changer la base de données elle-même.
Suite de l’article précédent sur le même sujet, mais cette fois de manière plus technique. Nous voilà déjà 7 mois plus tard… Rien n’a été fait si ce n’est ce mois de Mai, du coup décortiquons.
Comme dit précédemment, c’est un gros projet, ambitieux et novateurs à différentes échelles, et donc accompagnés de complexités et difficultés pour le démarrer/réaliser. Oui OK je me cherche quelques excuses mais elles sont véritables.
« Mais tout vient à point à qui sait attendre » un sage aurait-il dit; et c’est effectivement le cas : l’illumination du premier jalon. Je vais donc vous parler de ce qui porte le nom, actuellement, de Schema Definer ou le définisseur de schéma.
« Mais qu’est-ce donc ? » demande la foule tel un 42 en réponse d’une longue attente. Tout simplement notre première étape, car vous n’imaginiez quand même pas que le site pouvait se gérer sans structure ?
Aussi permissif le site, en objectif, sera; autant il lui faut une mécanique de définitions pour vous proposer celle-ci. Quelle belle phrase.
Récapitulons après ce blabla. Jusque là nous avons défini un schéma de base de données, donc un moyen de stocker de l’informations organisées selon une définition. Cette dernière décrit un ensemble de tables représentant notre infinie possibilité à décrire tout système folklorique.
Ça c’était il y a +2 ans, selon les idées sur les ontologies. Ensuite j’ai cherché le stack ultime du web de demain… Ok sans succès, on va partir sur un Angular/Lumen pour débuter. Mais je ne désespère pas de trouver le design du web de demain quand on attaquera le front (partie visible et utilisable).
Déjà le fait d’avoir simplifié et décidé du stack, ça soulage, beaucoup même. Je vous recommande Homestead via Vagrant pour démarrer avec simplicité.
Revenons à nos moutons après cette digression. On a de quoi stocker de l’information brute qui n’aura du sens que si on lui en donne, c’est le rôle du Schema Definer. Le schéma sémantique sur le schéma structurelle (stockage).
Si je stock 36, rien ne me dit que c’est mon age, sauf si une définition l’indique au système.
Là je vous ai perdu, entre logique effrayante et explications à rallonge.
Comme dit nous avons un système de stockage différent de ce que l’on a habituellement (relationnel, non relationnel structuré, …) où la conception contient le sens des données. Mais nous, non. Notre mécanique retiendra des nombres et chaînes de textes reliées entre elles, de manière relationnelle.
OK, c’est quoi ce schéma ? Tout simplement la définition de ce que l’on veut encoder sur Folkopedia : une personne, un groupe, un document, …
Pour faire simple, en expliquant sommairement la mécanique triplet RDF, vous aurez un objet/entité (virtuel), qui a des propriétés avec des valeurs.
De manière appliquée : je suis l’instance d’une Personne, ayant pour surnom : Killan. Le schéma précise qu’il existe une entité Personne, avec pour propriété possible un surnom qui sera de valeur texte.
La valeur pourrait être la référence d’une autre entité. Genre une entité livre peut avoir une propriété auteur qui a comme valeur la référence d’une entité personne. Etc.
Avec une table de 3 colonnes vous avez votre système, simple mais horriblement pas performant. Et on ne va pas entrer dans ces histoires-là ici. Le schéma Folkopedia est différent tout en suivant le principe et un futur système de cache fera le delta de performances. On reviendra dessus bien plus tard.
Pour revenir sur le Schema Definer, vous pouvez prendre exemple sur le site de schema.org qui est le premier objectif. Vous pouvez prendre l’entité Book (livre) comme exemple.
Pour résumer, on peut dire que le Schema Definer est une administration de la structure de données du site Folkopedia.
C’est pour ça que j’ai parlé d’Angular, il nous faut une interface pour manipuler ce schéma. Peut-être qu’un jour on exposera ce site, comme explication de la démarche scientifique, on verra, rien n’est figé actuellement. La démarche m’importe beaucoup.
Bref, là on a un Lumen installé sur un Vagrant/Homestead, tout frais, et cet articles un point de départ publique. C’est parti !
Une collègue m’a lancé un petit défis suite au travail de sa fille (future développeuse) : le jeu de Nim, dans sa version une grille, un puit et 4 pions. La partie défi résidait dans la question qui vise à calculer la valeur d’une cellule de la grille, le nimber, en donnant juste la colonne et la ligne en entrée.
Le but étant d’obtenir une valeur sur base de coordonnées, la fonction passera par l’usage de $x et $y.
Ce jeu de Nim part de la dernière case inférieure droite (le puit) avec une valeur 0, on devra remonter d’où l’usage de la valeur max – index.
Comme la valeur de case ne peut avoir que comme valeurs possibles le nombre de cases où l’on peut se déplacer, dans le cas de l’énoncé, chaque pion peut se déplacer potentiellement dans maximum 4 cases. Nous aurons les valeurs [0, 3], le modulo (%) 4 nous y aidera (jouez avec le modulo).
Dernière astuce, le modèle (pattern) trouvé à la main, réside en un tableau de 3×3 se répétant indéfiniment. Ainsi, le modulo (%) 3 permettra cette répétition.
La partie complexe de ce calcul se trouve dans le rapport en x et y. Si on additionne x et y et qu’on applique le modulo 4 une partie des cellules seulement sont bonnes (une sur 2). Si on fait une soustraction, c’est l’inverse. Faire un + et un – en même temps c’est là que le xor est survenu (jouez donc avec le XOR).
Ainsi après une belle prise de tête empirique la solution est là 🙂 !
Dans un projet d’assemblage de PDF (j’en parlerai surement dans un autre article) je devais pouvoir envoyer différentes pages et une structure pour établir une table des matières. Je pensais mettre à jour la structure à chaque envoie mais le résultat obtenu n’était pas celui attendu, il me manquait des choses. Je recevais bien toutes les données, le curl fonctionnait bien, mais la structure était incorrecte.
Après analyse de mon code, remise en question etc, il s’avère que c’est au niveau du curl que ça coince. En effet, faite une vingtaine de call curl à la chaîne avec transfert de fichier à taille variable et vous comprendrez que c’est entré en conflit. Droit d’écriture sur le fichier ? Verrou de fichier ? Rien n’y fait.
Un call curl (méthode PHP et consort) n’est juste pas bloquant dans la complétion de son action.
Pensez autrement
Oui, au final, vous devrez revoir votre manière de vous y prendre, l’idée a été d’envoyer les fichiers, sans se soucier de la structure, de la maintenir coté client et de l’envoyer par une méthode supplémentaire du service avant d’appeler la génération finale. Le projet reste le même, juste le quand on reçoit l’info.