Le curseur
Dans la continuité, je me suis attelé à m’occuper des interrogations précédentes, car sans un pointage efficace il sera difficile de bien comprendre ce qui se passe, surtout en cas d’erreur. Du coup, aujourd’hui, c’est la révolution du curseur !
Premièrement, il a fallu ajouter une méthode pour savoir si on est sur un Element ou non, quelque soit l’algo, et ainsi le dire à la Scene pour qu’elle s’arrête au plus tôt (économie) et puisse déterminer la position, ou ne rien trouver.
On part du fait que la souris donne sa position, je vous passe le trafic des événements, et on pose le curseur à la coordonnée reçue.
Premier point : le curseur se met au niveau zéro et c’est chiant, car avec l’élévation, l’œil humain se perd et à du mal à coller la grille sans repère. Donc on va s’occuper de ça directement.
Il s’agit d’insérer l’Element curseur sur le dernier Element de type Ground de la coordonnées, donc après si on regarde la liste des Elements de cette coordonée. Il ne faudra pas oublier de le retirer au prochain déplacement significatif de la souris (x ou y différent).
Ensuite, on peut revenir sur la détection du curseur, et là on fait du raycasting (lancé derayon), car la position de la souris sur base de la grille n’est pas suffisant, la souris touche quelque chose et pas forcément le niveau zéro d’une case de la grille. J’ai donc opté, pour commencer quelque part, par le cadre de l’image au complet.
En gros on va prendre le chemin inverse du rendu. Au lieu de commencer au plus haut on part du plus bas, en remontant inversement les Elements dessinés.
Les images finales en fin d’article démontrent clairement ce que j’exprime ici, vous verrez.

On se base sur le point de repère de l’image, on ajuste en fonction du point de pivot (basex, basey), le tout en prenant la bonne frame du sprite et ses caractéristiques et surtout, on oublie pas de ramener tout aux coordonnées 0, 0 de l’écran (client du navigateur). Sinon comment comparer une position de souris avec une image quelque part à l’écran, les 2 avec un système de coordonnées différentes.

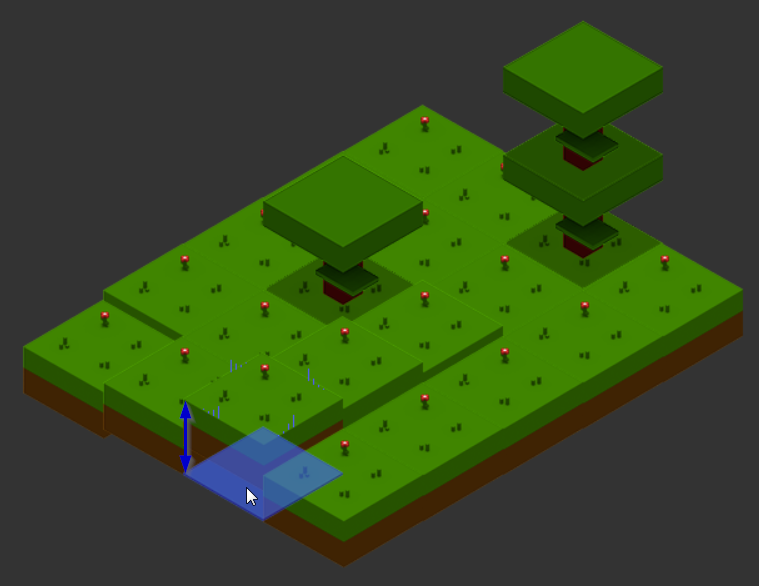
On a donc un premier jet fonctionnel, mais vous remarquerez directement que ce n’est pas idéal, on compare des rectangles théoriques avec des losanges visuels, l’utilisateur ne comprendra pas, et c’est normal.
On peut améliorer ça si on se donne un peu plus de mal, et là j’ai cherché comment détecter un point dans un polygone, mais entre Math complexes et obscures, librairie fermée et autres, les possibilités sont nombreuses et pas toutes idéales (vitesse, facilité, …). J’ai opté pour une ligne dans un triangle et là j’ai découvert qu’en fait c’est 3 fois une comparaison du point avec une droite, de quel côté le point est. En sens horlogique, les valeurs négatives sont à « l’extérieur » de la droite si on considère le triangle comme 3 droites qui ferment le polygone. Du coup on peut augmenter le nombre de droites, tant que le tout reste un polygone convexe. Ce qui nous donne après plusieurs encodages des données de points :

C’est beaucoup mieux n’est-ce pas ? Plus précis surtout. Là il ne faut pas se tromper, on démultiplie les tests, donc il ne faut pas oublier de couper court dès qu’on sait si on touche au moins une fois l’Element.

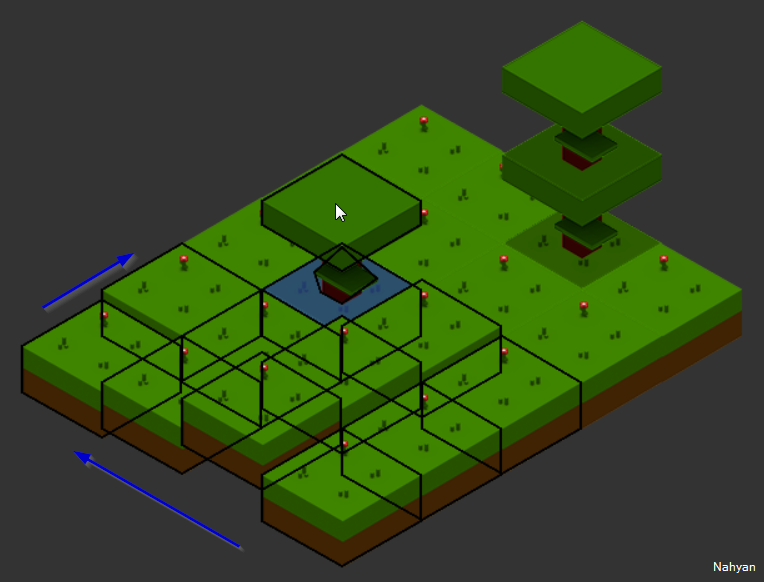
Suite aux expérimentations, tout fonctionne, mais on perd le curseur dans la zone grise quand on a pas de Ground présent sur la grille. Cela vient du fait que le rayon n’a percuté personne donc ne rend rien, du coup il faut revenir à l’ancien système de coordonnée de souris vers coordonnée du monde, tout simplement, comme avant.
Ceci dit, ce monde démarre en 0, 0 et les valeurs négatives sont refusées par une des méthodes, je dois encore regarder à ça, mais pensez-y.
Notez également un problème avec le resize, le curseur se démultiplie bizarrement visuellement, mais rien de clair actuellement sur la raison. Il faudra inspecter l’état de map ou subsetmap, et ce n’est pas du tout une mince affaire…
Le chargement chaîné
Depuis le début, une des problématiques est d’avoir les infos quand elles sont disponibles et nous sommes dépendant de chargement de Sprite. La Scene s’occupe du chargement de ses Elements mais aussi des Sprites via le service Resources. J’ai modifié ça, et je pense améliorer l’idée et la mécanique en mettant le chargement de l’image dans l’Element et en modifiant fortement la manière dont Resources s’en occupe. Désormais, le premier Element qui veut charger un Sprite, va créer un Observable dédié et s’y accorcher. Le second Element qui a besoin du même Sprite ne va pas recréer mais s’accrocher tout simplement à l’Observable déjà créé. Ainsi, quand le Sprite a fini, il prévient tous ceux accrochés. Je rajoute que si le Sprite a déjà fini de se charger quand on le demande, on renvoie un Observable auto clôturé, ce qui donnera l’info directement que c’est bon, c’est chargé.
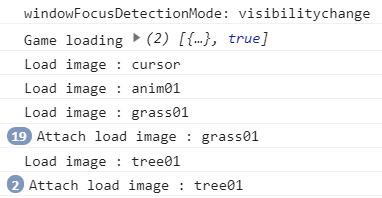
L’avantage direct est l’initialisation de l’Element sur base des infos des Sprites dont il a besoin. Pensez animation et c’est direct le bordel dans la tête. Un Sprite contient les définitions du possible, l’Element contient l’état actuel. Ainsi l’Element, lors de son update(), cherchera les infos de l’animation courante qu’il a décidé de jouer dans le Sprite. Chacun son rôle, mais si Sprite n’est pas chargé quand vous voulez initialiser Element ça ne fonctionnera pas car pas encore disponible.
Initialement, je faisais cet initialisation au premier update de l’Element, car là on savait que tout était chargé. Il ne peut y avoir d’update d’une Scene que si celle-ci a obtenu le feu vert du chargement des ressources.
Maintenant, au lieu d’un « if » perpétuel, valable qu’une seule fois, dans la fonction update, on a une initialisation propre et un update tout aussi propre.
Plusieurs Sprites pour un Element
Un sujet qui traîne depuis une refonte, c’est le fait qu’un Element peut avoir plusieurs références de Sprite, ceci pour un objet composé comme un arbre, un personnage etc.
Mais que faire au niveau de base de Element, toutes les méthodes actuellement prennent le premier de la liste et ne s’occupent pas du reste. Pire il n’y a pas de contrôle ou d’adéquation entre la configuration envoyée à l’Element et sa nature (je suis une fougère…).
Du coup, j’ai complété une idée précédente, encore un POC, mais qui tient quelque chose. J’ai créé un service DTD (document type definition) et créé 2 listes de références pour déterminer le chaînage entre des Elements et une autre pour déterminer de quoi est fait un Element typé. En plus clair, si je suis un Tree (arbre), j’aurais besoin d’une définition pour Trunk (tronc) et une pour Foliage (feuillage), sinon comment l’Element de type Tree pourra savoir qu’il a bien reçu les Sprites dont il a besoin s’ils ne sont pas identifiés ?
Nous avons donc maintenant un Element (générique), qui reçoit son type par la configuration et une suite de références de Sprites, on passe cette liste par une moulinette de contrôle grâce à la DTD de types et nous avons là une liste identifiée de références propres au type de notre Element.
Là de suite ça n’apporte pas grand chose, juste un contrôle de ce qu’on reçoit, ne prendre que ce qui est possible pour notre Element typé. Un Tree ne va pas s’occuper d’une référence de roché par exemple, il l’ignorera. Nous sommes d’accord que ce cas de figure n’a pas lieu d’être, sauf si édité à la main avec erreur.
L’avantage de ceci est que si nous créons un éditeur pour TARS/Nahyan, en cliquant sur un Element, on recevra sa cartographie via son type et donc on pourra créer un formulaire pour choisir les Sprites attendu par le composant. Prenez un arbre tronc et feuillage, sélectionnez le, modifiez le tronc de chêne par un tronc de bouleau et un feuillage d’automne plutôt que d’arbre mort, un choix de texture typée pour un Element ayant une définition venant de la DTD.
S’il n’y a pas de définition, un type par défaut englobe tous les cas où il n’y a qu’une seule image pour l’Element, ce qui facilite les encodages, les réduits et n’oblige pas de faire une sous classe par type si la seule différence est cette notion. On a donc un Element générique capable de beaucoup de chose à lui tout seul.
Dans notre cas d’arbre, l’Element Tree doit dessiner un tronc et un feuillage. si vous vous rappelez un article précédent sur l’empilement, il suffisait de faire X Element et de les mettre dans l’ordre à une coordonnée, l’empilement aurait fait le travail, mais vous n’auriez pas la possibilité de donner un comportement global et programmé à votre arbre. Vous voulez une interaction, et peut-être que le tronc fasse 4 hauteurs de bloc avant de mettre le feuillage, il vous faut donc une extension de la classe Element, en étant générique, elle ne traite pas les particularités, c’est un peu le but.
On créera donc une nouvelle classe Element pour notre arbre, on l’appellera TreeElement et on surchargera uniquement la fonction de dessin et de contact pour le raycasting. En fonction de paramètres spécifiques, prévus dans la définition de la configuration possible des Elements, nous pourrons dire la taille de notre arbre, qui sera le multiplicateur du tronc par exemple (si on considère un tronc comme un bloc de tronc).
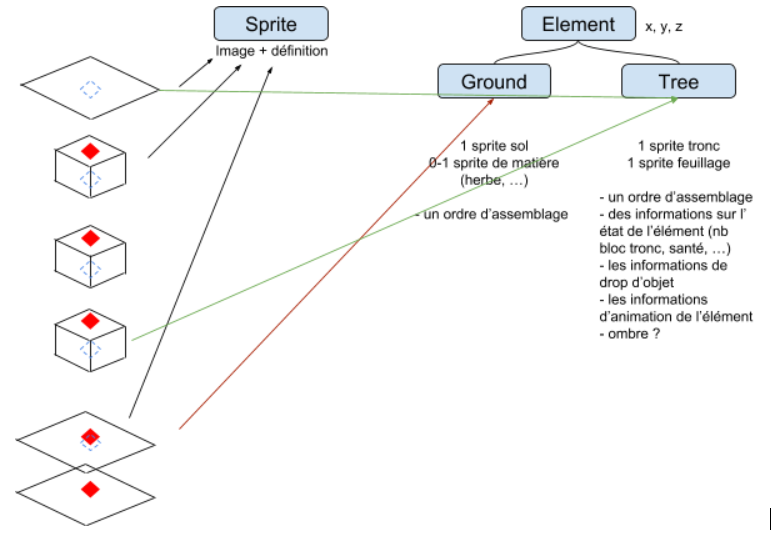
C’est là que la définition par le type de nos références de Sprite a de l’importance, car notre TreeElement pourra explicitement faire une référence aux Sprites dont il a besoin par leur nom prévu. Il sait qu’il peut manipuler un Sprite nommé Trunk, et un autre nommé Foliage. Ainsi il saura quoi faire lors du dessin et lors de la détection, vu que les 2 dépendent de comment le dessin final est monté.
C’est complexe a expliquer, mais une fois que l’on comprend le rôle de chacun, la nécessité de séparer proprement les concepts, la manière dont c’est utilisé etc. alors cela devient simple pour vous. Mais je vous accorde que c’est un exercice de pensée qui n’est pas aisé surtout avec juste des explications et quelques illustrations sommaires.
La suite ?
Toujours le pathfinding et l’objet NESW, qui restent la suite logique de ce qui a été fait jusqu’à présent. Ainsi que les quelques bugs décelés : valeurs négatives refusées sur la grille, considérer le haut d’abord dans la détection de contact et le soucis de curseur lors du resize, entre autres.
Ça avance 🙂




 Avant
Avant









