Tel Stanley Ipkiss, TARS joue maintenant avec un masque lors des rendus d’objets occupant plusieurs cases dans notre contexte isométrique. Mais pourquoi ?

C’est là qu’il faut vous expliquer comment ça fonctionne, ce qui n’est pas une mince affaire. La table occupe 2 cases, mais comme tout Element, il a une coordonnée qui ici nous dit {x: 8, y: 2} (rappel on commence à zéro) et notre Héro, lui, arrive sur la case {x: 9, y: 1}, ce qui de part notre mécanique de rendu Isométrique dessine le Héro avant la table et donc la table écrase le dessin du Héro. Vous suivez jusque là ?

1 problème ?
On a donc un problème, le Héro devrait être dessiné devant la table, ce qui correspond à notre logique visuelle. Même si on inverse le sens de dessin, en colonne au lieu de ligne, on aura le même soucis avec l’autre table.
Après de longues recherches et essais, une seule solution : la manifestation ! découper l’image en 2 pour occuper chacune une case. Car le problème n’est pas que cette erreur de dessin mais aussi le pathfinder qui passe au travers de la case qui n’est pas affectée (en mémoire), elle ne l’est que par vos yeux; et enfin la lumière qui voit la table tantôt d’un bout (loin), tantôt de l’autre bout (proche) et donc l’éclaire différemment.
3 problèmes ?
Le pathfinder se base sur la présence d’un Element sur la grille que l’on fabrique sur base du subsetMap, et la lumière, chacun ayant son algorithme. Le rendu se base directement sur la subsetMap. On serait tenté de dire qu’il faut solutionner les 3 individuellement et c’est ainsi que j’avais commencé.
J’ai donc ajouté une notion d’additionnalCoords (coordonnées additionnelles) dans la définition de l’élément table et ce pour les 4 orientations NESW, décrivant, dans le cas de notre table orientée vers le Nord et dont la base se trouve en bas gauche de l’image, une case additionnelle en x: 0, y: -1.
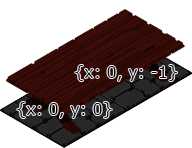
Le choix de la coordonnées {0,0} vient du sens de rendu et du sens de détection du raycasting quand on clic droit sur un Element (coffre, porte). La dernière case dominera les précédentes comme démontré par le problème. Le raycasting parcours l’inverse du rendu pour trouver l’élément le plus devant. Notre {0,0} sera donc cette dernière case a être rendue et correspondra à la coordonnée de l’Element, les additionalCoords représente l’ensemble des autres cases en mode relatif (ex: {x: -1, y: 0} pour la table orientée vers l’Est).
Raycasting ? 4 problèmes donc ?!
Maintenant que vous comprenez la structure, le pourquoi du comment et la mécanique céleste, nous allons tenter de corriger les problèmes un à un.
Le plus facile est le pathfinder, qui se base sur des cases occupées pour dire que l’on ne peut s’y rendre. Actuellement le Héro se déplace sur la seconde case de la table « dessous » car la table se dessine après. Il faut donc arriver à lui dire « hey tiens voilà des coordonnées additionnelles à retirer !« .
Aussitôt dit, aussitôt fait, quand on prépare le pathfinder sur base de la subsetMap, on demande à tous les Elements s’ils ont des coordonnées additionnelles et ensuite on les retire du résultat final.
Fin ! 8D
Ah ah ah Oui mais non ! Ça fonctionne, certes, le Héro ne traverse plus les tables, ce n’est plus un drôle de fantôme. Mais ! La lumière n’est pas bonne, le raycasting reste un problème et évidemment notre problème de rendu reste identique, la table passe devant le Héro.
J’ai tenté une théorie visant à dire au GridBlock de prendre en compte des pointeurs, une forme de référence entre cases, mais en vain. Un GridBlock est un multi-ensemble d’Elements, point.
Je vous épargne toute la frustration et brisage de méninges, il m’aura fallu une bonne semaine pour trouver la seule piste envisageable.
Un système de masque
Dit comme ça, ça semble être la solution ultime, et c’est pas loin, mais incomplet. On garde les additionnalCoords et on s’en sert à l’ajout de l’Element sur la Map lors du chargement pour l’ajouter à chacune des cases, le même élément (la même instance, pas une copie). Notre table est donc physiquement présente en mémoire sur 2 cases.
Cela résout le problème de pathfinder et on peut retirer ce que nous avons fait précédemment. Le raycasting est aidé par cette approche mais il faudra l’aider (cf le rendu), nous verrons ça en fin d’article. Il nous reste la lumière et le rendu.


L’idée du masque est de dessiner une partie de l’image sur chaque case correspondante, évitant de demander au graphiste de préparer un grand nombre d’images individuelles et de devoir se battre avec son éditeur de map, ce qui n’est pas gérable.
Modification du système de rendu
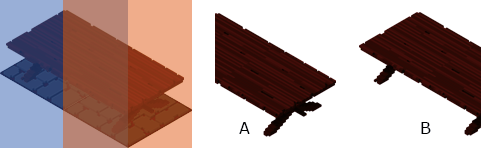
Dans le cas où notre Element a des additionnalCoords il faut appliquer le masque, sinon le rendu classique qui va bien. Pour y arriver, il nous manque quelque chose, comment savoir quelle partie dessiner ? Actuellement nous dessinons selon la coordonnée de l’Element, du coup dans ce cas on dessine une table entière selon ses coordonnées ce qui donne l’effet de fusion illustré ci-avant.
Pour changer ça, il faut dire à notre système de rendu que ce n’est pas la coordonnée de l’Element qu’il faut utiliser, grosso modo. On va commencer par ajouter la notion de coordonnées au gridBlock, qui n’en avait pas besoin jusque là. Et qu’ils passent cette coordonnée à la fonction draw() pour que l’information arrive au système de rendu.
Et après on fait comment ? On se questionne, a-t-on des additionnalCoords ? Si oui, à laquelle correspond le x,y donné par le rendu ? De la on calcul un masque prenant en compte le déplacement dans l’image pour n’afficher que ce qui nous intéresse dans notre cas. Illustrons ça avec la conquête des erreurs de rendu.



Le Héro ne passe plus derrière la table ! Mais ?! Qu’est-ce-que c’est que cette drôle de table coupée ? On a un soucis, ok mais lequel ? On dirait que la « fenêtre » du masque n’est pas au bon endroit, mais pourquoi que dans la table orientée à l’Est (à gauche) ?

Pour déterminer ce qu’il se passe, j’ai essayé de dessiner le premier morceau, et on voit que le même problème apparait.

Tentons de voir à quoi ressemble chaque morceau sans considérer la case originale. Nous n’avons pas le même résultat, en vert on a une fenêtre aux bonnes dimensions et bien positionnée, en rouge non.
Pour tenter de comprendre, j’ai modifié la table Est en inversant son origine (en haut gauche au lieu de bas droite) et en modifiant son rendu. J’ai également ajouté un fond à l’image pour comprendre les dimensions gérées.

En rendu inversé pour la table Est ça fonctionne ! Mais pourquoi ? Qu’est-ce qui change ? Et là une théorie survient, le fait que la base soit au delà d’une distance de case dans l’image quand on calcule le masque, provoque ce décalage. Je vais vous passer les calculs et les correctifs spécifiques au masque, mais en résumé, on doit déplacer la coordonnée source dans l’image selon la théorie isométrique (par demi case en X/Y) mais aussi corriger le résultat par cette même théorie, car il faut rationaliser ce décalage au delà d’une distance d’une case. De plus ce dernier correctif doit être appliqué à l’inverse au positionnement de destination. J’ai tenté un dessin, mais même pour moi il n’a pas été simple de le schématiser pour le coder.

On a donc notre Héro devant la table, des tables bien positionnées (celle de l’Est a été déplacée pour les tests) et on a en même temps solutionné la lumière qui éclaire équitablement les 2 morceaux. Ceci est un effet de bord qui tombe à point et qui se base sur le fait que c’est la même instance du même Element qui est référencé dans les 2 cases et donc quand la lumière s’applique, c’est le plus proche qui est choisi et appliqué, par effet de propagation. Enfin, c’est ma déduction car je ne me suis pas amusé à le démontrer.
Bon ok j’ai regardé un petit peu en écrivant ces lignes, il se pourrait que la table aie une addition de quantité d’éclairage par case, il faudra donc vérifier ça et décider du comportement. Vu les formes découpées, je ne suis pas sûr qu’un éclairage non uni soit une bonne idée.
Et le raycasting ?
On y vient, comme dit plus haut, c’est ici que ça se passe. On est vite tenté de dire qu’on a fini car nos problèmes visuels s’en sont allés, mais que nenni, il nous en reste un beaucoup moins visible : le raycasting. Pour ceux qui n’ont pas suivi, le raycasting (lancé de rayon), permet de déterminer dans notre cas ce sur quoi on clic (quand on clic droit sur le coffre, la porte, ou même un arbre).
Donc ici, pour chaque case, il se croit être à l’origine et m’est avis que ça va pas nous aider. Il va falloir, car ce n’est point encore fait, lui expliquer à lui aussi le système de masque. Par extension, on pourra peut-être globaliser et « simplifier ».
Prochaines étapes
En me relisant, je remarque que je parle souvent de l’éditeur mais pas cette fois; ni du jeu que nous allons démarrer comme projet vivant de l’usage de notre moteur TARS, et oui toujours dans le monde de Nahyan, nous y reviendrons prochainement; Mais plutôt vous parler de système de particules et de miroirs qui me sont venu à l’esprit et tant qu’à faire, une démo technique avec une petite explosion dont chaque particule est luminescente et se reflète dans des miroirs…