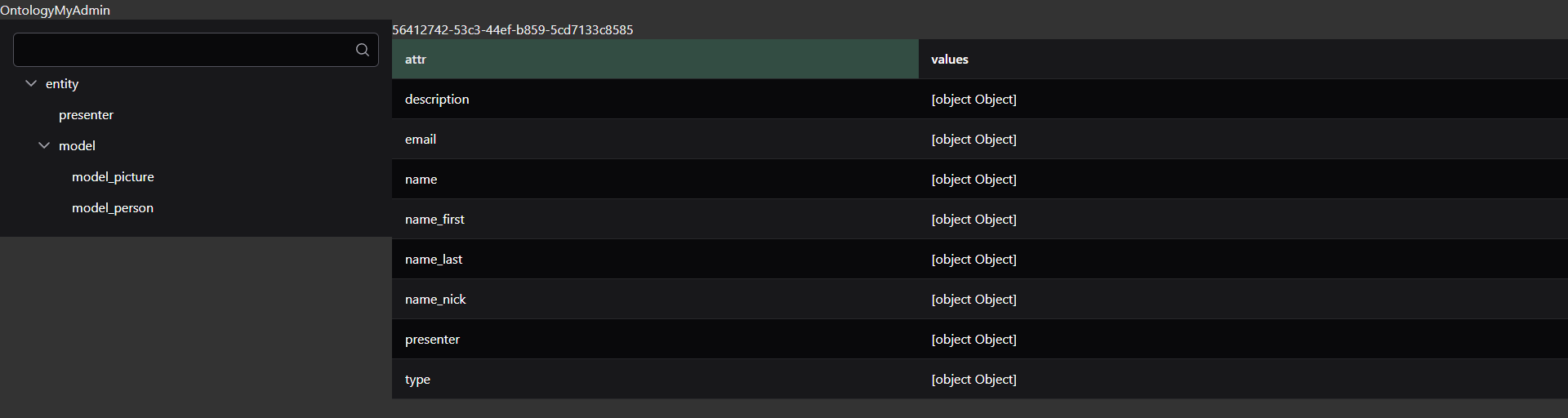
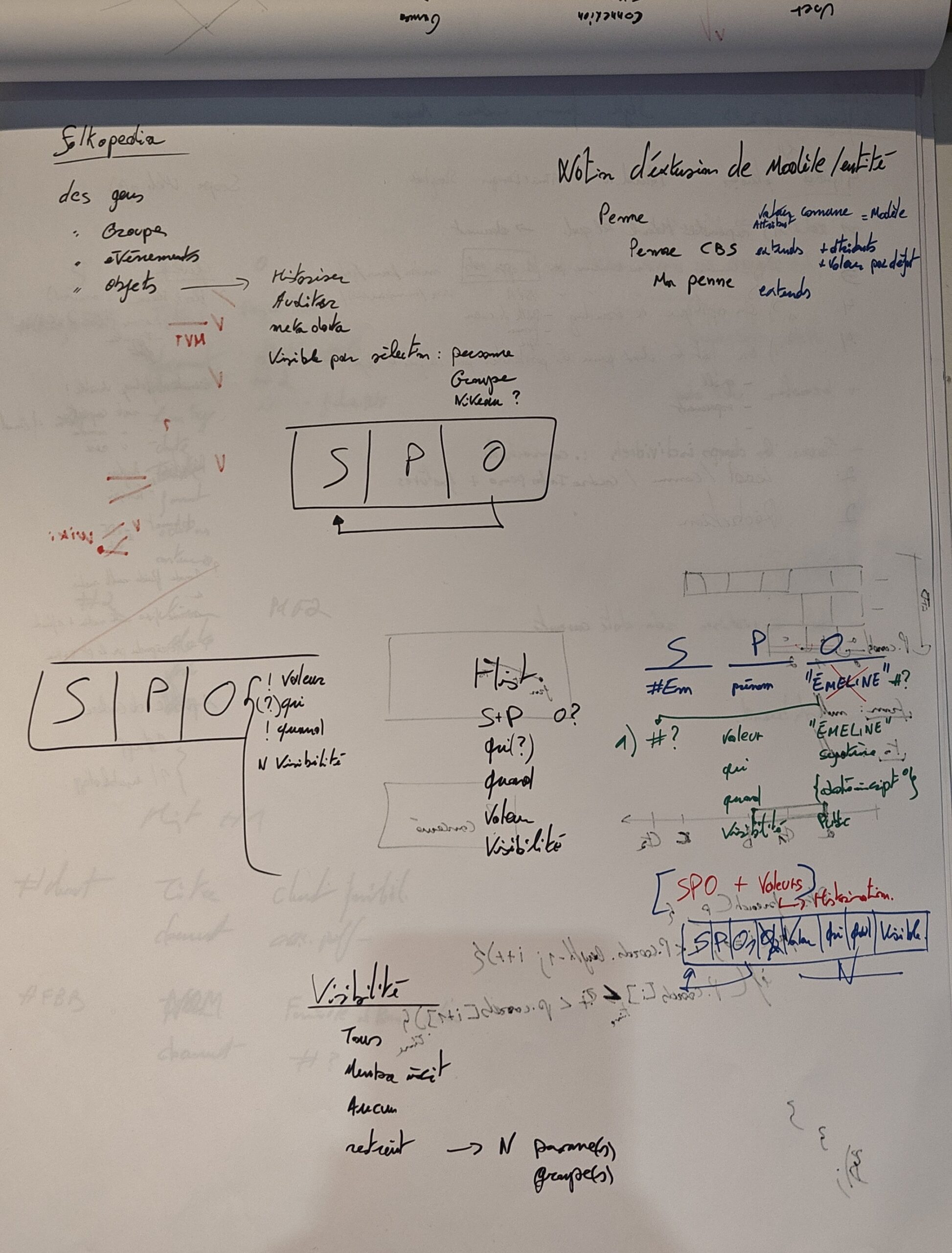
Cet article est une réflexion faisant suite à l’article concernant l’explication de mon approche ontologique et de la structure des données du projet Folkopedia avec un retour d’expériences.
Initialement nous avons notre ligne ontologique telle que :
S, P, O, V, Qui, Quand, Visibilité, Ordre
Avec pour lecture :
- Sujet
- Prédicat
- Objet au sens pointeur vers un sujet
- Valeur primitive de l’objet (c’est valeur ou objet mais pas les 2 en même temps)
- Qui a créé ou éditer la ligne en dernier
- Quand est-ce que ça été créé ou édité en dernier
- Visibilité au sens de qui peut consulter cette valeur
- Ordre au sens de l’ordonnancement des prédicats et valeurs
Les problèmes rencontrés
- D’abord un truc gênant concernant l’ordre, celui-ci n’est pas toujours nécessaire et c’est donc une colonne qui n’a pas toujours de sens.
- Dans le cas où un prédicat a plusieurs valeurs, celle-ci ne sont pas ordonnées, excepté par l’ordre d’insertion.
- La valeur elle-même peut avoir une historisation comme discuté ce qui demande un Sujet, du coup quid de la valeur primitive ?
- Comment être SPO sans avoir 2 colonnes pour respecter les théories SGBD ? Comment gérer les 2 en 1 et différencier au bon moment ?
- L’audit Qui et Quand n’est pas historisé, ce qui est un manque à l’objectif, pareil pour Visibilité et Ordre.
Solutions ?
Déjà reprenons le point n° 2. Elles peuvent être ordonnée si on utilise la colonne Ordre. Là où elle ne le sont pas, c’est dans le système actuel, où le fait d’avoir un objet ayant pour clef le prédicat et les valeurs simplifiées en tableau perdent cette notion. De plus la requête actuelle ne l’extrait pas.
Ceci mis à part, le constat est que les colonnes Qui, Quand, Visibilité et Ordre ne sont pas correcte, supprimons les et regardons comment respecter l’énoncée de départ.
S, P, O, V
Si on projette un exemple, nous aurons :
| Sujet | Prédicat | Objet | Valeur |
| #entity1 | Surnom | null | Killan |
Là on a une Valeur primitive pour un Prédicat d’un Sujet. Mais si on veut rajouter les 4 colonnes retirées, en suivant le modèle ontologique, nous allons devoir faire ainsi :
| Sujet | Prédicat | Objet | Valeur |
| #entity1 | Surnom | #entity2 | null |
| #entity2 | AuditQui | #entity1 | null |
| #entity2 | AuditQuand | null | 2025-02-13 21:08… |
| #entity2 | Visibilité | #entity39 | null |
| #entity2 | Ordre | null | 1 |
Visibilité pourrait même être défini au niveau du Prédicat, par défaut, et supplanté par l’utilisateur potentiellement. La valeur disparait au profit d’une nouvelle entité contenant les informations relatives, mais la valeur a disparu, on la rajoute :
| Sujet | Prédicat | Objet | Valeur |
| #entity2 | Valeur | null | Killan |
Dès lors nous avons tout à nouveau, on est complet et il n’y a plus qu’à faire une requête pour chaque prédicat, simple… POUR CHAQUE PRÉDICAT ! Déjà que la console du système n’est pas triste avec le peu qu’on a fait jusque là, mais si en plus on double… Et en plus il faudra potentiellement trier les lignes reçues pour les identifier d’une certaine manière par les prédicats.
Réflexions sur la valeur
Si on observe le résultat, dans ce cas-ci, Objet est utilisé 50% du temps et Valeur 50%, équilibré en soit, mais plus largement ça sera surtout la colonne Objet qui sera attribuée. La valeur primitive est largement moins sollicitée.
De plus, si nous avons comme contenu l’historique complet d’un groupe folklorique, qui plus est formatté par exemple, nous allons avoir une quantité folle de données dans ce champs de manière anecdotique et là je me dis qu’on passe à côté de quelque chose.
On est d’accord qu’on n’enregistre pas un document ou une image dans ce champs, du coup, les contenus potentiellement massif, ou identifiés comme tels, ne devraient pas y être non plus. Cela n’a pas d’intérêt ontologique ou structurel.
Nous avions imaginé qu’une image serait parsemée de légendes, de tags, et de commentaires, ce qui à la fois contient des informations larges et d’autres courtes. Le tout pouvant faire l’objet d’une recherche. On peut partir dans tous les sens alors car il faut indexer du contenu pour chercher dedans. Pour ce faire, ce n’est pas à l’ontologie de s’en occuper, elle ne garanti que le lien entre les informations et la structure générale par ses définitions.
On peut imaginer un système annexe comme une table de contenus, ou un système comme un Elasticsearch. Le système de recherche ferait une demande à ces systèmes qui permettrait de relier un (ou plusieurs) Sujet(s) de l’ontologie. Ça semble cohérent.
Si on extrait les contenus large comme des documents et des images, il va falloir penser à une technique pour les relier dans l’ontologie. Comment écrire que la Valeur ou l’Objet fait référence à une structure externe ?
subject UUID not null, predicate UUID not null, object UUID, o_value TEXT,
Petit extrait de notre table ontology pour vous montrer que les colonnes sont fortement typées. On ne peut pas indiquer n’importe quoi dans object. Et o_value, sur base de ce que l’on vient de dire, devrait devenir un varchar dont la longueur X est encore à définir, en soit si inférieur à X alors valeur courte et si supérieur à X alors contenu large externalisé.
Soit on garde la théorie SGBD avec notre clé secondaire (FK) pointant vers une clé primaire (PK), en dur dans le marbre bien respectueux et on garde une colonne Valeur en tant que varchar. Soit on transforme les 2 en une seule, de type JSON ou varchar. L’avantage du varchar est l’indexation pour définir un index et/ou une PK globale, permettant de valider l’unicité du Triplet. Avantages et inconvénients de chaque approche.
On peut également partir sur le principe de diviser la table en 2-3 pour séparer les colonne du fait de l’exclusivité mutuelle. Une table SPO et une table SPV, voire une table SP de référence centrale. C’est le code qui doit alors rassembler les morceaux. (Clin d’œil à Julian pour le rappel)
Là où ça se corse, quelque soit la solution, c’est l’identification extérieure. Comment interpréter Valeur ? On pourrait préfixer le contenu, tel que :
- doc:refdoc#1
- img:refimg#1
- txt:reftxtlarge#1
- v:Killan
Le symbole « deux points » ( : ) nous permettant, telle une sérialisation, de faire la part des choses, sans empêcher l’usage dudit caractère dans sa partie droite, à vérifier bien sur ou a encapsuler dans des guillemets ( » » ). Attention tout de même de ne pas devenir une usine pour peu d’intérêts. Les images, textes et documents font partie du cœur de l’objectif, donc jusque là pas de soucis, on en prend soin.
On peut imaginer que la partie ref (refdoc#1, refimg#1, reftxtlarge#1) pointe sur une table autre que ontology avec comme valeur un chemin vers le fichier avec peut-être des propriétés système de ce fichier (nom, taille, format) dont l’intérêt ne sera pas ontologique et plutôt commun au système de référence.
Dans le cas d’une valeur primitive ( v: ou v: » … « ), là on interprète la valeur directement. J’en rajoute une couche avec la traduction ? Doit-on traduire la valeur en elle-même ou est-ce que le prédicat sera démultiplier avec un attribut supplémentaire pour contenir cette différenciation, ça demandera pas mal de requêtes, mais ça fonctionnerait.
| Sujet | Prédicat | Objet | Valeur |
| #entity3 | Titre | #entity4 | null |
| #entity4 | AuditQui | #entity1 | null |
| #entity4 | AuditQuand | null | v: »2025-02-13 21:45:27 … » |
| #entity4 | Visibilité | #entity39 | null |
| #entity4 | Ordre | null | v: »1″ |
| #entity4 | Valeur | null | v: »Un titre un peu long qi pourrait poser un certain soucis quelque part » |
| #entity4 | Lang | null | v: »fr_be » |
| #entity3 | Titre | #entity5 | null |
| #entity5 | … | … | … |
| #entity5 | Valeur | null | v: »A somewhat long title which could cause some problems somewhere » |
| #entity5 | Lang | null | v: »en_en » |
Mais philosophiquement, n’est pas la même entité qui est traduite ? Serait-ce alors plusieurs clefs Valeur avec un code de langue du texte ?
| Sujet | Prédicat | Objet | Valeur |
| #entity4 | … | … | … |
| #entity4 | Valeur | null | v:fr_fr: »Un titre un peu long qi pourrait poser un certain soucis quelque part » |
| #entity4 | Valeur | null | v:en_en: »A somewhat long title which could cause some problems somewhere » |
Le principe ontologique est respecté, un prédicat et plusieurs valeurs, mais notre colonne valeur demande toute une interprétation. Ou alors, on pousse le bouchon encore plus loin et quelque soit la valeur devient un Sujet.
| Sujet | Prédicat | Objet | Valeur |
| #entity4 | … | … | … |
| #entity4 | Valeur | #entity7 | null |
| #entity7 | Type | #entity46 | null |
| #entity7 | Contenu | null | Un titre un peu long qi pourrait poser un certain soucis quelque part |
| #entity7 | Lang | null | fr_fr |
| #entity4 | Valeur | #entity8 | null |
| #entity8 | Type | #entity46 | null |
| #entity8 | Contenu | null | A somewhat long title which could cause some problems somewhere |
| #entity8 | Lang | null | en_en |
Et là c’est top côté ontologie, il nous faut :
- 1 requête pour avoir la référence du Sujet
- 1 requête pour avoir tous les prédicats du Sujet
- 1 requête par Prédicat pour déterminer sa nature (peut-être à conditionner selon que la colonne Objet ou Valeur est utilisée)
- 1 requête par Prédicat ayant une valeur sous forme de Sujet
À savoir un minimum de 6 requêtes, au lieu de 1 en début d’article (1 pour trouver le Sujet puis 1 pour avoir ses Prédicats, ou les 2 d’un coup si on a déjà la première info).
D’où l’importance des choix avant même de penser aux optimisations techniques.
Historisation
Nous ne sommes pas revenu sur l’historisation et là il y a 2 possibilités. Soit on part de la valeur que l’on encapsule virtuellement par répétition du prédicat, il faudra trouver la valeur la plus récente :
| Sujet | Prédicat | Objet | Valeur |
| #entity3 | Titre | #entity4 | null |
| #entity4 | AuditQuand | null | /date1/ |
| #entity3 | Titre | #entity5 | null |
| #entity5 | AuditQuand | null | /date2/ |
Soit par ligne individuelle, ce qui nous demandera de faire un travail différenciel pour recomposer le cheminement de l’information dans le temps, mais au final on en revient à la structure précédent Qui, Quand, Valeur. On pourrait imaginer un chainage, modifier la valeur entraine un nouveau bloc Valeur qui chaine en s’intercalant, comme en C avec les listes chaînée.
| Sujet | Prédicat | Objet | Valeur |
| #entity3 | Titre | #entity5 | null |
| #entity5 | HistPrécédant | #entity4 | null |
| #entity4 |
La valeur
Revenons maintenant sur la valeur (Objet, Valeur). Ils sont mutuellement exclusif et comme dit plus tôt, il y a plusieurs solutions.
- Soit diviser la table ontology en 2-3, ce qui, pour moi, ne correspond pas à l’idée de l’ontologie.
- Soit fusionner la colonne Objet et Valeur en une seul de type varchar dont le contenu peut être déterminé comme vu précédemment.
Si on considère la seconde option, il faut parler du Prédicat qui nous donne déjà des informations de Type, donc en soit le type de valeur n’est à faire que dans le cadre d’un Prédicat Valeur. J’y vois déjà une arborescence de Types de Valeurs et de Prédicats relatifs. Le but est de toujours savoir comment interpréter la valeur.
Transposer les solutions
Si on essaye de tout regrouper pour voir si ça fonctionne virtuellement, prenons l’exemple de mon surnom.
| Sujet | Prédicat | Objet (valeur) | Explication |
| #entity1 | Surnom | #entity8 | |
| #entity8 | Type | #entity3 | Entité de type Valeur |
| #entity8 | Qui | #entity1 | |
| #entity8 | Quand | /date1/ | Quand est de type date |
| #entity8 | Visibilité | #entity4 | |
| #entity8 | Ordre | 1 | Ordre est de type nombre |
| #entity8 | ValeurContenu | #entity7 | Entité de type contenu/valeur |
| #entity7 | Type | #entity6 | |
| #entity7 | Lang | fr_be | |
| #entity7 | Contenu | Killan | |
| #entity8 | HistPrec | #entity2 | |
| #entity2 | Type | #entity3 | Ancienne capsule pour la valeur |
| #entity2 | Qui | #entity1 | |
| #entity2 | Quand | /date2/ | |
| #entity2 | Visibilité | #entity4 | |
| #entity2 | Ordre | 1 | |
| #entity2 | ValeurContenu | #entity5 | |
| #entity5 | Type | #entity6 | Ancienne valeur |
| #entity5 | Lang | fr_fr | |
| #entity5 | Contenu | Kilan | |
Traduisons tout cela :
- On a un Sujet me représentant #entity1 avec un Prédicat Surnom qui a une valeur #entity8,
- #entity8 est pourvu des Prédicats permettant d’auditer la valeur et d’obtenir la valeur #entity7,
- #entity7 est un Sujet ayant la valeur finale pour une langue initiale,
- #entity8 à une valeur précédente en #entity2 pour corriger une typo (ça aurait pu être un changement de visibilité ou d’ordre),
- #entity2 est pourvu des Prédicats permettant d’auditer la valeur et d’obtenir la valeur #entity5 également, et ici elle n’a pas de valeur précédente,
Attention aux noms des Types : Surnom, Valeur, Contenu et ContenuValeur; il va falloir y prêter attention pour ne pas se perdre en chemin. Peut-être est-ce toute une chaîne typée héritée de types respectifs plus macro comme les modèles.
En gros on a fait x10 à notre ligne initiale, et on corrige nos soucis d’historisation, de stockage de valeur et de typage. C’est le programme qui va se perdre en requêtes et recomposition d’un information intelligible pour traitement. Dans un sens comme dans l’autre. :/
2 requêtes pour la valeur d’un Prédicat qui a déjà demandé 1-2 requête(s). Et l’historique, ainsi que l’audit, à la demande dans des requêtes annexes par 2n.
Optimisation
Comme vous l’aurez compris ça va coûter cher en requêtes et temps de processus. On a une table déjà énorme en prévision, si en plus on a l’historisation aussi verticale ça va devenir longuet. Vient une idée (merci Adrien), de sortir la partie historique de la table ontology, de ne garder que l’instant courant dans celle-ci et de sortir le reste en dehors, vu que son taux de consultation sera bien bien moindre. On aurait donc une table historique contenant une structure légère afin de pointer le Sujet adéquat dans l’ontologie, voire même un Prédicat, à voir, et à stocker sa valeur précédente. En gros une capture de l’objet et descendants directement liés et stocker sous format JSON.
Dans l’exemple précédent on aurait alors #entity2 et #entity5 de sorti dans ce format JSON et stocké en historique, pointant #entity1:Surnom. Le reste serait une ordonnancement par date par exemple.
Validation de contenu
De part la volonté communautaire du projet et d’autogestion/autorégulation par la communauté, une valeur doit être approuvée, toute ou partiellement selon le type d’information. Cette nouvelle structure nous permet d’ajouter des Prédicats de contrôles.
| Sujet | Prédicat | Objet (valeur) |
| #entity17 | Validation | #entity1 |
Le Prédicat pouvant être multiple, on peut avoir plusieurs validateur et la validation peut être à son tour un objet déterminant un commentaire et une valeur d’approbation et date. Cela peut être un refus commenté par exemple. C’est au système ensuite de considérer ou non la valeur. Dans le cas d’un correctif refusé, le système doit aller chercher la valeur initiale si approuvée. Je vous laisse imaginer le bazar futur.
Conclusion
Nous voilà revenu à notre structure la plus pure et théorique :
S, P, O
Dont O est un V encapsulé et dont il faudra définir l’entité avec soin.
subject UUID not null, predicate UUID not null, object VARCHAR(X) not null,
Adieu facilité ! Bonjour complexité et flexibilité…
Il ne me reste plus qu’à réécrire la moulinette de conversion, créer les nouvelles structures d’entités et créer les outils nécessaires pour gérer ça plus facilement, et évidemment revoir le lien front OntologyMyAdmin en profondeur du coup.
Rien que ça… ^^