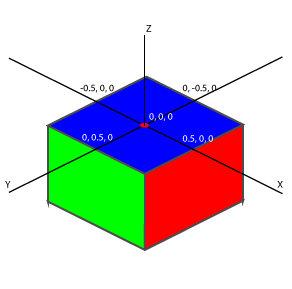
Voulant écrire un nouvel article au sujet de l’ontologie et des valeurs, j’ai souhaité mieux transposer mes propos en les illustrant. De prime à bord je partais sur un graph, tel que :
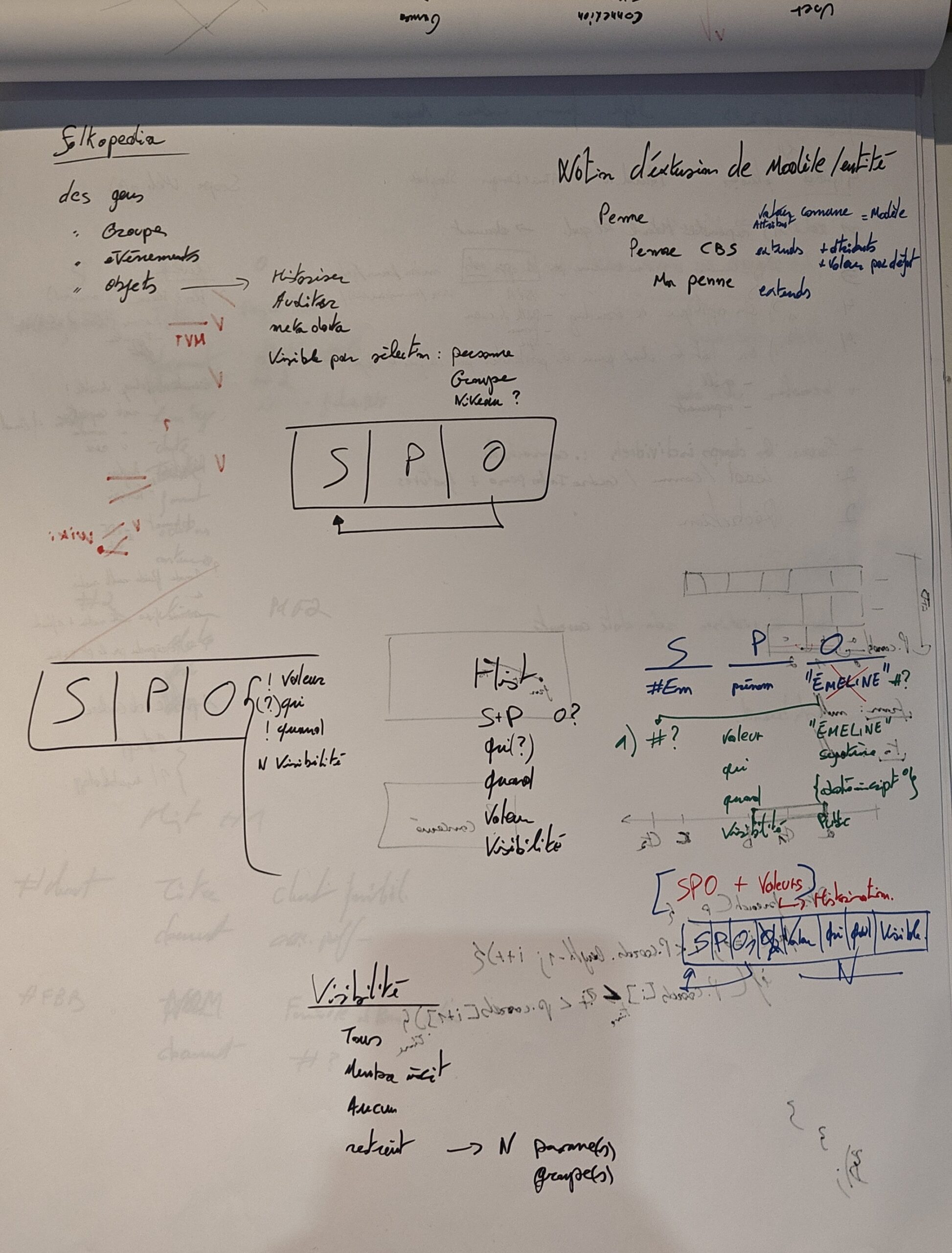
SPO d’un livre ayant pour Titre « Titre du livre »
Où le Sujet S représente un livre, ayant un Prédicat P « Titre » et ayant pour Objet O une valeur texte « Titre du livre ».
Mais ceci contient un souci de représentation, bien que l’on comprenne aisément la relation d’un Sujet et de l’Objet via un Prédicat, cela nous empêche de comprendre le Prédicat lui-même. Car oui le Prédicat peut être développé lui aussi.
Vue du Prédicat
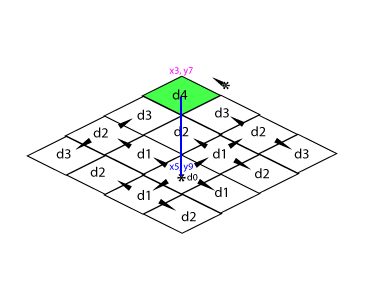
Avant ça, poussons le bouchon plus loin en transformant l’Objet O en un nouveau S :
SPO d’un livre dont la valeur du Titre contient des métadonnées
L’Objet valeur devient un Sujet à son tour qui a des Prédicats eux-mêmes pointant vers des valeurs finies (primitives) ou des Sujets. Mais on a cette intuition que le Prédicat n’est qu’un lien, un mot sur une liaison, alors qu’ils sont bien plus que ça.
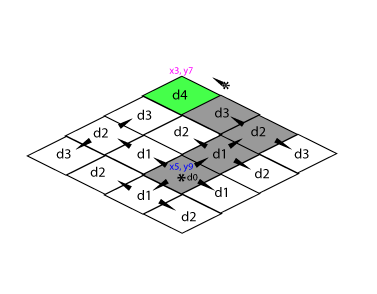
Illustration de la complexité des liaisons des Prédicats
Le Prédicat est à la fois l’attribut liant le Sujet à l’Objet mais également un Sujet à part entière ayant ses propres liaisons vers des Objets au travers de Prédicats, parfois les mêmes, et ainsi de suite. Et encore ici nous n’avons pas illustré l’usage multiple, ça deviendrait illisible. Imaginez plusieurs « Livre » passant par le Prédicat « Prédicat#Titre » et allant vers un Objet distinct chacun.
Illustration de l’usage multiple de la référence d’un Prédicat pour plusieurs Sujets et Objets
Vous en conviendrez c’est un beau bordel. Et encore j’ai mis des couleurs pour votre lecture. Car sinon on pourrait dire qu’un livre a plusieurs Titre, ce qui est tout à fait admissible par le modèle SPO.
Proposition de représentation
Cette représentation n’est donc pas idéale, mais quid alors ? Je vous propose une transformation en objet et une vue en tables.
Comme vous pouvez le voir j’ai gardé les codes couleur des exemples précédents, à savoir le noir pour les Sujets et le bleu pour les Objet à valeur de type primitive. Considérez « Type », « Titre » et « Type#Livre » tel que « Livre », à savoir un Sujet, je n’ai pas illustré la table dessous chacun pour éviter la surcharge graphique.
On a donc le Sujet « Livre » ayant un Prédicat « Type » d’Objet « Type#Livre », qui donc est lui-même un Sujet, et un Prédicat « Titre » d’Objet de valeur texte « Titre du livre ». Ça c’est dans le cas simple illustré en début d’article. J’ai juste ajouté le Prédicat « Type » pour illustrer 2 types d’Objet.
Si maintenant nous avons des métadonnées sur la valeur « Titre du livre », cet Objet devient un Sujet, c’est-à-dire que l’on va encapsuler dans un nouveau Sujet, la valeur initiale et tout autre attribut venant des métadonnées de cette valeur. Dans notre exemple, j’ajoute l’ordre et la date de création. Et évidemment comme nous créons un nouveau sujet, nous le typons, et c’est là que vous voyez la réutilisation du Prédicat « Type » de manière distincte.
Autre point d’intérêt, le Sujet « Type#Contenu », qui est, à la fois valeur d’un Objet pour le Prédicat « Type », et à la fois Prédicat, pour la valeur « Titre du livre ». Ce qui est tout à fait correcte et illustre parfaitement ce dont nous parlions plus tôt. Ici nous pouvons « voir », l’implication des Sujets, leur connexions et les valeurs primitives associées.
Mais quant est-il dans le cas où nous avons plusieurs valeurs pour un même Prédicat ? Une solution, illustrée ci-avant, serait de partir du Prédicat et d’aller vers nos 2 Sujets en Objet. Et on peut débattre de la représentation, à savoir tel que représenté ci-avant, 1 devient N. Ou comme ci-dessous, ou nous créons 3 associations.
Je pense que les 2 devraient se combiner, la première permet une économie de représentation tout en restant compréhensible- et la seconde permet de bien illustrer les valeurs et leur Prédicat. Même si on pourrait simplifier peut-être tel que :
Le tout étant de rester lisible à la première lecture et sans ambiguïté. Je pense du coup que l’objectif est atteint et que l’on va pouvoir passer aux articles suivants avec un système de représentation plus accessible.
Initialement nous avons notre ligne ontologique telle que :
S, P, O, V, Qui, Quand, Visibilité, Ordre
Avec pour lecture :
Sujet
Prédicat
Objet au sens pointeur vers un sujet
Valeur primitive de l’objet (c’est valeur ou objet mais pas les 2 en même temps)
Qui a créé ou éditer la ligne en dernier
Quand est-ce que ça été créé ou édité en dernier
Visibilité au sens de qui peut consulter cette valeur
Ordre au sens de l’ordonnancement des prédicats et valeurs
Les problèmes rencontrés
D’abord un truc gênant concernant l’ordre, celui-ci n’est pas toujours nécessaire et c’est donc une colonne qui n’a pas toujours de sens.
Dans le cas où un prédicat a plusieurs valeurs, celle-ci ne sont pas ordonnées, excepté par l’ordre d’insertion.
La valeur elle-même peut avoir une historisation comme discuté ce qui demande un Sujet, du coup quid de la valeur primitive ?
Comment être SPO sans avoir 2 colonnes pour respecter les théories SGBD ? Comment gérer les 2 en 1 et différencier au bon moment ?
L’audit Qui et Quand n’est pas historisé, ce qui est un manque à l’objectif, pareil pour Visibilité et Ordre.
Solutions ?
Déjà reprenons le point n° 2. Elles peuvent être ordonnée si on utilise la colonne Ordre. Là où elle ne le sont pas, c’est dans le système actuel, où le fait d’avoir un objet ayant pour clef le prédicat et les valeurs simplifiées en tableau perdent cette notion. De plus la requête actuelle ne l’extrait pas.
Ceci mis à part, le constat est que les colonnes Qui, Quand, Visibilité et Ordre ne sont pas correcte, supprimons les et regardons comment respecter l’énoncée de départ.
S, P, O, V
Si on projette un exemple, nous aurons :
Sujet
Prédicat
Objet
Valeur
#entity1
Surnom
null
Killan
Là on a une Valeur primitive pour un Prédicat d’un Sujet. Mais si on veut rajouter les 4 colonnes retirées, en suivant le modèle ontologique, nous allons devoir faire ainsi :
Sujet
Prédicat
Objet
Valeur
#entity1
Surnom
#entity2
null
#entity2
AuditQui
#entity1
null
#entity2
AuditQuand
null
2025-02-13 21:08…
#entity2
Visibilité
#entity39
null
#entity2
Ordre
null
1
Visibilité pourrait même être défini au niveau du Prédicat, par défaut, et supplanté par l’utilisateur potentiellement. La valeur disparait au profit d’une nouvelle entité contenant les informations relatives, mais la valeur a disparu, on la rajoute :
Sujet
Prédicat
Objet
Valeur
#entity2
Valeur
null
Killan
Dès lors nous avons tout à nouveau, on est complet et il n’y a plus qu’à faire une requête pour chaque prédicat, simple… POUR CHAQUE PRÉDICAT ! Déjà que la console du système n’est pas triste avec le peu qu’on a fait jusque là, mais si en plus on double… Et en plus il faudra potentiellement trier les lignes reçues pour les identifier d’une certaine manière par les prédicats.
Réflexions sur la valeur
Si on observe le résultat, dans ce cas-ci, Objet est utilisé 50% du temps et Valeur 50%, équilibré en soit, mais plus largement ça sera surtout la colonne Objet qui sera attribuée. La valeur primitive est largement moins sollicitée.
De plus, si nous avons comme contenu l’historique complet d’un groupe folklorique, qui plus est formatté par exemple, nous allons avoir une quantité folle de données dans ce champs de manière anecdotique et là je me dis qu’on passe à côté de quelque chose.
On est d’accord qu’on n’enregistre pas un document ou une image dans ce champs, du coup, les contenus potentiellement massif, ou identifiés comme tels, ne devraient pas y être non plus. Cela n’a pas d’intérêt ontologique ou structurel.
Nous avions imaginé qu’une image serait parsemée de légendes, de tags, et de commentaires, ce qui à la fois contient des informations larges et d’autres courtes. Le tout pouvant faire l’objet d’une recherche. On peut partir dans tous les sens alors car il faut indexer du contenu pour chercher dedans. Pour ce faire, ce n’est pas à l’ontologie de s’en occuper, elle ne garanti que le lien entre les informations et la structure générale par ses définitions.
On peut imaginer un système annexe comme une table de contenus, ou un système comme un Elasticsearch. Le système de recherche ferait une demande à ces systèmes qui permettrait de relier un (ou plusieurs) Sujet(s) de l’ontologie. Ça semble cohérent.
Si on extrait les contenus large comme des documents et des images, il va falloir penser à une technique pour les relier dans l’ontologie. Comment écrire que la Valeur ou l’Objet fait référence à une structure externe ?
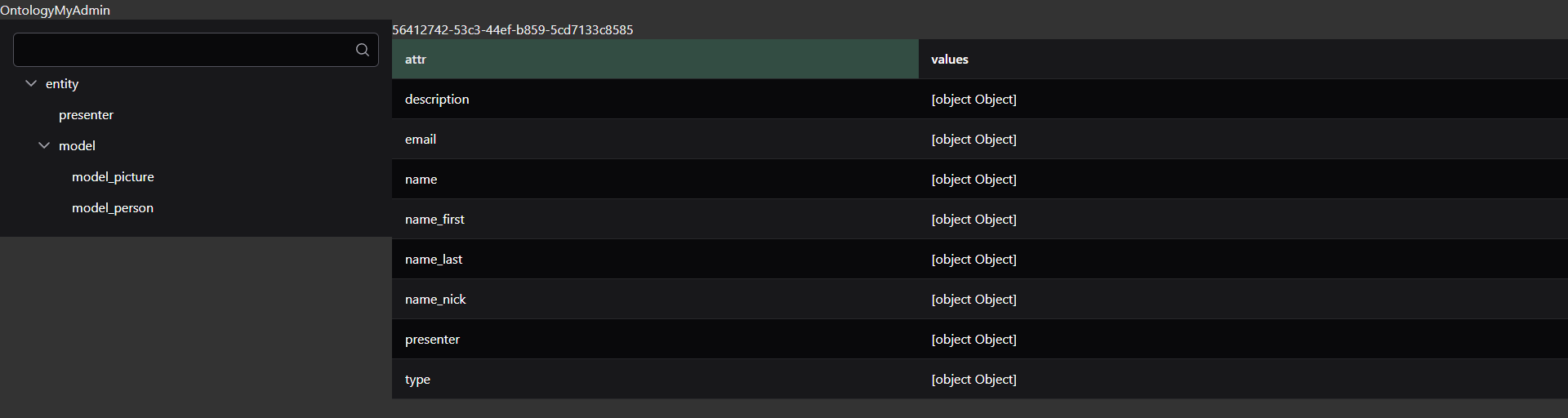
subject UUID not null,
predicate UUID not null,
object UUID,
o_value TEXT,
Petit extrait de notre table ontology pour vous montrer que les colonnes sont fortement typées. On ne peut pas indiquer n’importe quoi dans object. Et o_value, sur base de ce que l’on vient de dire, devrait devenir un varchar dont la longueur X est encore à définir, en soit si inférieur à X alors valeur courte et si supérieur à X alors contenu large externalisé.
Soit on garde la théorie SGBD avec notre clé secondaire (FK) pointant vers une clé primaire (PK), en dur dans le marbre bien respectueux et on garde une colonne Valeur en tant que varchar. Soit on transforme les 2 en une seule, de type JSON ou varchar. L’avantage du varchar est l’indexation pour définir un index et/ou une PK globale, permettant de valider l’unicité du Triplet. Avantages et inconvénients de chaque approche.
On peut également partir sur le principe de diviser la table en 2-3 pour séparer les colonne du fait de l’exclusivité mutuelle. Une table SPO et une table SPV, voire une table SP de référence centrale. C’est le code qui doit alors rassembler les morceaux. (Clin d’œil à Julian pour le rappel)
Là où ça se corse, quelque soit la solution, c’est l’identification extérieure. Comment interpréter Valeur ? On pourrait préfixer le contenu, tel que :
doc:refdoc#1
img:refimg#1
txt:reftxtlarge#1
v:Killan
Le symbole « deux points » ( : ) nous permettant, telle une sérialisation, de faire la part des choses, sans empêcher l’usage dudit caractère dans sa partie droite, à vérifier bien sur ou a encapsuler dans des guillemets ( » » ). Attention tout de même de ne pas devenir une usine pour peu d’intérêts. Les images, textes et documents font partie du cœur de l’objectif, donc jusque là pas de soucis, on en prend soin.
On peut imaginer que la partie ref (refdoc#1, refimg#1, reftxtlarge#1) pointe sur une table autre que ontology avec comme valeur un chemin vers le fichier avec peut-être des propriétés système de ce fichier (nom, taille, format) dont l’intérêt ne sera pas ontologique et plutôt commun au système de référence.
Dans le cas d’une valeur primitive ( v: ou v: » … « ), là on interprète la valeur directement. J’en rajoute une couche avec la traduction ? Doit-on traduire la valeur en elle-même ou est-ce que le prédicat sera démultiplier avec un attribut supplémentaire pour contenir cette différenciation, ça demandera pas mal de requêtes, mais ça fonctionnerait.
Sujet
Prédicat
Objet
Valeur
#entity3
Titre
#entity4
null
#entity4
AuditQui
#entity1
null
#entity4
AuditQuand
null
v: »2025-02-13 21:45:27 … »
#entity4
Visibilité
#entity39
null
#entity4
Ordre
null
v: »1″
#entity4
Valeur
null
v: »Un titre un peu long qi pourrait poser un certain soucis quelque part »
#entity4
Lang
null
v: »fr_be »
#entity3
Titre
#entity5
null
#entity5
…
…
…
#entity5
Valeur
null
v: »A somewhat long title which could cause some problems somewhere »
#entity5
Lang
null
v: »en_en »
Mais philosophiquement, n’est pas la même entité qui est traduite ? Serait-ce alors plusieurs clefs Valeur avec un code de langue du texte ?
Sujet
Prédicat
Objet
Valeur
#entity4
…
…
…
#entity4
Valeur
null
v:fr_fr: »Un titre un peu long qi pourrait poser un certain soucis quelque part »
#entity4
Valeur
null
v:en_en: »A somewhat long title which could cause some problems somewhere »
Le principe ontologique est respecté, un prédicat et plusieurs valeurs, mais notre colonne valeur demande toute une interprétation. Ou alors, on pousse le bouchon encore plus loin et quelque soit la valeur devient un Sujet.
Sujet
Prédicat
Objet
Valeur
#entity4
…
…
…
#entity4
Valeur
#entity7
null
#entity7
Type
#entity46
null
#entity7
Contenu
null
Un titre un peu long qi pourrait poser un certain soucis quelque part
#entity7
Lang
null
fr_fr
#entity4
Valeur
#entity8
null
#entity8
Type
#entity46
null
#entity8
Contenu
null
A somewhat long title which could cause some problems somewhere
#entity8
Lang
null
en_en
Et là c’est top côté ontologie, il nous faut :
1 requête pour avoir la référence du Sujet
1 requête pour avoir tous les prédicats du Sujet
1 requête par Prédicat pour déterminer sa nature (peut-être à conditionner selon que la colonne Objet ou Valeur est utilisée)
1 requête par Prédicat ayant une valeur sous forme de Sujet
À savoir un minimum de 6 requêtes, au lieu de 1 en début d’article (1 pour trouver le Sujet puis 1 pour avoir ses Prédicats, ou les 2 d’un coup si on a déjà la première info).
D’où l’importance des choix avant même de penser aux optimisations techniques.
Historisation
Nous ne sommes pas revenu sur l’historisation et là il y a 2 possibilités. Soit on part de la valeur que l’on encapsule virtuellement par répétition du prédicat, il faudra trouver la valeur la plus récente :
Sujet
Prédicat
Objet
Valeur
#entity3
Titre
#entity4
null
#entity4
AuditQuand
null
/date1/
#entity3
Titre
#entity5
null
#entity5
AuditQuand
null
/date2/
Solution de plusieurs valeurs pour l’historisation
Soit par ligne individuelle, ce qui nous demandera de faire un travail différenciel pour recomposer le cheminement de l’information dans le temps, mais au final on en revient à la structure précédent Qui, Quand, Valeur. On pourrait imaginer un chainage, modifier la valeur entraine un nouveau bloc Valeur qui chaine en s’intercalant, comme en C avec les listes chaînée.
Sujet
Prédicat
Objet
Valeur
#entity3
Titre
#entity5
null
#entity5
HistPrécédant
#entity4
null
#entity4
Chaînage de l’historique
La valeur
Revenons maintenant sur la valeur (Objet, Valeur). Ils sont mutuellement exclusif et comme dit plus tôt, il y a plusieurs solutions.
Soit diviser la table ontology en 2-3, ce qui, pour moi, ne correspond pas à l’idée de l’ontologie.
Soit fusionner la colonne Objet et Valeur en une seul de type varchar dont le contenu peut être déterminé comme vu précédemment.
Si on considère la seconde option, il faut parler du Prédicat qui nous donne déjà des informations de Type, donc en soit le type de valeur n’est à faire que dans le cadre d’un Prédicat Valeur. J’y vois déjà une arborescence de Types de Valeurs et de Prédicats relatifs. Le but est de toujours savoir comment interpréter la valeur.
Transposer les solutions
Si on essaye de tout regrouper pour voir si ça fonctionne virtuellement, prenons l’exemple de mon surnom.
Sujet
Prédicat
Objet (valeur)
Explication
#entity1
Surnom
#entity8
#entity8
Type
#entity3
Entité de type Valeur
#entity8
Qui
#entity1
#entity8
Quand
/date1/
Quand est de type date
#entity8
Visibilité
#entity4
#entity8
Ordre
1
Ordre est de type nombre
#entity8
ValeurContenu
#entity7
Entité de type contenu/valeur
#entity7
Type
#entity6
#entity7
Lang
fr_be
#entity7
Contenu
Killan
#entity8
HistPrec
#entity2
#entity2
Type
#entity3
Ancienne capsule pour la valeur
#entity2
Qui
#entity1
#entity2
Quand
/date2/
#entity2
Visibilité
#entity4
#entity2
Ordre
1
#entity2
ValeurContenu
#entity5
#entity5
Type
#entity6
Ancienne valeur
#entity5
Lang
fr_fr
#entity5
Contenu
Kilan
Traduisons tout cela :
On a un Sujet me représentant #entity1 avec un Prédicat Surnom qui a une valeur #entity8,
#entity8 est pourvu des Prédicats permettant d’auditer la valeur et d’obtenir la valeur #entity7,
#entity7 est un Sujet ayant la valeur finale pour une langue initiale,
#entity8 à une valeur précédente en #entity2 pour corriger une typo (ça aurait pu être un changement de visibilité ou d’ordre),
#entity2 est pourvu des Prédicats permettant d’auditer la valeur et d’obtenir la valeur #entity5 également, et ici elle n’a pas de valeur précédente,
Attention aux noms des Types : Surnom, Valeur, Contenu et ContenuValeur; il va falloir y prêter attention pour ne pas se perdre en chemin. Peut-être est-ce toute une chaîne typée héritée de types respectifs plus macro comme les modèles.
En gros on a fait x10 à notre ligne initiale, et on corrige nos soucis d’historisation, de stockage de valeur et de typage. C’est le programme qui va se perdre en requêtes et recomposition d’un information intelligible pour traitement. Dans un sens comme dans l’autre. :/
2 requêtes pour la valeur d’un Prédicat qui a déjà demandé 1-2 requête(s). Et l’historique, ainsi que l’audit, à la demande dans des requêtes annexes par 2n.
Optimisation
Comme vous l’aurez compris ça va coûter cher en requêtes et temps de processus. On a une table déjà énorme en prévision, si en plus on a l’historisation aussi verticale ça va devenir longuet. Vient une idée (merci Adrien), de sortir la partie historique de la table ontology, de ne garder que l’instant courant dans celle-ci et de sortir le reste en dehors, vu que son taux de consultation sera bien bien moindre. On aurait donc une table historique contenant une structure légère afin de pointer le Sujet adéquat dans l’ontologie, voire même un Prédicat, à voir, et à stocker sa valeur précédente. En gros une capture de l’objet et descendants directement liés et stocker sous format JSON.
Dans l’exemple précédent on aurait alors #entity2 et #entity5 de sorti dans ce format JSON et stocké en historique, pointant #entity1:Surnom. Le reste serait une ordonnancement par date par exemple.
Validation de contenu
De part la volonté communautaire du projet et d’autogestion/autorégulation par la communauté, une valeur doit être approuvée, toute ou partiellement selon le type d’information. Cette nouvelle structure nous permet d’ajouter des Prédicats de contrôles.
Sujet
Prédicat
Objet (valeur)
#entity17
Validation
#entity1
Le Prédicat pouvant être multiple, on peut avoir plusieurs validateur et la validation peut être à son tour un objet déterminant un commentaire et une valeur d’approbation et date. Cela peut être un refus commenté par exemple. C’est au système ensuite de considérer ou non la valeur. Dans le cas d’un correctif refusé, le système doit aller chercher la valeur initiale si approuvée. Je vous laisse imaginer le bazar futur.
Conclusion
Nous voilà revenu à notre structure la plus pure et théorique :
S, P, O
Dont O est un V encapsulé et dont il faudra définir l’entité avec soin.
subject UUID not null,
predicate UUID not null,
object VARCHAR(X) not null,
Adieu facilité ! Bonjour complexité et flexibilité…
Il ne me reste plus qu’à réécrire la moulinette de conversion, créer les nouvelles structures d’entités et créer les outils nécessaires pour gérer ça plus facilement, et évidemment revoir le lien front OntologyMyAdmin en profondeur du coup.
Si je fais rowData[‘rue’] on est d’accord que ça nous donnera une erreur d’index non-trouvé ?
Notation en point
Une notation en point c’est, dans notre exemple : 'adresse.rue', c’est à dire la description du chemin pour avoir notre contenu à partir de la racine de l’objet.
Mais si on fait rowData[‘adresse.rue’], ça restera une erreur d’index non-trouvé ! Pourquoi ? Parce que ! Il ne va pas décortiquer tout seul votre clef, ça serait trop facile…
À noter que PrimeFace le traite par défaut quand vous utilisez leur système, mais dès qu’on part en « fait maison », mode dynamique, extension des templates, etc. ben zou ça ne fonctionne plus tout seul et il n’y a pas de service appelable pour vous aider.
Donc on va le faire nous même.
Résoudre la notation en point
Visuellement c’est simple, je veux descendre d’un cran à chaque point, sur base de la clef courante. Donc une récursive à plat en quelque sorte. Sans chipoter voici ma solution :
static solveDotNotation<T>(rowData: any, field: string) : T | undefined {
const keys = field.split('.')
let err = false
let obj = rowData
for (let ki in keys) {
const k = keys[ki]
if (obj[k]) {
// Continue to dig next key
obj = obj[k]
} else {
err = true
break
}
}
return err ? undefined : obj as T
}
On divise field sur le point pour avoir une liste de clefs (keys) puis on parcours la liste. On a une variable obj, tel un pointeur mobile, initialement positionné à la racine de rowData, qui va évoluer à chaque passage de la boucle pour devenir le sous-élément. Si on ne trouve pas une étape on sort le plus vite possible, sinon on continue de descendre dans le terrier du lapin blanc.
En cas d’erreur, ici le choix est fait de renvoyer undefined qui permet, dans mon cas, de pouvoir jouer avec la notation de chainage optionnel (?.) dont voici mon exemple dans le cadre de mon rendu de valeurs ontologiques.
Si on regarde Folk·o·pedia, même si Comitards date de 2006, on pourrait penser que le sujet ne date que d’il y a 7 ans, quand j’ai parlé de Comitards v3. Et là encore, vous me direz que c’est déjà pas mal. Mais que nenni, il y a une histoire plus ancienne qui prend forme aujourd’hui, dont je ne me suis rendu compte qu’il y a peu. Du coup, c’est parti pour un petit partage.
Folkipedia, juillet 2007 avec le FJDB (Fonds Jean-Denys Boussart), sans suite.
Reprise du projet en personnel, juin 2008.
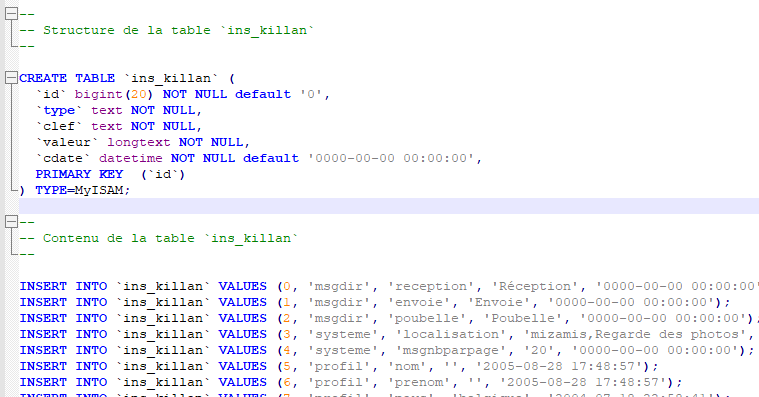
Nous sommes d’accord que Folk·o·pedia repose sur une ontologie, une base de connaissances, structurée en triplet (Sujet, Prédicat, Objet), ça ok, mais saviez vous que tout début 2000, un de mes sites, MiZaMis, utilisait déjà une base de données structurée différemment ? Suivant le principe de la base de registre de Windows, en un peu plus simple, chaque utilisateur avait sa propre table, organisée dans l’équivalent du prédicat – valeur (objet). Bien sur, à l’époque, cela a valu son lot de railleries, mais ce système a montré ses avantages et inconvénients et a pu durer toute la vie du site.
Structure de la table d’un utilisateur et exemple de contenu.
MiZaMis, division de MesDocuments, successeur de LaToile, ~2005-2008.
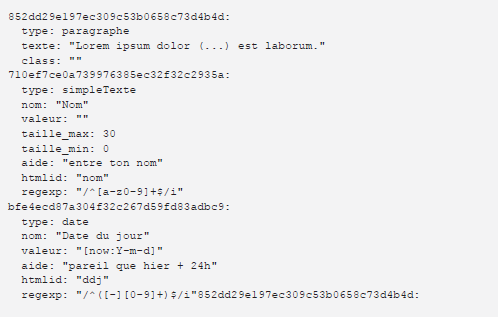
Plus tard, suite à mon second graduat en Techniques Infographiques (2008), j’ai proposé un mémoire sur « Recherche, étude et mise en œuvre d’un générateur de formulaire extensible, configurable et exploitable dans divers contextes« , qui, en résumé, avait pour but de générer des formulaires sur base d’une description, avec contrôles et différentes sorties générées possibles (web, PDF, rtf, Word, …), évidemment c’est la version web avec JQuery qui était le plus poussé, même si générer du PDF en code natif était un beau défi en soi.
Mais, n’est-ce pas également le but des modèles ontologique que renferme Folk·o·pedia ? Une description d’entité dont les prédicats sont eux-mêmes décrit et peuvent indiquer des contrôles ? En effet, le but d’un modèle est de pouvoir proposer un formulaire généré via la description de son modèle ! Évidemment on ne vas pas réutiliser la solution du mémoire ^^ elle est légèrement dépassée, mais l’idée, le concept, lui, reste valable.
Dump YML des données générées par l’éditeur.
Résultat généré sur base des données précédente en XSL et d’un transformateur XSLT.
Le même résultat avec une couche de CSS et de JS.
Dans une autre mesure, il y a eu aussi le projet FGPI (Folk Groups and People Involved vocabulary) en 2015, dont le but était de créer un ensemble de règles descriptives afin d’ajouter au site Comitards.eu une couche metadata suivant certains principes, mais, malheureusement, cela s’est avéré infructueux. Cela étant dit, une ontologie, donne exactement une suite à ce projet, décrire des objets et les liens entre eux, des gens et des groupes folkloriques, ce qu’ils ont fait, porté et vécu.
Et enfin, durant mon mémoire de 2022, dont le sujet, en français, était : « Comprendre les exigences d’utilisation des citoyens concernant les fonctionnalités de visualisation de données libres sur les portails du gouvernement« , on traite de la visualisation de données dont on ignore comment les représenter de manière lisible par le premier venu. Folk·o·pedia aura également ce soucis, l’ontologie ne donne pas ces informations en premier plan, il faut prévoir un tel système, le fournir et le traduire, et c’est génial car c’est encore tout un défi ! On peut partir sur un dictionnaire des prédicats par exemple, d’ailleurs celui-ci est déjà nécessaire en l’état du développement courant.
Vous avez là trois histoires qui se passent sur ~24 ans. Trois bout d’un problème qui se déroule en ce moment même. Je ne l’ai même pas vu venir, mais quelle surprise lors du constat ! D’où ce petit partage pour vous en faire part. 😉
Passer dans les backups et archives, pour vous trouver ces contenus, ravivent de beaux souvenirs. C’est toute une aventure, toute une partie de ma vie, de développeur web et de projets perso. Il y a tant à dire et à montrer pour saisir ce que cela peut représenter à mes yeux :).
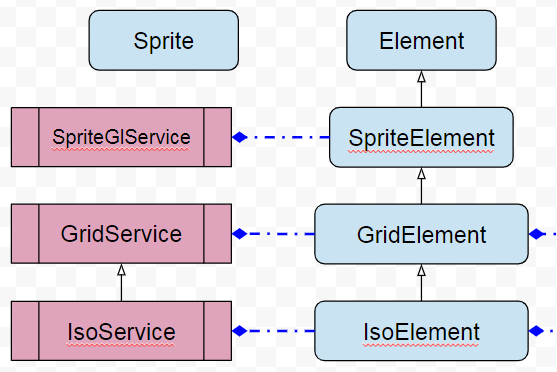
Et en avant première, une partie des coulisses actuelle, l’état sans censure du développement de Folk·o·pedia, son outil de contrôle : l’explorateur d’entités. À l’image d’un autre outils qui m’a aidé toutes ces années : PHPMyAdmin.
Comme annoncé en petit comité tout récemment, j’entreprend de recommencer le projet Folk·o·pedia. Ce sujet n’a de difficulté que de rassembler la connaissance, toute la connaissance folklorique… Et pour ce faire, je souhaite utiliser, me baser sur, ou m’inspirer du principe d’ontologie, de modèle ontologique et de triplet RDF, comme dit en 2019.
Cette année là, un modèle DB avait été conçus, correspondant et faisable, et un système a même été développé, tel un driver pour la suite du développement. Mais malheureusement ça n’aura pas été plus loin. Qu’à cela ne tienne, nous revoilà plus beau, plus malin, plus fort, plus motivé que jamais.
On récapépètte depuis le zébu. Suite à de nouvelles rencontres et d’événements, le projet évolue un chouilla plus avec l’ajout d’objets, même si la notion existait déjà, l’idée est plus aboutie (collection/fonds et métadonnées). De plus on reprend la base même des données, de leur structuration, de leur relation ou fonctionnement. On reprend tout.
Brainstorming SPO, problématiques et performance.
SPO
Tout part de là en fait. Ce fameux triplet, que l’on peut comparer à une base de registre (cf Windows par exemple). Un quelque chose qui a un attribut qui a une valeur (ou plusieurs). Soit le Sujet – Prédicat – Objet. Et il faut savoir que O est soit une valeur finie (un prénom, une date, un nombre, …), soit un lien vers un S.
Donc on peut imaginer qu’une entité me représentant (S) qualifie mon surnom (P) avec la valeur « Killan » (O), mais il y a un second surnom (P) de valeur « Pôlebreak » (O). Donc un ensemble de valeurs pour un même prédicat.
Là où certain se chiffonnent déjà le caberlot, c’est comment savoir quel prédicat est le premier, le principal, etc. Et la réponse est simple : on ne le sait pas.
Historisation
Un autre aspect des données sur un tel site est la vie de la valeur elle-même. Si un document a été révisé il y aura des versions, pourtant il s’agit de la même entité, du même sujet. Si une personne change de prénom, il ne s’agit pas d’ajouter un nouveau prénom mais de remplacer sa valeur avec l’historisation de « l’avant ». Ainsi, si on demande à Folkopedia de nous donner l’état des lieux en 2006, l’on pourra constater que des groupes existent ou ne sont pas encore là, que certains avaient un autre nom, un autre lieu de rassemblement, l’état du comité de gestion (qui et à quel rôle), etc. L’historisation pourra ainsi permettre de voyager dans le temps.
D’un autre côté, l’historisation a également pour but de contrôler les modifications faites par les contributeurs, pour revenir en arrière en cas d’erreur par exemple (principe d’audit et de contrôle par les pairs).
On peut également définir qu’une information n’est pas pertinente à historiser, tel un statut temporaire, la participation à un événement, une demande de contact, …
Visibilité
Un aspect important également avec toutes ces données, est de savoir ce que l’on partage et à qui. Cela peut-être le partage de son email pour être joignable, l’affichage de son deuxième prénom, ou pour un groupe, de donner accès à un document, ce dernier pourrait n’être disponible que pour les membres. Ainsi quelque soit la donnée, celle-ci bénéficie d’une visibilité.
Cette visibilité peut être parmi une liste proposée (publique, privée, membre inscrit, mes amis, les amis de mes amis, …) ou définie manuellement : visible par tel ou tel personne, tel ou tel groupe.
Métadonnées
Suite aux points mentionnés ci avant, de comment gérer les valeurs multiples pour un même prédicat, ou d’historisation, et en ajoutant la notion d’audit et de visibilité, la question du comment est bien légitime.
Une première possibilité en suivant le modèle SPO, est que la valeur (O) est elle-même un (S) contenant la valeur elle-même, ses métadonnées, c’est-à-dire la visibilité et son audit (qui a modifié et quand). Le soucis sera au niveau de la performance, pour chaque valeur (O) il faudra chercher son S correspondant et les prédicats résultants.
Si nous avons 6176 inscrits en ce moment, que l’on imagine une centaine de paramètres à renseigner et que chacun ai été révisé 3 fois, en tenant compte du modèle de métadonnées, nous sommes à 7.4M de lignes encodées (max.), sans ajouter quoique ce soit de spécial. Soit, si je souhaite consulter le profile d’une personne j’aurais un maximum de 100*4 requêtes individuelles (pour chaque O cherche le S et ses valeurs de prédicat). Et ce à chaque consultation. Actuellement, sur Comitards, il s’agit d’un lot de 5-10 requêtes.
Une seconde possibilité est de détourner le modèle S¨PO pour aplatir le besoin fixe (audit, visibilité), et tant qu’on y est, vu qu’on parle de table de données, O est un soucis, il ne peut en une même colonne correspondre à la fois à une valeur et à une clé étrangère vers S, il nous faut donc 2 Onullable. Nous aurions donc quelque chose du style :
S, P, O1, O2/valeur, qui, quand, visibilité
O1 est un lien vers un S potentiel, O2 est la valeur (string) et le reste tel qu’attendu. Donc nous réduisons la complexité de 7.4M à 1.8M en simplifiant le principe d’historisation.
Reste que nous n’avons pas résolu la question de quel surnom est avant l’autre. Métadonnée en plus ? Une colonne ordre dans la solution #2 ?
S, P, SL?, valeur, qui, quand, visibilité, ordre
O1 renommé SL (S link, l’enfant de ce prédicat, ou laisser O, à voir) en optionnel (?).
Multiple façons d’historiser
Si on prend une valeur finie tel qu’un prénom, la solution précédente fonctionne très bien.
On peut également imaginer que la partie historisée se trouve dans une autre table pour les besoins de performances.
Mais quand est-il si on parle d’un document, ayant différents auteurs dans le temps, signataires, contributeurs, versions, etc. ? Imaginez un exemple avec un groupe folkorique quelconque (GFQ) ayant un document :
Notez que « restreint » devrait à son tour être une clef vers un S (type connu ou personnalisé). L’url du document à un ordre à null car non pertinent et une visibilité héritée (à voir, ça reste éditable). La date de publication est un string qui sera interprété par la connaissance du modèle, donc permet la flexibilité.
Maintenant que se passe-t-il si le document change ? On ne peut pas tout simplement changer chaque valeur individuellement, la notion de groupe est importante. Bien que s’il s’agit d’une typo dans le titre cela fonctionne. Faut-il encore qu’il y ai un besoin d’historiser le changement.
Ce qu’il va nous falloir, c’est que pour un même S:GFQ-doc#1, il nous faudra une version de plus. On pourrait encapsuler GFQ-doc#1 dans une coquille permettant de regrouper les versions du même document. Ou établir un lien entre les versions comme une chaine entre document, mais là encore côté performance ce n’est pas idéal.
Une autre solution encore est de considérer l’ajout d’un document en le qualifiant spécifiquement de version antérieur d’un autre. Il faudra faire le tri ceci dit.
Évidemment tout ceci se discute, c’est un point de vue et les contributeurs devront se poser la question et le système les aidera dans leur démarche. Il faudra bien sur confronter d’avantages de cas de figure et amender le principe. Et nous n’avons pas parlé des informations additionnelles que chaque élément peut porter (prédicats).
Pour ma part je pense que l’encapsulation est une idée intéressante au seul moment ou une nouvelle version arrive. Ainsi, de manière polymorphique, un document est son information directe ou indirecte via l’encapsulation. Ce sera au système de gérer.
Modèle et extensions
Nous en parlions plus haut, au niveau des types de données sur base d’un stockage en string. Les utilisateurs ne vont pas « coder » leurs données, c’est une interface qui assistera les utilisateurs en fonction de leur choix et les guidera dans le méandres des possibles.
Pour ce faire, NOUS devons avoir une vue claire de ces possibles, ce que chaque entité peut avoir comme prédicat, autoriser l’ajout de prédicat avec validation collégiale, faire vivre le modèle et ses usages.
Prenons un exemple avec un couvre-chef, il aura un nom. Si nous l’étendons et définissons la penne, celle-ci aura d’avantages de paramètres, tel que la longueur de la visière, la couleur du feutre, son origine, sa date. Mais là encore on peut parler d’un comité de baptême décernant la penne et ayant sa version dudit chapeau, avec son liseret, ses pins de base, le folklore attaché à la cérémonie, etc. Enfin, l’utilisateur du même comité de baptême, déclarera posséder un tel couvre-chef et sa penne aura sa propre vie, respectant ou non les valeurs du comité.
Ainsi par cet exemple on observe le principe d’extension du modèle. Le modèle permet de définir un objet, qui, quand il sera instancié, permettra à l’utilisateur d’avoir des informations à remplir. Évidemment il faut aussi imaginer la variance possible dans le temps, avant on faisait ça, mais aujourd’hui… etc. De même que le modèle peut être à respecter obligatoirement (couleur, longueur), alors que certains paramètres peuvent varier, comme une suggestion, on met le pins ici mais tu l’as mis là car ton parrain fait autrement etc. .
On aura donc besoin d’un système permettant la définition des modèles et ainsi définir le type de prédicat, leur pluralité, leur valeur par défaut, le côté obligatoire. tel un patron de vêtement, une recette de cuisine, vous gardez votre liberté.
Dans l’ensemble d’une entité (S), un prédicat pourra alors nous dire de quel modèle l’entité est issu. Ce qui permettra de construire le formulaire de saisie, d’apporter l’assistance à l’utilisateur, de contrôler la mécanique et fonctionnement, voire même de définir la validation par les pairs.
Autogestion
Vous avez donc compris la taille du possible, la quantité d’informations potentielles et nous n’avons parlé ici que de quelques cas. Seul je ne saurais, ni ne veux, gérer ça, c’est à la communauté et aux contributeurs motivés que cela revient. Donc il faut définir, à l’image de StackOverflow, une mécanisme adéquate. C’est à dire, un moyen de mesurer l’implication ET la justesse de participation d’un utilisateur pour lui donner tel ou tel droit.
Évidemment vos données vous regarde, mais vos apports seront confirmés ou infirmés, un jugement par vos pairs pour donner crédit ou informer d’une erreur. L’idée restant que l’information proposée sur le site doit être de la meilleure qualité qu’il soit (comme Wikipedia).
De plus, vos titres de guindaille seront utilisés pour savoir à qui demander une validation d’accès à un groupe, ainsi il faudra que X personnes valide et ainsi le titre est validé et la personne à alors accès aux données du groupe et peut s’enorgueillir d’en faire partie. Comme pour les tags sur les contributions, certains seront officiels mais les nouvelles propositions feront l’objet de vote.
Ainsi vous pouvez imaginer, qu’au travers d’une structure SPO, tout ceci, et plus encore, seront encodés. Il va de soit qu’une recherche sur la performance et un détournement de modèle quant à son implémentation seront nécessaire.
Suppression et historique
Un soucis se pose quand on parle de suppression dans un contexte historisé. Doit-on réellement supprimer la donnée ou juste rompre l’accès ? Mais si l’entité est liée et à son tour supprimée, comment gérer l’ensemble fantomatique ? Empêcher une suppression peut être une solution, si après un délai et/ou si lié à d’autre.
S, P, SL?, valeur, qui, quand, visibilité, ordre, supprimé, supprimé par qui
On pourrait ajouter alors cette information pour connaître sa disponibilité, mais le plus évident en terme de performance sera de déplacer le contenu dans une table dédiée. Alors, suite à un acte spécifique une liaisons sera établie pour aller les chercher, par exemple restaurer une donnée.
Mise en cache
De but en blanc, l’idée est simple, au lieu de faire des centaines de requêtes sur un sujet à chaque consultation, on stock le résultat en mémoire pour aller le chercher et rendre l’opération plus légère et rapide. Mais, nous avons une notion de visibilité, ce qui nous oblige à en tenir compte et à ne stocker que la partie publique, et peut-être à mettre en cache des segments par visibilité.
Publier le schéma
À l’image de schema.org, il nous faudra également un aplatissement du modèle, à des fins de documentation, de contrôle et d’échange.
Dans cette optique et en nous basant sur les données existante de Comitards, nous pourrons créer des modèles et une moulinette pour migrer l’information, ensuite confronter les cas d’usages et les extensions.
Conclusion
Comme vous le voyez, il ne s’agit pas d’un « yapluka », mais d’une procédure empirique qui se confronte à chaque étape à des questions de « comment » on va gérer telle ou telle situation. Cependant, la direction semble claire, les impératifs sont définit, la notion de performance en cible également.
La prochaine étape sera de modéliser cette base de données et d’y décrire le principe de modèle, ce qui pourra être testé par des cas d’usages.
En comparaison du modèle de DB de 2019, plus éclaté, il reste valide, et c’est peut-être vers quoi on ira une fois que l’on aura les données plus en mains avec cette recherche de performance. Ou c’est via la notion de cache que le salut se fera.
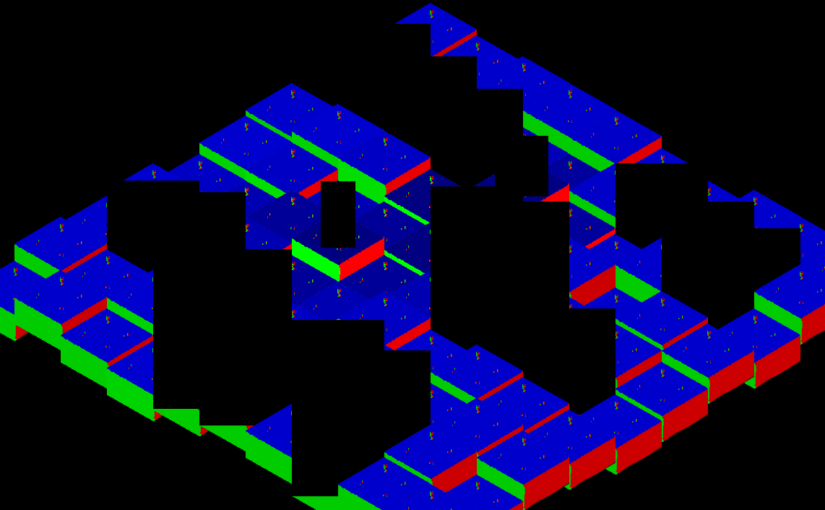
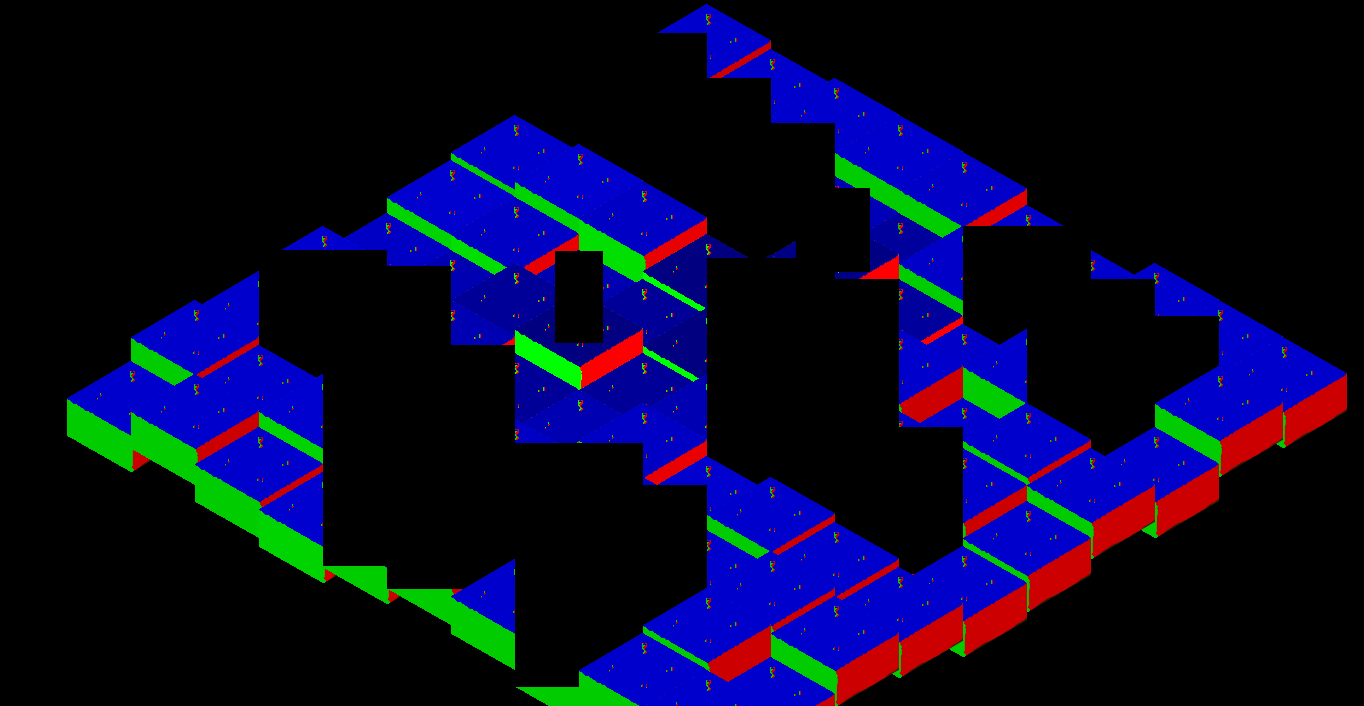
Suite des articles visant à améliorer l’illumination de la scène, après une couleur diffuse correctement éclairée grâce aux normales et aux spéculaires, il restait, invariablement, que l’image entière était éclairée uniformément concernant l’intensité, pour une même direction de normales.
Mise à plat de la scène pour valider le dégradé de l’intensité.
Les calculs et les informations transmises étaient insuffisantes pour calculer la valeur de chaque pixel et, surtout, rien ne nous permet de savoir où le pixel se situe dans l’espace, nous permettant de faire varier son illumination sur base d’une distance altérée par sa position.
Je ne suis pas 3D
N’oubliez pas que ce que vous voyez n’est pas de la 3D, mais une succession d’images plates représentant « un quelque chose » en 3D, et c’est cet enchevêtrement savamment orchestré qui vous dit que l’image est 3D. Tout n’est qu’illusion Mr. Anderson ! Et votre cerveau vous trompe, et c’est le but !
Je l’ai déjà dit dans les précédents articles, mais c’est là tout le problème, comment donner une information 3D à une image plate ? Certes nous avons les normales pour nous donner la direction, mais qu’en est-il de la position ? Comment puis-je savoir que le haut de mon bloc est une surface au Z équivalant, variant sur X et Y ?
Explication du process depuis le début.
Reprenons depuis le Zébut
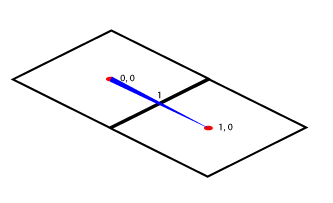
Un Tile est l’image représentant une zone, une unité de notre grille. Celle-ci a ses coordonnées X et Y. La distance entre leur position sera de 1 (1x, 1y ou 1x1y).
L’éclairage d’un Tile est soumis à la propagation de la lumière dans le subset de la map courante (cela nous rappelle de vieux souvenir [2018 !]). La propagation reste importante pour savoir quel Tile est impliqué dans l’éclairage (optimisation).
Un subset reprend une partie des éléments du monde concernés par le rendu à l’écran.
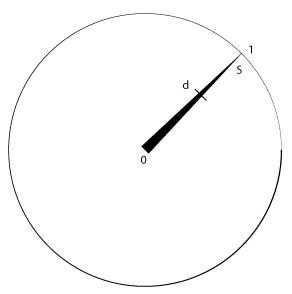
On parlera donc de la distance (parcourue ici) entre le Tile que l’on veut éclairer par rapport à la source lumineuse et sa force.
Une lumière peut donc éclairer sur une distance (d) un objet proportionnellement à sa force (S) à cette distance et selon l’intensité (i) de cette lumière. Nous obtenons alors le facteur (f) d’éclairage du pixel (rgb aux coordonnées uv).
f = (1 - (d * (1 / S))) * i
On obtient une valeur (float) allant de 0 à 1, qui sera notre facteur d’éclairage du Tile.
Ça c’était avant
Ce qu’il nous manquait jusque là c’est d’avoir toutes les coordonnées au niveau du shader pour effectuer ce calcul de distance au niveau du pixel.
On calculera ainsi notre distance autrement, c’est-a-dire sur base des coordonnées du Tile (t) et de la lumière (l), sans oublie l’intensité (i).
d = √((l.x - t.x)² + (l.y - t.y)²) * i
Donc on propage, on définit pour chaque Tile concernés les lumières impliquées, on ajoute les informations manquantes jusqu’alors et … ? Ben jusque là rien de nouveau sauf une distance plus correspondante à l’origine mais pas par rapport aux obstacles rencontrés entre la source et l’élément éclairé, car ça, je suis sur que vous les aviez oubliés.
On ne traverse pas un mur, la lumière « contourne » par rebond etc. Donc la propagation reste la bonne manière mais ne donnera pas le bon résultat en isométrique, et j’espère que vous comprenez pourquoi avec toute cette suite d’articles ahah. En bref, on a pas la possibilité de savoir comment la lumière est arrivée à chaque pixel, il faudrait calculer pour chaque objet un pixel de rebond (surement sa normale), balayer ainsi dans tous les sens et à chaque contact : éclairer ce pixel et modifier le rayon pour le faire repartir (couleur, angle, puissance, …), bref on réinventerai un rendu par projection de rayons en 2D sur base d’information 3D stockée dans les textures. Non !
Spatiale 3D dans de la 2D
Ce qu’il nous manque à cette étape est le moyen de faire évoluer notre formule de calcul de la distance pour inclure la position du pixel rendu de notre texture.
Nous avions vu plus haut que le Tile se définit par une position X et Y, ici en sont centre, sur la partie supérieur pour représenter le sol. Nous ne parlerons pas de Z ici mais l’idée sera la même une fois que j’aurais réussi à ramener l’information jusqu’au shader.
Si un Tile est à une distance de 1 de ses voisins alors il a à ses extrémités un delta variable de [-0.5, 0.5] en X et en Y. Z étant, lui, soumis à un facteur d’élévation définit par la scène, ici de 8 pixels, et donc aura une idée différente de sa distance, du moins c’est ainsi que l’élévation avait été définie au tout début.
Nous avions jusque là 3 textures : la diffuse (l’image elle-même), la normale (direction d’éclairage) et le spéculaire (carte de où appliquer le spéculaire). Et bien nous allons en ajouter une nouvelle.
Suivant la même idée que pour la texture de normales, nous réutiliserons notre définition RGB de nos repères : X en rouge, Y en vert et Z en bleu. Pour chaque pixel de l’image nous définirons ainsi sa position relative par une valeur RGB. Ne pas oublier que le centre ne sera pas 0, car nous avons besoin des deltas négatif, ainsi nous commencerons au centre à 128,128,128.
Un programme, un plugin, ou une théorie pour le faire de manière automatique n’existant pas, on va devoir y mettre de l’huile de coude.
Ainsi comme vous pouvez le voir, si on veut s’aider, nous pourrons compter sur les gradient, un bon dégradé bien réfléchi qui sera combiné à une couche supplémentaire. Nous commencerons par le XY et on surcouchera par le Z. Un total de 2h nécessaire avant d’arriver au résultat que voici.
Notre formule de distance peut donc être complétée par cette nouvelle information (pp).
d = √((l.x - (t.x + pp.x))² + (l.y - (t.y + pp.y))²) * i
Ce qui nous donnera sans plus attendre ce premier résultat :
Wow que se passe-t-il ? On a notre dégradé * fête * cependant nous avons un drôle d’aspect sur certain Tile. Notre algo utilise la force (S) pour se propager, mais comme vous l’avez vu, la propagation est plus courte que le segment calculable en ligne droite donc nous arrivons trop court, nous n’avons pas assez s’électionné de Tiles pour notre impact. L’idée serait surement de refaire un calcul sur base de la distance au lieu de calculer le nombre de saut, mais pour le workaround j’ai ajouté +2 à la force (S).
On en profite pour restaurer le calcul du spéculaire maintenant que nous avons de vraies informations et ce foutu éclair blanc au coffre s’en va !
Il y a bien évidemment des effets de bords, comme le fait que la distance parcourue n’étant plus impliquée, si vous fermez la porte, le Tile de l’autre côté sera éclairé comme si vous étiez à côté au lieu d’un faible éclairage (la lumière fait le tour du mur). Les tables clignotent et là je ne sais pas encore pourquoi. C’est plus joli mais moins cohérent. On en revient à l’idée des rebonds, du vecteur qui doit bouger selon l’idée mais rendre chaque Tile cohérent entre eux, là je ne vois pas comment.
J’ai quand même regardé comment ajouter la distance à la formule mais le résultat empirique n’est pas terrible.
Ajouter la distance assombrit la scène
Et en fait si on déplace la lumière selon la distance parcourue dans la même direction, on éloigne alors virtuellement notre Tile voisin. Et ainsi le résultat tiens compte de la distance. Ceci dit l’éclairage en a pris un coup, il y a surement quelque chose à faire avec ça.
lightPos += lightDirection * lights[i].distance;
Pour bien faire il faudra savoir si la distance correspond à un voisin, et ainsi différencier si notre voisin a une distance de 4 ou de 1 et appliquer l’éloignement que dans ce cas. Reste à trouver comment faire.
Et ensuite ?
Comme toujours, quelle est l’étape suivante et comment adresser les nouveaux problèmes, ou ceux mis de côté ? Plus j’avance dans TARS et plus les limites, personnelles et techniques se montrent. Il est grisant de se dire que j’ai relevé un défi qui, selon Google, n’a pas été adressé ou n’est actuellement plus référencé. Il faut aussi se rendre compte de l’effort considérable que cela demanderait si l’on voulait faire un jeu entier ainsi. Et là encore nous n’avons exploré que la lumière (par rapport à l’existant réalisé).
C’est le cœur serré que je me dis que j’ai clôturé cette étape, et qu’il faut, car le temps n’est pas infini, et que je n’ai pas que ce projet à faire, passer à autre chose… Quand je dis « passer à autre chose« , ce n’est certainement pas abandonner Nahyan, certes non ! Mais explorer (enfin) une autre piste que celle de tout faire moi-même, même si je n’ai pas fort le choix. Je ne vais pas en dire plus pour le moment, j’ai déjà commencé à explorer d’autres possibilités et vous raconterais le moment venu.
Cela fait 7 ans que TARS existe, avec une belle pause au milieu, et 2-3 belles phases de développement, comme le passage au WebGL pour adresser les performances sur l’éclairage première version, ou encore la refonte des classes communes pour mieux gérer les données et factoriser le code générique. Et enfin ici, le nouveau système d’éclairage, mais in fine rien de plus, nous n’avons toujours pas vu « Le temple du Prisme« , un HéroQuest ou un Liebesstein.
Une fois que l’on a calculé la valeur de notre pixel, on a la valeur diffuse, ce qui sera la couleur affichée. Sur base des données que l’on a déjà, comme la lumière (position, vecteur), la normale de notre pixel et l’atténuation (facteur de notre lumière), alors il nous suffit d’une petite formule.
Le résultat est blanc ! Sans dégradé ni distinguo, juste blanc ! Là commence une bataille en heures sur des variantes de la formule ou des valeurs des vecteurs. Je vous épargne, c’était « impossible », dans le sens où encore une fois, notre contexte n’est pas le contexte classique 3D et que mes notions de super matheux sont fictives.
Ce blanc est dû à un vecteur, celui du point de vue, et selon ce que l’on met, c’est tout noir ou tout blanc, et comme j’ai chipoté longtemps sans versionner les résultats, je ne peux que vous le raconter. Ensuite j’ai recomposé la couleur diffuse et isolé le spéculaire. Notre ennemi c’est Z, il est imposé à 1 et nous ne gérons pas la hauteur relative actuellement, donc tout est à 1 mais du coup seule la face de « sol » (les normales 0,0,1 soit bleues) sont violemment surchargées.
Démonstration de l’effet spéculaire incorrect pour les normales verticales 0,0,1/bleue
Comme pour la couleur diffuse il nous faudra manipuler le concept. J’en ai été à lire au sujet des produits scalaire et normalisation de vecteur et refaire les calculs à la main, ce qui a aidé, un peu quand même. Ce que j’ai obtenu est un nombre toujours en dessous de 1 (et > 0) ce qui fait qu’élever un 0,x à la puissance 32, le réduira toujours plus (0,0…00x).
La solution, remultiplier ce résultat par 255 pour le renvoyer dans l’espace de valeurs RGB. C’est empirique, mais le résultat donne quelque chose d’intéressant, donc pour une fois qu’on approche d’un truc passable…
Spéculaire sur le coffre, sur sa partie « métallique »
J’en ai profité pour faire quelques textures de normales, ce qui prends, à la main et par pixel, un temps fou. Et vu qu’on fait des modifications de shader et du système de rendu, pourquoi ne pas faire un truc qui n’était pas dans la liste et ajouter une texture de spéculaire, c’est-à-dire une image représentant les zones où appliquer l’effet spéculaire à notre image. Par exemple sur le coffre, ne prendre que les parties métallique.
Ainsi j’ai créé cette image, en utilisant la couche rouge qui peut varier de 0 à 255, ce qui se ramène à une valeur [0,1] permettant de multiplier le résultat spéculaire calculé, tel un facteur spécifique au pixel.
Ainsi, en une seule texture additionnelle et en utilisant les couches RGB de l’image, ainsi que l’alpha (transparence), nous pouvons stocker jusqu’à 4 valeurs permettant d’ajouter des modificateurs visuels à notre texture de base, tel que l’information de hauteur qui nous manque, le spéculaire dont on a parlé, peut-être une information d’ombrage, plutôt que de l’avoir dans l’image rendue, telle qu’actuellement. C’est à voir et investiguer mais ça reste intéressant.
Évidemment charger une énième texture méritait une factorisation côté sprite. On ajoute un type de texture (diffuse, normale, speculaire) en enum et on rend tout le monde meilleur. C’est encore fort « recherche et développement », pas très fini et très améliorable, tout est discutable, mais le résultat apparait 🙂 et ça, c’est bien !
Dernière amélioration, qui se voit sur les murs, ceux en position Est ou Sud, c’est à dire ceux que l’on voit mais qui n’appartiennent pas à notre bloc courant, mais également ceux en Nord et Ouest, mais cette fois sur le bloc courant, ces 4 cas, ne recevaient pas la lumière adéquatement.
Dans le cas du mur à gauche de la porte au début de la vidéo (donc un mur Est, sur le bloc x:1,y:3) on marche à côté sur x:2,y(2,3,4). Le mur était noir car la source de lumière partait de x:2,y3 (par exemple si on est à droite du mur avant la porte), le chemin de la lumière passait à x2:y4, x1:y:4, x1:y:3 et comme c’est un cas Est (ou Sud), ceux-ci ne prennent pas la lumière car « ils tournent le dos » à la case. Sauf que si je suis à côté du mur, d’une case adjacente, je m’attends à ce qu’il reçoive la lumière.
Dans le cas du mur Nord ou Ouest (le mur rouge face au coffre par exemple), vers la fin de la vidéo, coffre fermé, le squelette marche devant, si nous sommes dessus, le mur est noir, du fait que l’origine de la lumière et le mur sont sur la même position et annulent par conséquent leurs vecteurs.
La solution a été de déplacer virtuellement la coordonnée de la lumière par rapport à la zone du bloc occupée (N, S, E, O), ainsi l’effet est correcte.
On est loin d’avoir fini, il reste des textures de normales à faire (et c’est looong), des affinages sur le shader (encore et toujours), et sinon le reste de la liste :
Ajouter le tri des lumières, sur l’intensité j’imagine dans un premier temps, et réfléchir au cumul/fusion ensuite,
L’axe Z, les hauteurs et peut être les occlusions (on peut rêver),
L’éclairage global de la scène (facultatif), c’est déjà elle qui pilote, donc ça devrait être facile.
Suite à toute cette énergie de réactivation sur TARS, j’en suis venu à me remettre à rêver et à me demander quels résultats j’aimerai présenter à d’éventuels joueurs (un jour).
Nous sommes dans un univers 2D à l’apparence 3D, donc nous appliquons des principes, des formules, propre à l’univers 2D pour afficher un monde qui se veut 3D. Cependant, et j’en ai déjà parlé précédemment, la lumière est un calvaire. Alors vous me direz que les autres s’en sortent plutôt bien, certes, mais ils « trichent intelligemment », avec un décors en un morceau et plat sur lequel on peut ajouter les éléments qui vont vous immerger (ombre plate rotative sur sol par exemple ou effet de lumière par un calque d’obscurité); alors que TARS se veut proposer une gestion de la hauteur [Z] ce qui est super casse-couille on ne va pas se mentir, mais permet de donner beaucoup plus cette impression de « vraie » 3D.
J’ai donc repensé à mon éclairage et à notre élément de bloc :
Le bloc test
L’image, et c’est important, est rendue uniformément sur base de données calculées au changement dans la scène (déplacement, mouvement de caméra), c’est à dire que virtuellement on va tenir compte d’éléments éclairant, calculer qui est soumis à ces lumières et appliquer un modificateur de couleur, in fine. S’en suit une application par le shader qui va prendre cette information et la mélanger à la couleur d’origine de chaque pixel, en gros.
MAIS, les flancs de ce bloc, ou les côtés des arbres, coffre, murs ou tables, sont éclairés de la même façon que le sol ou le reste de l’image, on n’augmente pas le relief du bloc lui-même mais plutôt sur une vue d’ensemble de la scène.
L’idée est donc de renforcer la notion 3D de l’élément, son volume que l’on devrait percevoir. On le « lit » grâce aux lignes de l’image, notre cerveau comprend la forme, son relief, mais son éclairage est plat. Ce problème existe depuis de nombreuses années dans l’univers des jeux 3D, rappelez vous ces murs plats à la texture de mur, lisse alors que l’image nous indique un relief. Je ne vais pas vous révéler un grand scoop, mais depuis on utilise différentes techniques, comme le displacement mapping ou, dans notre cas, le normal mapping.
Le but du normal mapping est de pouvoir prendre une surface texturée et de vous donner l’impression, par son éclairage, qu’il est en relief. Une application serait de prendre un modèle très détaillé et donc très couteux au rendu, de faire une texture détaillée, de simplifier le maillage drastiquement, et d’appliquer cette texture détaillée, là on a un modèle simple avec un beau niveau de détails, une belle économie de calcul, mais la lumière ? Comment ce modèle va-t-il être éclairé ? Grâce à la texture détaillée, elle donnera, après traitement, des informations permettant de savoir dans quelle direction chaque pixel est orienté, la normal map; et au moment du rendu, grâce à un shader, la texture détaillée sera éclairée pixel par pixel correctement, le résultat sera bluffant et rapide. Pour les détails, internet regorge de ressources à ce sujet, ici je synthétise :).
Ce que la théorie nous apprends sur les textures de normales et leurs directions (source OpenGameArt)
La texture de normales de notre bloc
Alors moquez vous, c’est fait avec paint car je n’avais rien d’autre sous la main. Et, pour accélérer l’article et son mystère, vous l’aurez vite remarqué mais ça n’a pas l’air de coller à la théorie (on y reviendra, moment de solitude). En lisant la théorie vous lirez que l’on va utiliser les valeurs RGB de chaque pixel pour donner une direction spatiale au pixel (son vecteur, sa normale), RGB devient XYZ (la suite plus tard), donc j’ai transposé la théorie à mon plan isométrique, et avec mon cube la couleur est sans appel, on a un X pur (255,0,0 = rouge) sur le franc droite, un Y pur (0,255,0 = vert) sur le flanc gauche et un Z bien plat au dessus (0,0,255 = bleu).
On modifie le code pour charger, stocker, référencer et définir notre texture de normales et l’envoyer jusqu’à notre shader existant (ça a déjà pris pas mal de boulot).
Premier essai de contrôle pour voir que la texture est bien là
Mouai, il y a une couille dans le pâté. Les objets « non cube de sol » ont la texture aussi. Vous le verrez à la déformation (les arbres). Sinon on voit que le coffre éclaire toujours en rouge (la petite part de tarte rouge et bleue).
Premier essai en ne tenant pas compte des objets qui n’ont pas de texture de normales.
Maintenant que j’ai les bonnes infos (si seulement) je me dit qu’on peut tenter d’appliquer ce que les grands esprits ont fait avant moi, je vous épargne le code et les modifs TARS.
Premier essai de rendu avec normales
On a donc une scène qui ne veut pas prendre les flancs des blocs en compte et cumule trop de lumière avec un assombrissement au niveau du coffre qui est étrange. Le reste est noir, non impacté par une lumière, et là on se dit qu’une lumière globale serait intéressant, mais ça ne l’est que dans l’esprit de la scène (un extérieur boisé), donc à laisser à la discrétion de chaque scène.
On isole tout et on essaye de comprendre ce que l’on a
Je retire tout, je laisse le sol et notre héro porteur de la lumière (voq) et on va tenter de manipuler notre shader pour vérifier, car on ne peut pas débugger un shader « pas à pas », malheureusement.
On remet le coffre pour valider la seconde source de lumière
On discrimine les affectés pour afficher et contrôler la portée des effets
Bon, qu’est-ce qu’on essaye de faire ? On a une liste de lumières qui affecte l’éclairage et la couleur de chaque pixel d’un élément rendu (ici notre bloc), ce qui se calcul avec la valeur normalisée de notre pixel de la texture de normales (à la même position bien sur) que l’on veut comparer au vecteur de la source lumineuse (une à une) pour en déduire l’impacte d’éclairage (un peu, beaucoup, passionnément, …) et ainsi composer, lumière après lumière, la couleur finale de notre pixel venant de la texture. Ce sont les normales de la texture de normales qui donneront l’effet de variation d’intensité des flancs.
La théorie 3D nous parle de matrice de l’univers, mais nous sommes à plat, et donc on ne peut pas appliquer simplement la formule, on doit la tordre, et je ne suis pas matheux, alors ça se complique. De plus, comme dit plus haut, on a fait une erreur, notre image représente une dimension isométrique et la texture de normal a été faite en ce sens, après tout, comparer des vecteurs ça devrait rester équivalent. Encore un point qui ne nous aide pas avec les formules (voir les sources en fin d’articles pour les curieux).
Différents tests et autant d’échecs. J’avoue, là, j’ai fait une pause de 2 jours après 2 jours dessus. Il me manque un truc mais je ne sais pas quoi. Les couleurs sont violentes ou noires, les flancs ne se colorient pas comme attendu, tout disparait (noir), … Foutu vecteurs.
Troisième essai où l’impacte des flancs se montre
On arrive enfin à quelque chose, mais en contre partie, les objets sans texture de normales sont noirs, peu grave, ça viendra plus tard. Le truc ? Tout reprendre et reconstruire le shader avec les 2 principes communs aux articles parcouru : normalisation et produit scalaire.
Pour faire simple, on définit notre pixel de texture et notre pixel de la texture de normales (texel), on a 2 vec3 (rgb), on normalise le texel, on crée un vec3 à 0.0 pour notre couleur résultante (donc noir par défaut, cf. la mise en noir cité plus haut), on boucle sur la liste des lumières et pour chaque on calcule un facteur lumière qui est le résultat du produit scalaire de notre normale et de la position de la lumière par rapport au bloc, ce qui nous donne un coefficient que l’on va utiliser pour multiplier le pixel de la texture, la couleur de la lumière, la force de notre lumière avec ce coefficient, ceci ajouté à notre vec3 couleur. Au final on indique d’utiliser ce résultat sans oublier l’alpha de la texture d’origine.
Comme vous le voyez ça clignote, c’est dû à l’ancienne manière de faire le passage de la lumière d’un tile vers un autre, en passant un delta de 0 à 50% jusqu’à changer de tile, pour se faire on ajoute un seconde lumière pour la différence du delta sur l’autre tile. Ce qui nous amène à constater ce qu’il nous manque encore :
Transformer le delta et l’envoyer au shader pour le gérer là, sinon nous en revenons au changement sec d’éclairage de tile pendant le déplacement, au lieu du côté doux que l’on a développé.
Gérer la hauteur de l’éclairage (Z), mais cela va demander à TARS de passer l’information et d’en tenir compte.
J’ai pensé à l’occlusion et au barrage mais ça me parait compliqué à ce stade.
Ajouter un éclairage global ? Ça peut-être intéressant pour sa différence.
Créer les textures de normales pour les autres objets.
Un des articles parle de la lumière spéculaire et je me demande si nous saurions l’ajouter nous aussi.
Voilà donc la semaine de travail sur les normales, avec, heureusement, un résultat encourageant.
FPDF pour moi reste une référence en terme de librairie bas niveau pour créer vos PDF et j’avais fait mon premier système (et d’autres) de facturation avec; et récemment j’ai découvert un successeur plutôt digne côté front : jsPDF.
Quand on parle de bas niveau c’est d’une part car vous avez la main et devez gérer quasi absolument tout vous-même (coordonnées x,y, occupation de l’espace, vos marges, vos retours à la ligne ou saut de page, …) et de l’autre car la librairie va écrire pour vous le code PDF natif (https://pdfa.org/).
jsPDF n’est pas le nouveau messie dépourvu d’erreur, elle en a son lot, parfois même agaçante vous demandant pas mal d’effort ou d’ingéniosité, mais dans le paysage actuel c’est une base plus que correcte. Attention toute fois de ne pas confondre convertisseur de contenu HTML vers PDF et jsPDF qui vous permet de le créer/composer. Les convertisseurs, au super rendu et 3 lignes de code, utilisent la librairie canvas pour faire une forme de capture d’écran et injecter l’image dans un PDF, joli mais sans accessibilité (sélection du texte, c’est une image) ni modifications (pour la même raison que c’est une image).
Bien que la documentation existe, elle reste sommaire et j’ai moulte fois dû, et au final préféré, une lecture directe du code disponible sur github. Il est certain que si vous entrez dans des réflexions de faisabilité, de type de paramètre ou de compréhension, vous descendiez à ce niveau régulièrement. Notamment un éternel sujet complexe : la taille d’un texte.
But de l’article
Cet article à pour but de dégrossir des points d’attention pour ceux qui veulent se lancer dans l’écriture de PDF. Il n’est pas aisé sans notion infographique minimum de concevoir un document qui aura du sens et respectera quelques notions « élémentaires ». J’entend par là la notion de marges, de taille de texte, de police d’écriture et de son style, ou encore d’interlignage, d’alignement, d’indentation et j’en passe.
Les points
Dans ce monde vous aurez accès à divers unité, mais je trouve qu’il est plus aisé de rester natif et d’utiliser les points, tel qu’un millimètre = 2.83465 points (se référer aux pouces du coup). Ou encore, une A4, aura pour largeur 595 pts et une hauteur de 842 pts. Et pour compléter ce sujet, un pixel aura un rapport de 0.75 pour 1 pts (pensez à l’unité de vos images par exemple).
Les couleurs
Elles peuvent être gérée par code hexadécimal (#333333) ou par RGB/RGBA (channel(s) en jsPDF), ainsi nous utiliserons une structure, qui prendra place en ch1, ch2, ch3 et ch4 tel que :
Afin de mieux gérer notre contexte, je vous suggère de créer une classe qui vous permettra de conserver votre position x, y, vos marges, les dimensions calculées d’espace disponible, puis la fonte choisie, sa taille, son interlignage, etc.
import { jsPDF } from "jspdf";
export interface Margins {
left: number
right: number
top: number
bottom: number
}
export const DIM_A4_POINTS = { width: 595, height: 842 }
export const DIM_MM_POINTS = 2.83465
export const DIM_PX_POINTS = 0.75 // 1.333
export class KPdf {
doc: jsPDF
margins!: Margins // Defined in constructor
x: number
y: number
pageWidth!: number // Updated by constructor call
pageHeight!: number // Updated by constructor call
fontSize: number = 10
lineHeight: number = 12
constructor() {
this.doc = new jsPDF("p", "pt", "a4")
this.setMargins(20 * DIM_MM_POINTS)
this.x = this.margins.left
this.y = this.margins.top
}
setMargins(margins: number): KPdf;
setMargins(left: number, right?: number, top?: number, bottom?: number): KPdf {
this.margins = right ? { left, right, top, bottom } as Margins
: { left: left, right: left, top: left, bottom: left } as Margins
this.updatePageDims()
return this
}
updatePageDims(): void {
// A4 forced format on portait orientation
this.pageWidth = DIM_A4_POINTS.width - this.margins.left - this.margins.right
this.pageHeight = DIM_A4_POINTS.height - this.margins.top - this.margins.bottom
}
...
Cadeau, je vous ai résumé ici quelques éléments de base, voyons ça ensemble.
Marges
Les marges, donc l’espace réservé depuis chaque bord de votre feuille, seront quasi indispensable dans vos calculs et positionnements, l’objet va nous aider à nous y retrouver. L’interface est claire assez, il vous manquera un getMargins() pour l’usage mais je vous laisse l’ajouter ;).
J’ai utilisé ici un double setterpermettant de setter les 4 bords d’un coup, égaux entre eux, comme dans le constructeur ou de pouvoir appeler sa version individuelle. Un énième alternative serait le passage d’un objet typé Margins, amusez vous, c’est selon vos besoins :).
Noter le type de retour (KPdf), pour ainsi pouvoir chaîner vos appels, quel confort quand même ;).
Constructeur
Le but est de créer notre base jsPDF correctement paramétré selon nos habitudes, besoins et choix technique, dans notre cas des pages en portait (« p »), en utilisant l’unité point (« pt ») et de dimension A4 (« a4 »).
Une fois établi, on met des marges par défaut, typiquement comme tous les traitement de textes qui vous proposent un modèle clef en main par défaut que personne ne retouche, sauf des gars comme nous ^^. C’est là qu’une première magie peut s’opérer, si on a des marges, connait alors notre origine (x,y) et l’espace disponible pour y mettre notre contenu.
J’ai également mis une taille de caractère (fontSize) à 10pt et son interlignage (lineHeight) à 12 en prenant l’échelle 1.2.
Et voilà vous êtes parti, bon amusement !
… si seulement ^^
Agrémenter KPdf
Vous avez une base, que vous ferez évoluer selon vos besoins au cas par cas de vos projets, perso je me suis mis des getter/setter pour x, y, xy, fontSize, lineHeight, mais aussi pour définir une en-tête et un pied de page. Là, je vous parlerai de delegate ou callback, un moyen de définir de manière extérieur un contenu à une méthode interne actuellement non définie.
export type HeaderPrototype = (pdf: jsPDF) => void
export class KPdf {
...
headerFct?: HeaderPrototype
footerFct?: HeaderPrototype
setHeaderFct(fct: HeaderPrototype): KPdf {
this.headerFct = fct
return this
}
setFooterFct(fct: HeaderPrototype): KPdf {
this.footerFct = fct
return this
}
addHeader(): KPdf {
if (this.headerFct) {
this.headerFct(this.doc)
}
return this
}
addFooter(): KPdf {
if (this.footerFct) {
this.footerFct(this.doc)
}
return this
}
newPage(): KPdf {
this.doc.addPage()
this.addHeader().addFooter()
this.setXY(
this.margins.left,
this.margins.top
)
return this
}
...
Exemple ici avec la méthode newPage qui ajoutera une page au document final et appellera de toutes façons l’ajout d’une en-tête et pied de page, évidemment si définit par l’utilisateur (détecté en interne de méthode). Bonus ici, reset des x et y au saut de page.
En démarrage par contre, car jsPDF crée une page par défaut, il faut les ajouter à la main, tel que :
const kpdf = new KPdf()
// Setters, margins
...
// Manage first page
kpdf.addHeader().addFooter()
Gestion du texte
J’ai eu 2 cas différent en terme de traitement de contenu, un premier avec une source Tiptap, dont je parlerai surement dans un autre article sous forme de retour d’expérience, et un autre avec une gestion de cellule de tableau maison, dont je vais un peu vous faire quelques retours.
On utilisera la fonction textpour écrire du texte dans notre PDF et petit conseil en passant, mettez l’option baseline à « top » mieux gérer votre x/y. Autre chose à savoir, si vous voulez aligner à droite, votre x est le x en fin de ligne/bloc et il faut également mettre l’option align à « right » du coup.
Retour à la ligne
Ce n’est pas aussi bête qu’il n’y parait, même si la fonction text à l’air complète elle manque clairement de documentation, cas d’usages clairs.
C’est quoi un retour à la ligne, c’est d’arriver au bout de notre espace disponible, de forcer un retour chariot au début de notre ligne (x), quel qu’il soit (pas forcément la marge gauche, surtout si indentation), de passer une hauteur de ligne (augmenter notre y) et de continuer d’écrire notre contenu (on parle ici de rendu du texte que l’on veut injecter dans le PDF).
La question est comment on sait ça ? Posez-vous juste la question. Vous avez une somme de caractères (un paragraphe par exemple), j’imagine que vous connaissez la taille du texte et que vous êtes prêt de ce côté kpdf.doc.setFontSize(12) par exemple. Sans faire du suspens inutile, je vous conseille splitTextToSize qui va vous rendre un tableau de string coupé à distance maximum (votre pageWidth par exemple ou la largeur d’une cellule). Si vous injectez le résultat directement dans text, pensez à préciser l’option lineHeightFactor (1.2 dans notre cas), personnellement, pour d’autres raisons, j’ai géré à la main l’écriture de chaque ligne, donc j’utilise ma variable lineHeight et je positionne mon x et y également à la main.
Gras/italique
Si vous avez du gras ou de l’italique dans votre texte d’origine vous risquez d’avoir des surprises, déjà la fonction text ne gère qu’une configuration à la fois, c’est à dire que si j’ai une phrase telle que : « mon contenu est composé », j’aurais virtuellement 3 configurations :
« mon » : texte normal
« contenu » : texte gras
« est composé »: texte normal
Attention, ici on parle au sein d’une seule ligne, c’est encore plus fun (compliqué) quand on gère ça en multilignes. Qu’importe votre façon de gérer cette structure de bloc, vous allez devoir boucler sur cette liste, calculer pour chaque la longueur du bloc de texte et ainsi gérer un x progressive par appel de la méthode text. Grossièrement on aurait (on suppose la gestion des espaces entre blocs) :
this.doc.text("mon ", x, y, { baseline: "top" })
// Change style
this.doc.text("contenu ", x + w1, y, { baseline: "top" })
// Change style again
this.doc.text("est composé", x + w1 + w2, y, { baseline: "top" })
On voit facilement l’intérêt de la boucle pour faire progresser x successivement. Cela suppose que votre gestion de bloc retiendra la largeur de celui-ci une fois calculé.
Multiligne
Si on pousse le bouchon où le dernier bloc est trop large par rapport à votre pageWidth/taille de bloc, alors on peut subdiviser en coupant au mot (textPart.split(‘ ‘)) et tester chaque mot un à un, puis forcer le retour à la ligne et reprendre. Vous aurez un algo maison combinant par exemple getStringUnitWidth ou encore splitTextToSize et votre gestion d’effets.
Dans mon cas Tiptap, ayant dû gérer pareil cas, j’ai fortement utilisé getStringUnitWidth, mais qui a sa limite concernant le fait qu’il ne gère pas le gras/italique, il faut appliquer un facteur empirique (~1.08) ou trouver le descriptif par caractère de la fonte utilisée pour les cas : gras, italique, gras+italique; et réécrire le calcul de largeur d’un texte donné. C’était le même soucis avec FPDF, tout dépend des métas de la fonte utilisée, mais là j’admet que ça dépasse mon niveau sur le sujet.
Saut de page
Comme on l’a vu pour le retour à la ligne, c’est pareil en y, si on voit que ce que l’on va écrire va déborder au delà de la marge inférieure alors il nous faut créer une nouvelle page tel que vu en exemple de code plus haut, avec en-tête et pied de page, repositionner x et y et reprendre notre rendu. Plus simple quand on a compris le retour à la ligne.
Il faudra cependant prêter attention à l’indentation. Par exemple, si vous êtes en train d’écrire les éléments d’une liste, vous aurez l’indentation pour dessiner la bulle par exemple, et si vous gérer plusieurs niveaux d’imbrication alors là encore plus (pensez récursivité). Hors des listes, l’indentation existe telle que dans un traitement de ligne quand vous utilisez la tabulation ou une règle de positionnement de début de paragraphe.
Tableaux
Un tableau c’est quoi ? Au delà d’une structure à 2 dimensions, ce sont des espaces délimités en largeur (mais pas que, parfois) dans lesquels doit prendre place un contenu. Sans parler des considérations esthétique, de formes et de couleurs, nos cellules sont des blocs, successifs pour lesquels notre logique de retour à la ligne revient.
L’astuce esthétique et logique (x,y) nous oblige à garder en mémoire quelle cellule aura pris le plus de hauteur parmi la ligne courante, sinon, par exemple, si vous faites un zèbre (couleur de fond de ligne) comment l’appliquer sans créer des trous dans certaines cellule ? Vous êtes obligé de faire une passe de calcul (découpe des textes, retours à la lignes, gestion des blocs, …), puis une seconde passe de rendu en profitant des données calculées (couleur de fond, positionnement x,y).
Répétition de l’en-tête
Quand on parle de tableau on oublie souvent de définir ce qu’il se passe quand on saute de page. On aurait tendance à continuer de faire le rendu des cellules sans se tracasser, un peu comme certains tableurs, mais pourquoi ne pas répéter votre en-tête de tableau ? Cela demande une gymnastique à l’image de notre en-tête/pied de page, même logique, un poil plus complexe.
export class KPdf {
cellPaddings!: Margins
tableHeaderInitFct?: HeaderPrototype
tableContentInitFct?: HeaderPrototype
constructor() {
this.setCellPaddings(0.5 * DIM_MM_POINTS)
}
// Table part
addTableHead(columns: TableColumns[]): KPdf {
if (this.tableHeaderInitFct) {
this.tableHeaderInitFct(this.doc)
}
// X, Y, fontSize and LineHeight already set by user
this.y += this.cellPaddings.top
columns.forEach((c) => {
const cellW = this.pageWidth * c.width
this.doc.text(
c.title,
this.x + (c.align === "right" ? cellW - this.cellPaddings.right : this.cellPaddings.left),
this.y,
{
baseline: "top",
align: c.align
}
)
this.x += cellW
})
this.y += this.lineHeight + this.cellPaddings.bottom
return this
}
addTableContent(columns: TableColumns[], data: any[], zebraColor: RGBColor = { r: 240, g: 240, b: 240 }): KPdf {
if (this.tableContentInitFct) {
this.tableContentInitFct(this.doc)
}
let zebra = true
data.forEach((d) => {
let maxCellHeight = 0
// Page break
if (this.y >= this.margins.top + this.pageHeight) {
this.newPage()
this.addTableHead(columns)
if (this.tableContentInitFct) {
this.tableContentInitFct(this.doc)
}
}
})
return this
}
...
Donc entre 2 lignes du contenu de votre tableau, on va créer une nouvelle page, remettre l’en-tête et le pied de page, puis on va rappeler l’en-tête de tableau, qui va rappeler le style définit dans une fonction spécifique (et externe), puis remettre notre configuration de corps de tableau et reprendre notre rendu.
Notez que pour le coup nous aurons un nouveau jeu de marges à tenir en compte : le padding des cellules.
Sources
J’ai créé un gist publique avec le code de la classe k-pdf au complet pour ceux que ça intéresse, merci de mentionner le github de l’auteur en cas d’usage ;). J’ai également ajouté un code illustrant l’usage de ce qui a été vu ici, nettoyé, cela va sans dire.
Conclusions
Comme dit, cet article visait à dégrossir le sujet tout en faisant un retour d’expériences. Il n’y a certes pas qu’une façon de faire et le code peut sûrement être amélioré, n’hésitez pas à m’en faire part.
Images
Sujet quelque peu embêtant, car la seule manière trouvée efficace est la base64, pointer vers un asset local (VueJs, Vite) vers addImage ne fonctionne pas.
Suite à l’article précédent j’ai voulu faire un tour de nettoyage et je me suis rendu compte qu’un ancien démon revenait à la charge. Nous avons divisé le code par domaine et contexte de rendu, propre et héritant d’un parent commun, et dans un service je mets le code commun à ce qui concerne Grid, ou Iso etc., de manière à isoler les calculs de l’usage selon le contexte.
Schéma avant fusion
Plus simple avec un schéma, voici la découpe avant fusion. Ce qui nous intéresse c’est la séparation 2D et Gl, puis la découpe par usage/type à savoir Sprite, Grid ou Iso, puis les regroupements de type IsoElement/GridElement, ainsi que des services relatifs aux couches.
On a une sorte de matrice à 3 dimensions en ce qui concerne cette idée. Sauf que programmer ça, en TypeScript, ben c’est pas très évident. En PHP j’aurai pu utiliser des Traits, il existe des mixins en javascript mais non merci, je vous laisse vous faire votre avis mais ce n’est pas à la hauteur. L’héritage multiple n’existe pas (cf mixin), du coup il faut savoir se renouveler et faire preuve d’audace, d’expérimentation et de refontes inévitables. C’est ce que j’ai dû faire, non sans mal.
J’étais parti pour déplacer les fonctions de rendu dans les services par couche (Grid/Iso) et de fusionner Grid2DElement avec GridGlElement, vu que leur différence réside dans le contexte de rendu (2D/Gl). Mais je me suis aperçu que bien que je gagnais en clarté à tout regrouper, on augmentait d’autre part la difficulté de ce même code et des approches. Bref, bien, mais pas bien.
Du coup revirement de situation et revenons sur nos pas de plusieurs mois quand on a justement décidé de diviser par contexte de rendu, quand les lumières sont arrivées (la version solutionnée). Revenons donc à cette idée non divisée et sans emmerder les services déjà très bons tels quels.
C’est la fusion !
Fusionner Grid2D et GridGl, Iso2D et IsoGl, ok, mais on oublie Sprite2D et SpriteGl qui héritent de SpriteElement, il faut commencer par le commencement. C’est donc une refonte jusqu’à Element pour répartir les morceaux des différentes classes Sprite*. Ainsi disparaissent Sprite2DElement et SpriteGlElement au profit d’une nouvelle classe SpriteElement toute équipée.
Quand on parle de fusion on parle bien entendu de gérer le contexte de rendu au sein même de la classe. Ceci peut paraître étrange et contre certains bons principes, mais ces morceaux de code partagent parfois jusqu’à 90% du code, ce qui va contre le principe DRY (Don’t Repeat Yourself) et comme j’ai envie de bisous (KISS : Keep It Stupid Simple), j’ai tout regroupé et cela ne m’a demandé que quelque if peu coûteux, ce qui est très important car on appelle ces bouts de code des centaines, des milliers de fois par seconde (selon complexité de votre projet).
Fusion de Sprite*Element
J’en profite pour illustrer le service de rendu Gl et montrer à partir d’où on le connecte. J’en affiche un peu plus mais ainsi on voit les 2 types de regroupement GridElement et IsoElement. Ne prêtez pas attention à GridBlock, vous le connaissez déjà.
Nous sommes bien parti, continuons. On crée une nouvelle classe GridElement et on met ce que contient Grid2D et GridGl, hop tout dedans et on essaye de faire coller les morceaux. Là où ça se corse c’est de bien segmenter les parties communes et spécifiques, puis quand on arrive à IsoElement c’est encore pire car nous sommes basé sur l’héritage donc on ne réécrit que ce qui a besoin de l’être et là on observe des couacs, des oublis pour la 2D vu qu’on s’est concentré sur Gl depuis les lumières. Par exemple la table en 2D ne fonctionne pas, juste en Gl.
Fusion terminée
Sur papier ça parait plus beau, naturel, élégant, [mettre ici tous les beaux mots que vous désirez]… Mais dans la pratique ça demande pas mal d’efforts, de compréhension, évidemment c’est pour un mieux !
C’est quand même un impact de 33 fichiers dans le projet et son POC de démo, 8 dans TARS même, ainsi que 8 suppressions et 2 ajouts. Ça c’est pour les fichiers, mais en terme de lignes de code, même si je n’ai pas de compteur à cet instant, on a effectué une réduction notable, donc plus facile à maintenir, de par le regroupement aussi.
Preuve que ça fonctionne toujours, même si la table n’est pas gérée encore correctement en 2D.
Garder 2D et Gl ?
Pourquoi garder les 2 ? Car il est très difficile de débuger en Gl, vous ne pouvez pas dessiner aisément un repère ou une trace sans sortir les chars d’assaut et beaucoup d’heures de dev alors qu’en 2D vous êtes libre de manipuler le rendu en direct et ce rapidement.
C’est pour cela que le POC (démo) n’utilise plus les lumières en 2D, le but pour moi ici étant un debug rapide sans ajouter des soucis de performances, qui plus est, connus.
De plus, maintenant que la fusion est faite, on pourrait revoir tout le workflow d’utilisation pour ne plus devoir faire (à l’usage) une scène 2D ou une scène Gl. ainsi en changeant juste le mode, toutes les classes personnelles seraient utilisables, ce qui serait un chouette gain de temps et d’effort. De plus les 2 fonctions ajoutées is2DContext/isGlContext permettent d’agir spécifiquement si besoin était.
Et le fameux ensuite ?
Ah ben oui, ensuite quoi ? Corriger le pourquoi de la table en 2D et tenter de régler un conflit Grid/Iso sur un calcul de positionnement.
Il faut absolument faire un POC purement Grid et non Iso, genre un Mario (S)NES ou Duke Nukem 1-2, un truc tout carré pour voir que les calculs sont bons, juste une grille décorée, pas plus.
Ensuite, mes fameuses particules lumineuses et le miroir :p !
Mais bon, comme d’hab on verra ce qui me stitch comme on dit. Je vais déjà de ce pas fusionner les branches du repo et repartir sur une base saine :).
Edit
Pour ne pas refaire un article juste pour ça, j’ai également fusionné les classes du POC (treasure, door, player), leur code était identique. 3 classes de moins sur les 6 initiales (3x2D et 3xGl). Une bonne chose de faites qui va nous simplifier la vie ultérieurement. Les scènes restent dissociées car différentes, la Gl, plus complète, gère la lumière par exemple, les fusionner ne donnerait rien d’intéressant une fois en release. Au moins le debug (2D) peut se faire sans gêner le résultat final (Gl). Nous voilà dans un état propre, quelques corrections de bugs ou de manques seraient à faire pour solidifier avant d’avancer plus.