Cela fait un moment maintenant que je travaille sur les valeurs polymorphiques, leur stockage et leur consultation. Cela se passe autant sur le convertisseur de données Comitards vers Folkopedia que sur l’API de consultation des données et son administration frontend. Ce que vous ne voyez pas, et de ce fait moi non plus avant de longues heures de boulot, c’est cette quantité d’efforts à fournir avant de faire un seul test. Et même si la théorie est sexy, sa mise en place est plutôt difficile car répartie ci et là. Voici donc un mot à ce sujet.
Vocabulaire
Une première chose est qu’il faut bien comprendre quelques notions définies.
| Entité | Est un ensemble, une structure, d’attributs (prédicat) et de leur valeurs (objet). (une personne, un objet, un truc, …) |
| Prédicat | Est un attribut représentant une partie de l’entité (un prénom d’une personne) |
| Type | Prédicat d’une entité permettant de connaître la nature de celle-ci |
| Modèle | Entité représentant la composition maximum d’une structure. Une personne peut avoir un prénom, un nom et une date de naissance (différent de l’instance de ce modèle qui peut n’être que partiel) |
| Présentateur | Illustre une partie d’une entité via une sélection de prédicats souhaités et/ou à exclure. C’est une couche de présentation. |
| Valeur | Contenu de l’objet d’un prédicat pour une entité. Si on encode votre prénom, la valeur est le prénom, qu’importe la structure porteuse autour. |
Entité et modèle
Un modèle est une entité indépendante qui contient la trinité nom/description/type (qui sera « modèle »), ainsi que d’autres prédicats selon la nature de l’entité à modéliser : une personne, un groupe, un chant, … Le modèle a pour vocation de pouvoir typer des entités et offrir un cadre définit lors des futurs encodage via formulaire généré sur base de ce modèle.
Une entité pourra être du type de ce modèle pour devenir alors une instance de ce modèle, ainsi on a le modèle représentant les possibles attributs que l’on peut encoder et des instances avec les infos que l’on a vraiment pour X (une personne, un groupe, un chant, …).
Ce qu’il faut retenir c’est la différence entre un modèle représentant une chose, et les instances de ce modèle, qui sont cette chose décrite unitairement. Ainsi on peut identifier une personne d’une autre mais comprendre que ces 2 entités sont des semblable par leur type.
Présentateur
Le présentateur est une représentation, un extrait d’une instance d’une entité sur base d’une liste de prédicats à afficher ou exclure. D’abord en se basant sur le modèle qui représente l’ensemble complet de prédicats disponibles, et ensuite sur ce que l’instance a réellement d’encodé.
Si vous avez une personne ayant un prénom, un nom, une date de naissance et d’autres informations, que le présentateur limite au nom et prénom, le résultat ne contiendra qu’au maximum le nom et prénom. Au maximum car si la personne n’a pas de nom mais qu’un prénom et d’autres informations, seul le prénom ressortira.
Le présentateur est composé de 2 prédicats majeurs, permettant d’appliquer un comportement, d’inclusion et/ou d’exclusion. On veut inclure quelques prédicats du modèle (tous si on ne précise pas ce prédicat), et/ou on veut exclure des prédicats basé sur ce qui aura finalement été retenu. Par cette mécanique on peut utiliser un même présentateur pour 2 modèles similaire mais potentiellement différents.
Le fait d’avoir regroupé sous 2 prédicats (inclusion/exclusion) les prédicats que l’on souhaite voir ou non, permet de soustraire la trinité dont on a parlé plus haut, à savoir nom/description/type qui font partie de l’identité d’une entité quelconque, hors une entité (instance) n’a pas forcément cette partie système encodée, si on les sélectionne avec le reste comme avant on se retrouve avec un tas de données parasites vides non désirées. Cette séparation montre bien la notion technique et métier.
Il faut bien comprendre qu’un présentateur limite les prédicats exposés (couche de présentation de l’information) et n’est pas un modèle qui, lui, contient tous les possibles encodables.
Valeur
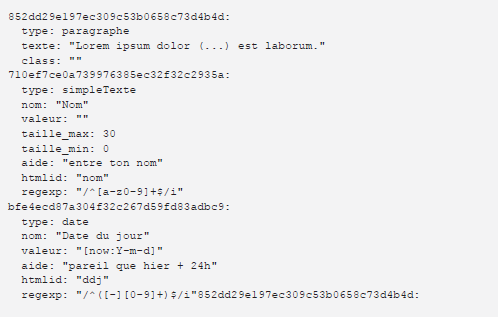
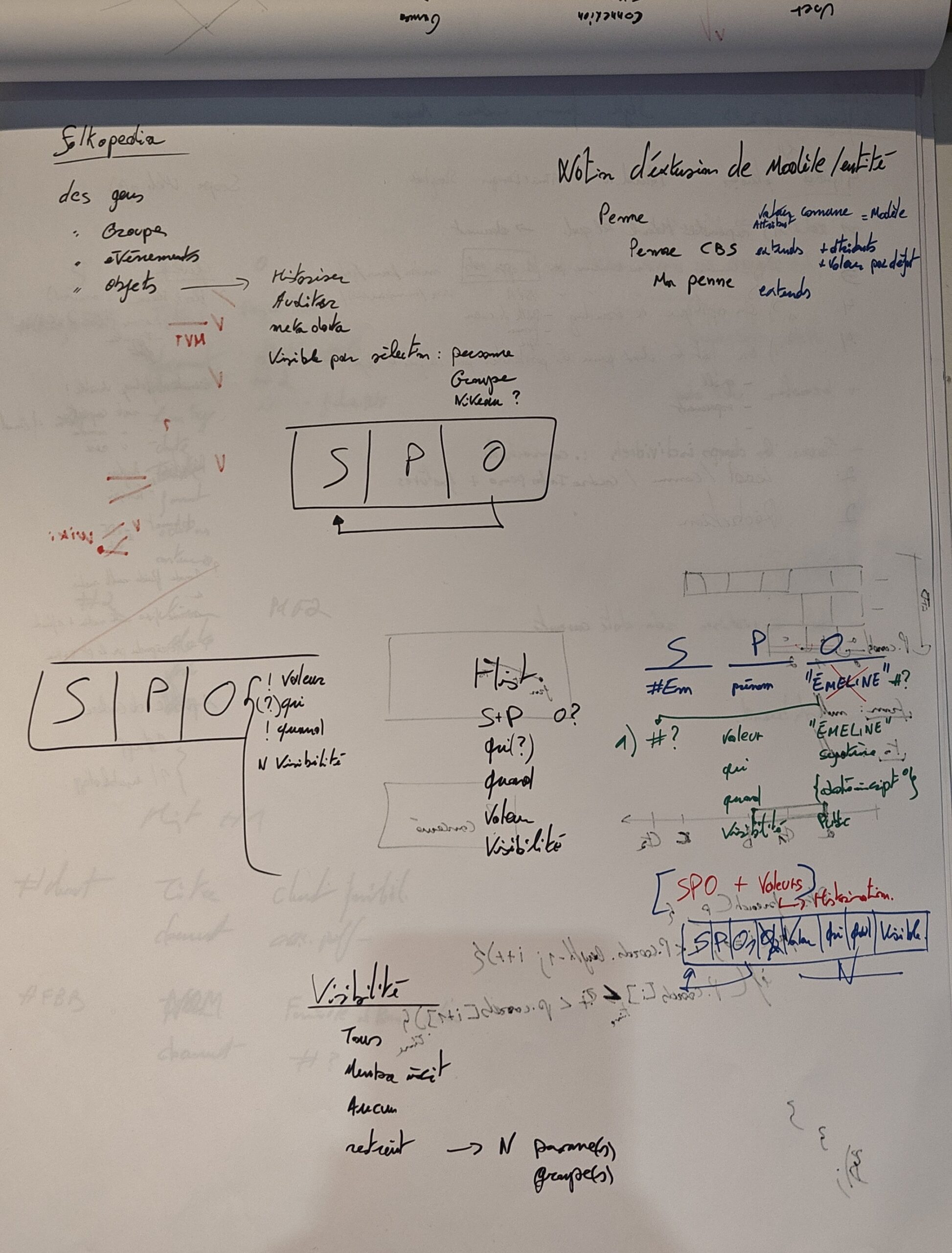
Cela pourrait sembler trivial, de dire que la valeur c’est la valeur du prédicat, donc le contenu de la 3ème colonne du SPO, mais évidemment ce n’est pas aussi simple. Une valeur peut être complexe et contenir des métadonnées (ordre de l’information, date de modification, …), ce qui se traduit par une encapsulation de cette valeur au sein d’une nouvelle entité. Si on prend l’objet (3ème colonne) on aura un identifiant d’entité et non plus la valeur telle quelle, il faut refaire un tour et inspecter cette entité en cherchant le prédicat de contenu pour enfin avoir la valeur souhaitée. Et ce n’est pas tout, si la valeur a été modifiée, il faudra trouver la bonne valeur parmi une liste (basé sur la date par exemple).
Une valeur est donc un objet complexe, que je défini comme polymorphique. Celui qui fourni l’information finale doit déduire et transmettre un résultat utilisable. Ce qui concerne également l’encodage et dans mon cas actuel : le convertisseur (la moulinette).
On peut également ajouter le fait que certaines valeurs ne sont pas disponible dans l’ontologie telle quelle mais doivent être stockées en dehors pour des raisons de taille, format, nature, … Ce qui demande une interprétation additionnelle.
Encodage et présentation
Encodage
Afin d’illustrer les théories en vigueur actuellement, voici un cheminement pour une information, actuellement je me base sur les types de groupe folklorique.
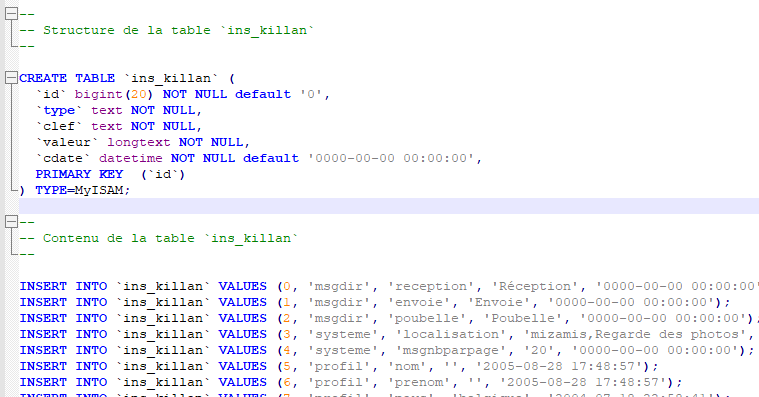
Un groupe folklorique est une représentation simpliste du type de groupe pour les qualifier. Ceux-ci sont représentés par un nom et des initiales, par exemple « Comité de Baptême » aura les initiales « C.B. », agrémenté d’un id en base de donnée vous avez ainsi la structure à porter vers l’ontologie.
La première chose que notre ontologie a besoin avant de pouvoir encoder les données est de connaitre la structure, nous allons donc encoder un modèle de ce « type de groupe », je vous passe les dépendances techniques nécessaires. Ce modèle est donc une entité ayant des prédicats spécifiques pour représenter les initiales et le nom du type de groupe, l’id, quant à lui, ne sera pas porté et fera place à un nouvel identifiant propre à la nouvelle structure technique, cependant il sera conservé pendant le traitement de conversion total dans un store afin de faire la correspondance entre ancien et nouveau système.
On a donc un modèle, qui est une entité composée de prédicats structurels (la trinité) nom/description/type, nous indiquant qu’il s’agit du modèle type de groupe avec une description similaire à son nom (aspect technique auto généré) et un type qui sera « modèle », car si on veut encoder des entités du type « type de groupe », cette même description est un modèle en soit. À cela s’ajoute les prédicats propre au modèle : initiales et nom (le nom repris en base de l’entité (trinité) et le nom du type de groupe sont 2 prédicats distinct (actuellement car la structure pourrait être amenée à évoluer)).
Tant qu’on est dans la préparation technique, et maintenant que le modèle existe, nous pouvons penser à la présentation des instances du type « type de groupe ». Là encore nous allons créer une entité avec sa trinité nom/description/type, nous indiquant qu’il est un présentateur pour un type de groupe, et à cela nous allons lui indiquer les prédicats que l’on souhaite conserver lors d’échange de données (pensez à ce que l’on souhaite partager ou afficher). Ces prédicats souhaités vont se retrouvé dans notre cas dans le prédicat d’inclusion, c’est à dire que l’on précise les 2 prédicats que l’on souhaite conserver par rapport au modèle, ici : initiales et nom du type de groupe. Il est à noter que ces prédicats inclus sont ordonnés
Il faut faire connaitre au modèle « type de groupe » qu’il y a un présentateur consacré et donc nous allons ajouter un prédicat au modèle de type présentateur, référençant le sujet du présentateur. En gros, on les lie en partant du modèle.
Maintenant que nous avons cette partie technique nous pouvons convertir nos données originales vers l’ontologie une à une. En très résumé :
- on chope un type de groupe,
- on reprend ses données,
- on crée une nouvelle entité typé du modèle « type de groupe » que l’on va nommer selon les données reprises, avec une description similaire,
- Pour chaque champs spécifique, on l’ajoute à cette nouvelle entité,
- On sauve et c’est fini, on passe au suivant
Jusque là c’est assez simple, nous voilà avec un modèle, un présentateur et des instances de données représentant des types de groupe.
Présentation
Maintenant on nous demande d’envoyer ces données vers le front (le site qui va afficher les données à l’écran). Et non, ce n’est pas simplement d’envoyer les instances créées ^^.
Dans mon cas, on demande d’envoyer toutes les instances d’un modèle, dans ce cas-ci, les types de groupe. Pour ce faire il faut 2 choses : les données et leur structure, mais attention, uniquement ce que l’on veut afficher.
Rappelez-vous que ne pas tout envoyer allège la communication et protège les données qui ne devraient pas transiter.
Il n’y a pas vraiment d’ordre ici, c’est exécuté en 2 appels distincts, du coup je vais vous parler de la structure puis des données.
Structure
On nous demande la structure filtrée pour une entité, du coup d’abord on va faire des vérifications d’usages : est-ce que l’entité ciblée existe et est-ce qu’elle a un présentateur sinon son père ou son père avant lui jusqu’à remonter tout en haut.
Dans notre cas on a un présentateur donc il faut le résoudre :
- prendre la définition du présentateur (on part ici du principe qu’il n’en a qu’un, je vous vois venir à raison).
- est-ce qu’il y a des prédicats à inclure ? Si « non » alors on va chercher le modèle et on prend tout, et si « oui » alors on a notre liste de départ directement.
- est-ce qu’il y a des prédicats à exclure ? On aurait pu prendre tout du modèle et exclure la trinité, dans notre cas il n’y a rien à exclure.
- renvoyer la liste finale
Ça a l’air simple hein oui ?
Notez que les prédicats peuvent avoir des indications de type de donnée (texte, date, valeur financière, e-mail), on peut agrémenter la structure de ces infos afin d’améliorer l’affichage (ce qui n’est pas encore le cas mais prévu).
Données
On va demander au système de nous donner toutes les entités du type du modèle cherché. Vu notre structure de données on se limite au prédicat type pour n’avoir qu’un seul résultat par entité et permettre de le filtrer directement (aspect technique pratique).
On pourrait dire qu’il suffit alors de boucler sur chaque résultat, chercher les données de chaque et tout envoyer. Et c’est vrai que ça fonctionne car le front génère un tableau sur base de la structure reçues et seul les champs autorisés sont affichés si existant. Sauf que, envoyer tout n’est pas la meilleure chose à faire; et que vous oubliez la notion de valeur de ces champs.
Les données stockées peuvent être une référence vers une autre entité (prédicat ou valeur) ou être la valeur finale. Ce « ou » est le problème à résoudre avant envoie. Le front s’en moque, il veut une donnée exploitable (et il a raison). Il nous faudra déterminer la nature de la donnée que l’on a en objet et si ça a l’air d’être une référence à une autre entité alors c’est parti pour la grosse mécanique.
Il nous faudra chercher si cette référence existe, de quelle nature elle est pour l’interpréter, car on ne gère pas un prédicat comme on gère une valeur par exemple. Puis si on peut fournir assez d’infos pour que le front puisse mieux se démerder c’est encore mieux (exemple d’avoir un label sans sa référence nous empêche de construire un lien vers elle).
Ici je résume fort, sinon je vais devoir vous expliquer les dizaines de lignes de codes pour y parvenir ^^. Rappelez-vous juste que chaque question à l’ontologie est une requête ^^, et dans le cas d’une résolution de valeur il y en aura jusqu’à 2 par prédicat à afficher, bref ça nous donne un : n · (2 + [0,2]). Vivement améliorer ça ahah.
Nous ne sommes pas encore dans une solution optimisée, c’est encore de la recherche et développement, comme souvent dans mes articles et surtout sur le sujet de cette ontologie.
Supplément front
Évidemment les données ne s’affichent pas par magie, wooop, mais bien par un traitement. On va déjà passer la structure json actuellement nécessaire mais en passe de changer pour intégrer l’ordre dont on parlait plus haut concernant la structure.
Quand on souhaite afficher notre donnée, il faut également savoir de quelle nature elle est, car si c’est une référence on peut créer un lien et permettre d’aller vers cette entité ciblée, promenons-nous ! Et si c’est du texte l’afficher et, plus tard, tenir compte du format selon le prédicat.
Pour créer le lien j’ai mis à jour un code de 2022 concernant les composants de cellule en Angular, mis à jour à la sauce Signal, c’est top !
Mot de la fin
Et voilà c’est « déjà » fini ! :p Merci d’avoir joué les canards en plastique pour cette « rédaction documentaire d’un instant T en plein développement prise de tête pas terminé ».